






























































According to the H2O official website, “H2O.ai is the creator of the leading open source machine learning and artificial intelligence platform trusted by hundreds of thousands of data scientists, driving value in over 18,000 enterprises globally. Our vision is to democratise intelligence for everyone with our award winning ‘AI to do AI’ data science platforms.”
H2O is a machine learning platform with linear scalability, is distributed and a leading open source enterprise. H2O strengthens the widely used machine learning and statistical algorithms comprising deep learning, generalised linear models and gradient boosted machines. The leading AutoML functionality in H2O automates all the hyper boundaries and algorithms to produce the best supermodel. The platform is extremely popular in both the R and Python communities and globally, it is used by over 18,000 consortiums.
The essential traits of H2O
Listed below are some of the key features of this platform.
Superior algorithms: The algorithms have evolved from both supervised and unsupervised approaches and are for distributed computing. They cover GLRM, Word2Vec, Random Forest, XGBoost, GBM, GLM, and many more.
The approach from Python, R and Flow: Programming languages like Python, R and other models are used to build H2O. The interactive graphical user interface doesn’t need any coding.
AutoML (New): H2O AutoML automates the training and tuning of many machine learning models within a prescribed user time limit.
In-memory and distributed processing: In-memory processing manages fast serialisation to support massive data sets between clusters and nodes. Distributed processing on big data accelerates to 100x quicker with fine-grain parallelism, empowering ideal productivity without presenting degradation in computational precision.
Simple deployment: Easy-to-locate plain old Java objects and model objects, that are optimised to send models for quick and exact scoring in any condition, including vast models.

H2O software
Programming languages: The H2O software has a programming interface language like Scala, R (3.0.0 or later), Java (6 or later) and Python (2.7.x, 3.5.x), etc.
Operating systems: The H2O software conventionally runs on operating systems like Mac OS X (10.9 or later), Linux (Ubuntu 12.04, RHEL/CentOS 6 or later) and Microsoft Windows (7 or later).
Graphical user interface (GUI) and browsers: Its GUI is in sync with browsers like Internet Explorer (IE10), Firefox, Chrome and Safari.
Architecture
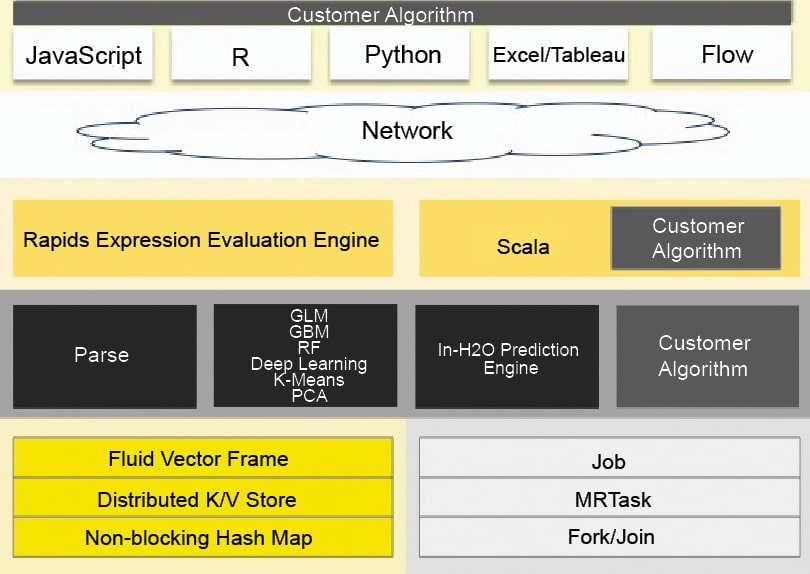
The H2O software stack: Figure 1 represents the dissimilar elements that work together to form the H2O software stack. Within the network cloud, the figure is divided into two segments — the top and bottom segments. The dissimilar REST API clients that exist for H2O are shown in the top segment. The dissimilar elements that run within a H2O JVM process are represented in the bottom segment. Each surface in the other segment of the diagram represents the constant colour but shows the user interface customer algorithm code as grey.
REST API clients: Through a socket connection, all REST API clients communicate with H2O.
(i) JavaScript: JavaScript uses the benchmark REST API, and the implanted H2O Web user interface is composed in JavaScript.
(ii) R: Users can compose their own R operations that run on H2O with ‘ddply’ or ‘apply’. An R script uses the library package H2O R [‘library (h2o)’].
(iii) Python: An H2O client API for Python has been designed. Python scripts directly use the REST API.
