






























































This article talks about MLDB in relation to the cloud and Docker. It details the prominent tools for ML, describes the features of MLDB, its installation on different platforms, and the various algorithms supported by it.
Machine learning and predictive analytics are key areas of research in multiple domains including bioinformatics, computational anatomy, natural language processing, speech recognition, etc.
Machine learning is used to train the software or hardware applications based on specific models for rule mining, prediction and knowledge discovery. Data scientists and analysts implement different supervised or unsupervised approaches to get accuracy and performance from raw datasets.
Machine learning (ML) and artificial intelligence (AI) are very closely related, but these terms have different perspectives. Artificial intelligence (AI) is the concept by which machines perform tasks similar to human beings, and we call such machines ‘smart’.
Machine learning is the recent advanced application area of AI in which machines learn by themselves based on dynamic inputs. Machine learning based implementations are more accurate and have high optimisation.
The prominent tools for machine learning and deep learning are MLDB, Keras, Edward, Lime, Apache Singa and Shogun. The details for each can be found on their respective websites.
Machine Learning Database (MLDB) is a powerful and high performance database system specifically developed for machine learning, knowledge discovery and predictive analytics. MLDB is FOSS and is compatible with assorted platforms. It uses the RESTful API for the storage of data, exploring the data using Structured Query Language (SQL) and, finally, it trains machine learning models.
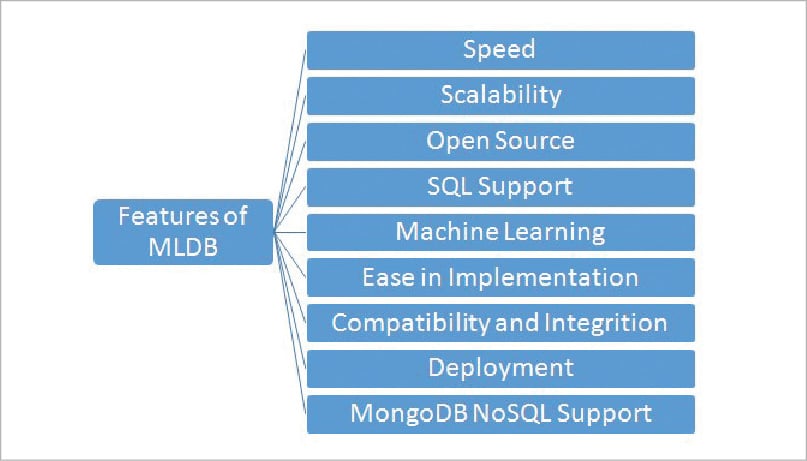
The following are the key features of MLDB that suit a range of applications.
Speed: The training, modelling and discovery process in MLDB is highly performance-aware. It has huge processing power compared to H2O, Scikit-Learn or Spark MLib, which are prominent machine learning libraries.
Scalability: MLDB supports vertical scaling with higher efficiency, so all memory modules as well as cores can be used simultaneously without any issues of delay or performance.
Free and open source: The community edition of MLDB is available and distributed on a powerful repository and hosting of GitHub (https://github.com/mldbai/mldb).
SQL support: This makes MLDB very user-friendly along with the support for Big Data processing. MLDB can process, train and make predictions using database tables that have millions of columns, with concurrent processing and no compromise on integrity.
Machine learning: MLDB is developed for high performance machine learning applications and models. It has support for deep learning with the graphs of TensorFlow that make it superior in knowledge discovery.
Ease of implementation: There are installation packages for multiple platforms and programming environments including Jupyter, Docker, JSON, Cloud, Hadoop, and many others.
Compatibility and integration: MLDB provides a higher degree of compatibility with different application programming interfaces (APIs) and modules including JSON, REST and Python based wrappers.
Deployment: MLDB can be deployed easily on an HTTP endpoint that provides easy interface and fast deployment.
MongoDB and NoSQL support: The bridge or interface of MongoDB and MLDB can be created to support MLDB SQL queries. These SQL queries can be executed on MongoDB collections, which give MLDB more powers to interact with NoSQL databases for unstructured and heterogeneous datasets.
