






























































Object detection now plays a very important role in our lives, right from face detection and unlocking a smartphone to detecting bombs in places where people congregate, like airports, bus terminals, railway stations, etc. Such advanced features are a result of the application of machine learning and artificial intelligence. This article discovers how TensorFlow, a machine learning library, can be used to identify objects.
Security and surveillance cameras are very widely used across organisations, so it is important to enhance their effectiveness while saving manpower costs and preventing human errors. In such scenarios, image/video analytics plays a very important role in performing real-time event detection, post-event analysis, and the extraction of statistical and operational data from the videos. Video analytics (VA) is the general analysis of video images to recognise unusual or potentially dangerous behaviour and events in real-time. It can perform three major tasks — provide information, offer assistance, and generate alerts.
Video analytics is widely used for suspicious object detection in schools, in the banking and financial sector, and in critical infrastructure protection. It is also used at heritage sites, commercial spaces, offices, government buildings, factories, airports, railway/metro stations, busy traffic intersections, stadiums, etc. Video analytics is used for monitoring people and vehicle flows. It can spot and prevent the crossing of the speed threshold and vehicular movement in the wrong direction. Other capabilities include crowd counting, incident detection, licence plate recognition, safety alerts, people/object recognition, post-event analysis, lost object detection, etc.
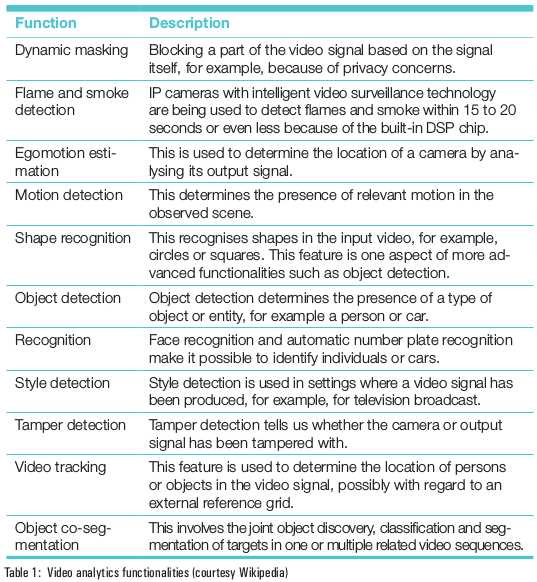 Wikipedia defines many functional applications of video analytics, which are listed in Table 1.
Wikipedia defines many functional applications of video analytics, which are listed in Table 1.
One of the major applications of video analytics is object identification, which is the process of identifying objects within images or videos. It is based on the concept that each object has unique features. These features help to classify the objects into different classes. Identification can be done either by using the machine learning (ML) approach or the deep learning (DL) method.
In the machine learning method, first the features are identified and then support vector techniques (SVM) are used for classification. Deep learning methods are based on convolution neural networks (CNN), which is a kind of neural network that has an input layer, output layer and multiple hidden layers. It uses mathematical model convolution to pass on the result to various successive layers. In this article, I will explain the process of object identification using TensorFlow, with a focus on deep learning methods.
TensorFlow is an open source software library for numerical computation using data flow graphs. The graph nodes represent mathematical operations, while the graph edges represent the multi-dimensional data arrays (tensors) that flow between them. This flexible architecture enables users to deploy computation to one or more CPUs or GPUs in a desktop, server, or mobile device without rewriting code. TensorFlow is an end-to-end open source platform for machine learning. It has a comprehensive, flexible ecosystem of tools, libraries and community resources that lets researchers push the limits of the state-of-art in ML, and helps developers easily build and deploy ML-powered applications.
