





























































As of today, Kubernetes is the last word in production grade container orchestration. It is an open source system for automating deployment, scaling and management of containerised applications. This article delivers the key concepts in Kubernetes to our readers.
Kubernetes is a powerful open source system, initially developed by Google, to manage containerised applications in a cluster environment. Kubernetes was launched in 2014, after more than a decade of experience of running production workloads at Google with Google’s internal container cluster managers, Borg and Omega. It aims to provide better ways of managing related, distributed components and services across varied infrastructure. Kubernetes has now become the de facto standard for deploying containerised applications at scale in private, public and hybrid cloud environments. The largest public cloud platforms such as AWS, Google Cloud, Azure, IBM Cloud and Oracle Cloud now provide managed services for Kubernetes.
Key definitions and concepts
Kubernetes, at a basic level, is a system for running and coordinating containerised applications across a cluster of machines. It is a platform designed to completely manage the life cycle of containerised applications and services using methods that provide predictability, scalability and high availability. It has made the adoption of emerging software architectural patterns such as microservices, serverless functions, service mesh and event-driven applications much easier, and paved the path towards the entire cloud-native ecosystem. Most importantly, its cloud-agnostic design enables containerised applications to run on any platform without any changes to the application code.
Container: This is the smallest unit in the Kubernetes world. The main goal of Kubernetes is to manage, deploy and, to a certain extent, monitor containers. Kubernetes management is not limited to Docker management.
Node: A node is the host on which the containers run.
Pod: This is a management unit in Kubernetes comprising one or more containers. Each pod has its own unique IP address and storage name spaces. All containers share these networking and storage resources. One of the characteristics is that pods are mortal. This means that when a pod is deleted, it is gone for good. A YAML (Yet Another Markup Language) file is used to define a pod. Here is a sample copy of a YAML file representing a pod:
apiVersion: v1 kind: Pod metadata: name: nginx-pod labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9
Deployment: This is a way to handle high availability (HA) in Kubernetes. A pod by itself is mortal but with a deployment, Kubernetes can make sure that the number of pods that a user specifies is always up and running in the system. A deployment specifies how many instances of a pod will run. A YAML file is used to define a deployment. Here is an example of a YAML file representing a deployment:
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: nginx-deployment spec: replicas: 2 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9
Service: According to the official Kubernetes website, “A Kubernetes service is an abstraction which defines a logical set of pods and a policy by which to access them – sometimes called a microservice.”
Cluster IP is internal to Kubernetes, and the NodePorts are the published IP addresses for external users to access the services. Routes to services are based on labels. As with pods and deployments, a service is also defined by a YAML file.
Declarative: This is an operation based on YAML files. Kubernetes depends on a YAML file to check if the desired pod, deployment or service is running as defined. We can execute kubectl apply a hundred times with no undesirable or unexpected outcome. Kubernetes just checks if the system is running according to the desired state as defined in the YAML file.
Kubernetes architecture
Kubernetes can be visualised as a system built in layers, with each higher layer abstracting the complexity found in the lower levels. At its base, Kubernetes brings together individual physical or virtual machines into a cluster using a shared network to communicate between each server. This cluster is the physical platform where all Kubernetes components, capabilities and workloads are configured.
At a very high level, Kubernetes provides a set of dynamically scalable hosts for running workloads using containers, and it uses a set of management hosts called masters that provide an API for managing the entire container infrastructure. This server acts as a gateway and brain for the cluster. Task of the master server is to check the health of the other servers, deciding how to split and assign work and orchestrate communication between other components. The master server acts as the key point of contact with the cluster and is responsible for most of the centralised logic Kubernetes provides.
The remaining machines in the cluster are known as nodes, which are in charge of accepting and running the workloads. To help with isolation, management and flexibility, Kubernetes runs applications and services in containers; so each node needs to be equipped with a container runtime. The node receives work instructions from the master server and creates or destroys containers accordingly, adjusting networking rules to route and forward traffic appropriately.
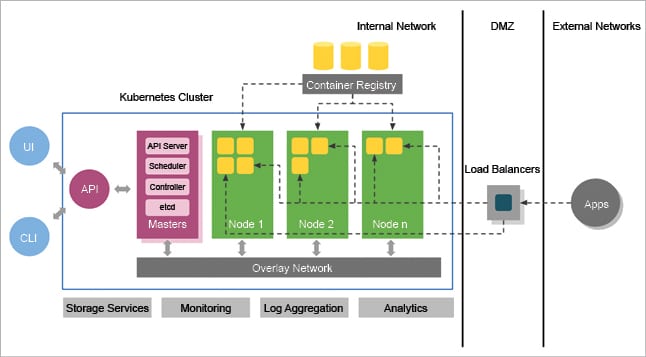
Kubernetes components
Master server components: The master server components are described below.
etcd: Kubernetes uses etcd to store configuration data that can be accessed by each of the nodes in the cluster. This can be used for service discovery and can help components configure or reconfigure themselves according to up-to-date information.
Kube-apiserver: This is the main management point of the entire cluster as it allows a user to configure Kubernetes’ workloads and organisational units. It is also responsible for making sure that the etcd store and the service details of deployed containers are in agreement. It acts as the bridge between various components to maintain cluster health and disseminate information and commands.
Kube-controller-manager: This is a general service that performs many tasks. Mainly, it manages different controllers that regulate the state of the cluster, manages workload life cycles, and performs routine tasks.
Kube-scheduler: The task of the scheduler is to assign workloads to the nodes.
Cloud-controller-manager: This acts as the glue that allows Kubernetes to interact between providers with different capabilities, features and APIs, while maintaining comparatively generic constructs internally.
Node server components: In Kubernetes, servers that perform work by running containers are known as nodes.
Container runtime: This is responsible for starting and managing containers and applications encapsulated in a relatively isolated but lightweight operating environment.
Kubelet: The main contact point for each node with the cluster group is a small service called Kubelet. This service is responsible for relaying information to and from the control plane services, as well as interacting with the etcd store to read configuration details or write new values.
Kube-proxy: To run individual host subnetting and make services accessible to other components, a proxy service called Kube-proxy is used. It runs on each and every node.
Kubernetes has been launched after more than a decade of practice on running containerised applications at scale at Google. It has already been adopted by the largest public cloud vendors and technology providers, and is being embraced by even more software vendors and enterprises. It has even led to the inception of the Cloud Native Computing Foundation (CNCF) in 2015, was the first project to graduate under CNCF, and started streamlining the container ecosystem together with other container-related projects such as CNI, Containerd, Envoy, Fluentd, gRPC, Jagger, Linkerd, Prometheus, rkt and Vitess. Its main attractions are its perfect design, collaborations with industry leaders, its open source type, and forever being open to ideas and contributions.

















{kind=link}