(iv) Excel: The H2O Microsoft Excel worksheet permits the user to “…import large data sets into H2O and run calculations like GLM (Generalised Linear Model) straight from Excel.”
(v) Tableau: By using conceptualisation in Tableau, users can pull outcomes from H2O.
(vi) Flow: Flow is the scratch pad style Web UI for H2O.
(a) JVM components: H2O software comprises a large number of nodes and each one consists of a single JVM operation. The JVM operation is divided into three branches — core infrastructure, language and algorithms.
The evaluation expression engine for R and the Shalala Scala layer dwell under the language layer. For the customer front-end, the R evaluation layer goes about as a captive to the R Rest. Anyway, the Scala layer is the superior resident using which we can compose unique projects and algorithms of H2O.
At this layer, algorithms for H2O are automatically provided. Algorithms for significant data sets, math and machine learning algorithms for prediction and the scoring engine as well as GLM can be parsed. At this level, the core layer controls memory, the CPU and resource management.
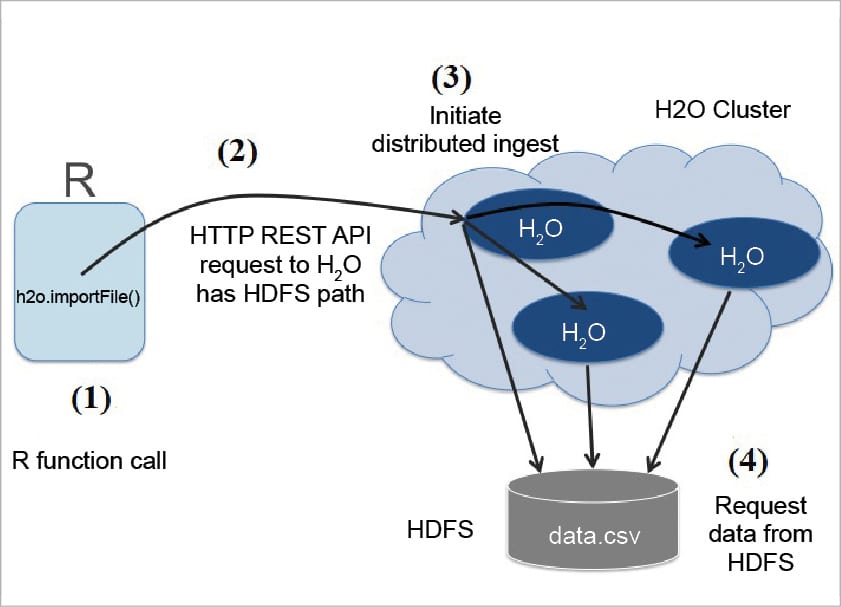
(b) How H2O interacts with Python and R: The R script is a REST API user for the H2O cluster. H2O allows the R client to charge an H2O cluster from the R script in which the data does not all flow through R.
(i) How H2O ingests data to R scripts: The following three stages show how an R plan tells an H2O cluster to study information from HDFS into a distributed H2O frame.
Step 1: The R client calls the importFile function.
Step 2: The R client advises the group to read the information. In Figure 3, the arrows show the control information.
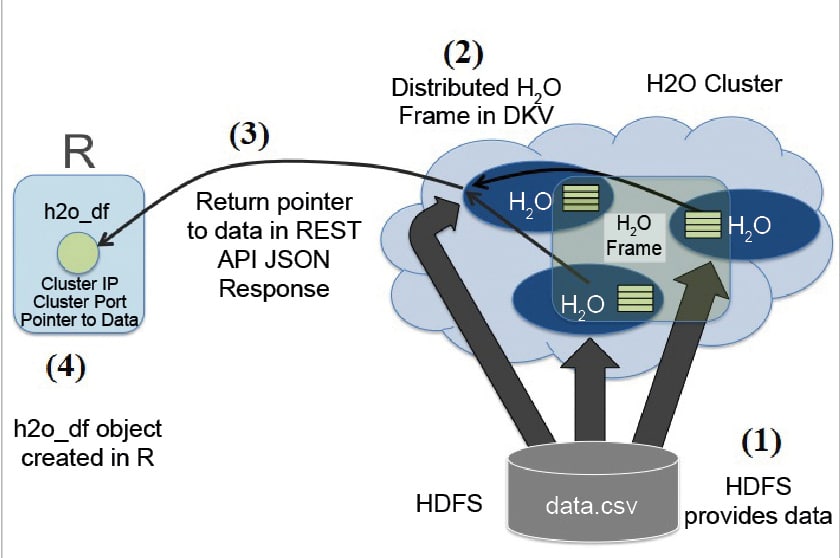
Step 3: The information comes back from HDFS into a disseminated H2O frame. The thin arrows in Figure 4 represent the control information. The thick arrows represent the information entity that recurs from HDFS. The distributed H2O frame cluster memory stores the block of data.