Deep learning is a part of machine learning in artificial intelligence. It works in a manner that is similar to how the human brain works to process data and to create patterns, which are used for decision making. Deep learning allows computational models to learn representation of data with multiple levels of abstraction. These models are composed of multiple processing layers. Deep learning methods have proved to be very effective in speech recognition, visual object recognition, object detection and many other domains.
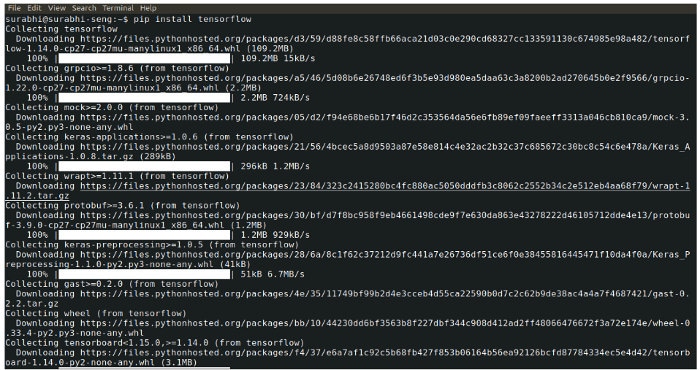
In the subsequent section, I will discuss a very basic method of object identification using TensorFlow. This experiment has been carried on Ubuntu 18.04.3 with Python, TensorFlow and Protobuf 3.9.
The following steps can be used for object detection using TensorFlow. This will identify objects kept in the test_images folder of the TensorFlow directory.
- Set up the environment; install TensorFlow and the Tensor GPU using the pip command. Pip is a tool for installing and managing Python packages. Pip 19 or later is required for TensorFlow 2.0.
python -m pip install tensorflow python -m pip install tensorflow-gpu
Install the required object detection libraries, as follows:
# static compiler pip install --user Cython # backport of the contextlib module to earlier Python versions. pip install --user contextlib2 #python imaging library pip install --user pillow # For processing HTML and xml in python pip install --user lxml # open-source web application pip install --user jupyter #Plotting library for python pip install --user matplotlib
Download Protocol Buffers (Protobuf). Run the following command from the tensorflow/models/research/ folder:
protoc object_detection/protos/*.proto --python_out=.
Or you may compile each file in the protos folder, individually; for example:
protoc object_detection/protos/anchor_generator.proto --python_out=.
Add libraries to PYTHONPATH. Run the following command from tensorflow/models/research/:
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
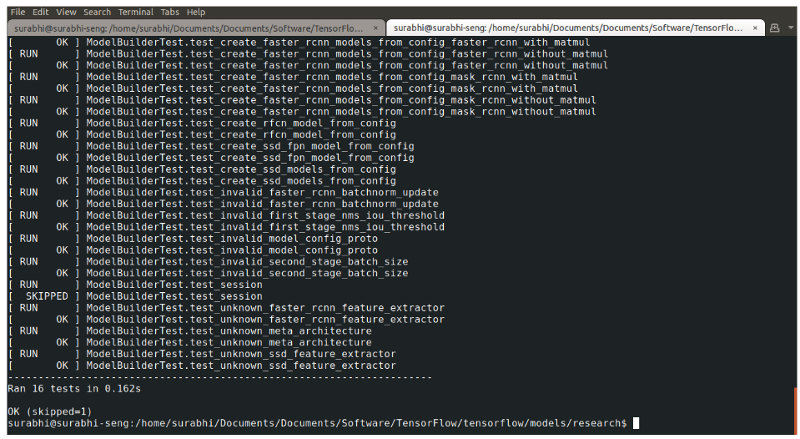
You can test the installation of the TensorFlow Object Detection API by running the following command:
python object_detection/builders/model_builder_test.py
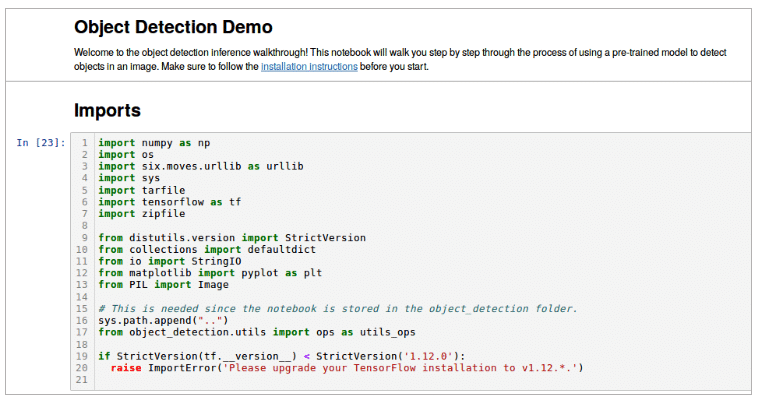
Run the object detection tutorial using the following command from the tensorflow/models/research/object_detection directory:
jupyter-notebook object_detection_tutorial.ipynb
It will run in the browser and will look like what’s shown in Figure 3.
From the cell, select Run all, which will run and generate the output at the end of the page.

You will see the detection of all the images from the test_images directory (tensorflow/models/research/object_detection/test_images). If you want to test the code with your images, just add the path to the images, to the line TEST_IMAGE_PATHS.
for image_path in TEST_IMAGE_PATHS: image = Image.open(image_path)
If you want to add more images, you can change the number of images in the range, as follows:
PATH_TO_TEST_IMAGES_DIR = ‘test_images’
TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, ‘image{}.jpg’.format(i)) for i in range(1, 5) ]
# Size, in inches, of the output images.
IMAGE_SIZE = (12, 8)
The final object identification will be shown as an output of images. The objects will be detected with labels, and the percentage/score of that object will be similar to the training set.
This very basic example can be followed for simple object identification. Moving objects/videos can also be tagged and identified in a similar manner, with a slight modification of code and addition of libraries like OpenCV, etc.



















{kind=link}