(ii) How R scripts call H2O GLM: Let’s use the same H2O application instance created for the R example. It is interesting that you can actually share models created in R and vice-versa. After an H2O application is running, using the R H2O library, you can connect, load data, and train the following GLM:
dat <- ... model <- h2o.glm(y=”y”, x=c(“x1”,”x2”,”x3”), training_frame=dat)
(iii) How R expressions are sent to H2O for evaluation: With the S3 object, the class H2O data frame is illustrated by R expressions. The S3 object has an id characteristic which is a reference to the big data object inside H2O.
An introduction to H2O AutoML
H2O AutoML automates the training and tuning of many machine learning process models within a prescribed client enumerated time limit. In the case of Stacked Group (Ensembles), one form is based on all formerly instructed models and the other one is the foremost model of every family – it will be mechanically instructed on a group of individual models to build extremely anticipated ensemble models which, in major instances, will be the best functioning models in the AutoML Leaderboard.
The AutoML interface: This AutoML interface has been designed to create parameters that are manageable so that all that the client requires is to spot its data set, state the time restrictions and identify the response standard.
In both the R and Python API, AutoML utilises the same data related arguments:
x, y, training_frame, validation_frame
..where,
- To eliminate predictor columns from data sets, the user will need to specify the x argument.
- The response column is represented by the name or index called the y argument. This is required.
- The training set is the training_frame. This is required.
- To prematurely stop the training process of the independent models in AutoML, run the validation_frame, which is used optionally.
- To specify the particular data frame to grade models, the leaderboard_frame argument is used, and this frame will not be used for anything besides the leaderboard.
- The user can state the following: max_runtime_secs, normal to 600 seconds, to control how extensively the AutoML will run.
AutoML output: In binary grouping problems, the metric is AUC; and in multiple grouping problems, the metric is mean per-class error. In the regression problem, the standard sort measure is Root Mean Square Error (RMSE). The AutoML models were instructed in the leaderboard process, and are classified by a typical metric deployed on the problem type.
NLP with H2O
This segment focuses on a pioneering algorithm — H2O’s Word2Vec. This instructs the schematic neural network model to assimilate vector description of words. These vector descriptions are expected to capture the sense of the words.
Supervised learning with text data using Word2Vec: This process is split up into three phases.
Phase 1: The system will instruct a prototype by using numerical predictor variables. For example, it learns vector representations of words by analysing a large text corpus. Word embedding is nothing but mapping of words to vectors from a high dimensional space (100-1000). Examples of text sources are Google News, Wikipedia, tweets, etc.
Phases 2 and 3: The system will instruct a prototype by using text columns. And the text columns in this information are the product analysis and synopsis.
Embeddings capture meanings of the word: Semantically similar words are close to each other. H2O can be used to find synonyms and analogies. For example: Man is to woman as king is to ??? (queen).
Vec(king) – Vec(man) + Vec(woman) = Vec(queen)
To control our text columns, the system will instruct a Word2Vec prototype to transform text into numeric vectors.
H2O security
H2O contains security highlights proposed for deployment inside a secure data centre (see Table 1). File security in H2O: H2O is a typical user prototype. To ensure user information safety for H2O, there’s nothing to be done specifically. HDFS permissions and the operating system just work well to ensure security.
File security in H2O: H2O is a typical user prototype. To ensure user information safety for H2O, there’s nothing to be done specifically. HDFS permissions and the operating system just work well to ensure security.
H2O Flow
H2O is an interactive Web based framework which allows users to merge text, plots, code execution, mathematics and rich media in a single document.
By using H2O Flow, one can present, annotate, rerun and share one’s workflow. It also allows users to build prototypes, to import files, and frequently improve them. Based on user prototypes, one can make projections and join rich text to generate vignettes of your work — all within Flow’s browser based domain.
With a modern graphical interaction, Flow’s hybrid user interface seamlessly merges command line computing. Rather than showing the outcome as plain text, Flow delivers a point and click user interaction for each H2O performance. It allows users to approach any H2O object by means of tabular information.
H2O is an open source predictive analytics program and also provides heterogeneous conventional analytics mechanisms. It enables the collaboration of exceptional mathematics and giant, production-grade parallel processing with unequalled ease of use. Data scientists and business analysts prefer H2O for scalable and fast machine learning.
