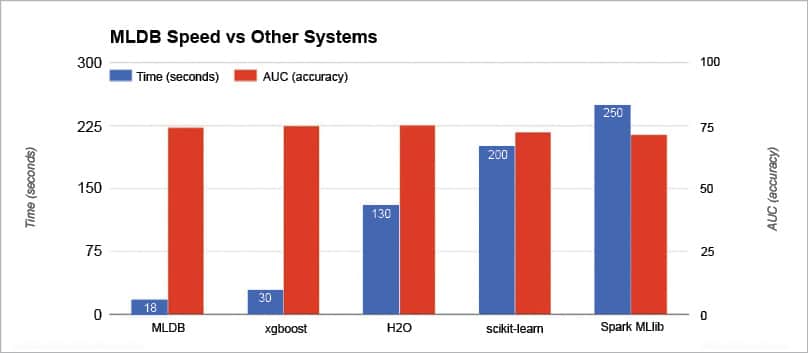
Figure 3 depicts the performance of MLDB when compared to other libraries. An execution of the 100 Tree Random Forest approach is done on 1 million rows with one node using MLDB and other libraries. From the graphical results, it is evident that MLDB is comparatively better, takes less time and its accuracy compares well with other machine learning libraries. The performance of MLDB is comparable with that of xgboost, H2O, Scikit-Learn and Spark Mlib.
Support for algorithms in MLDB
The procedures of MLDB are used for the training of machine learning models and these are implemented using functions. Given below is the list of functions and procedures that can be used in MLDB with high performance.
Supervised machine learning
- Classification including multi-label classification: classifier.train
- Logistic regressions
- Generalised linear models
- Neural networks
- Decision trees
- Random forests
- Naive Bayes models using boosting and bagging
- Support vector machines (SVM): svm.train
- Classifiers calibration: probabilizer.train
Deep learning
-
TensorFlow models: tensorflow.graph
Clustering
-
K-Means models: kmeans.train
Dimensionality reduction, manifold learning and visualisation
- Truncated Singular Value Decompositions (SVD): svd.train
- t-distributed Stochastic Neighbour Embedding (t-SNE): tsne.train
Feature engineering
- SentiWordNet models: import.sentiwordnet
- Word2Vec: import.word2vec
- Term-Frequency/Inverse-Document-Frequency (TF-IDF) models: tfidf.train
- Count-based features: statsTable.train
- Feature Hashing/Vectorize features: feature_hasher
Installing MLDB on different platforms
MLDB provides a Web based interface for the easiest implementation and hands-on experience. A free session of MLDB can be experienced for 90 minutes using a Web based panel after signing up (registration) on https://mldb.ai/#signup. There are many demos and a lot of documentation available so that a cloud based MLDB can be worked out without installation on the local system. Even the self-created datasets can be uploaded on this hosted session.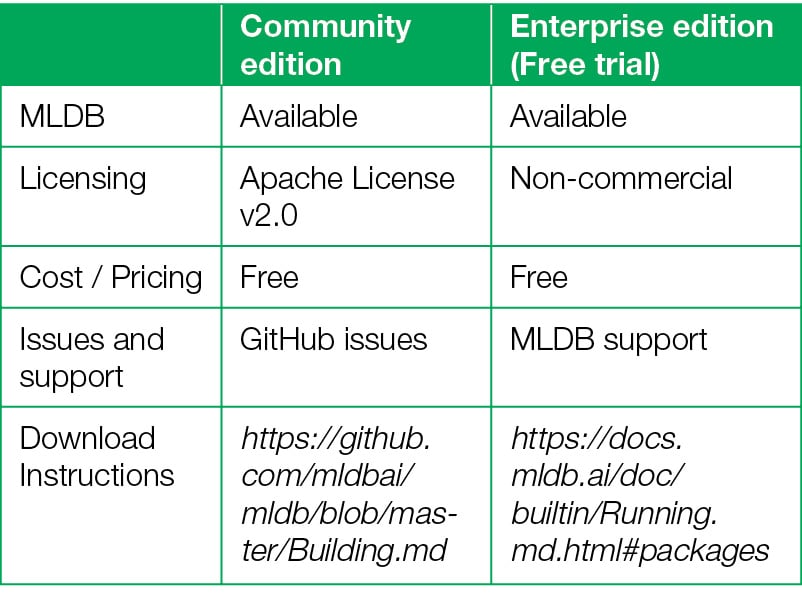 Editions for local installation
Editions for local installation
There are two editions of MLDB that are free, and are distributed as community and enterprise editions. To run the MLDB enterprise edition, you need to enter the licence key to activate the software. A licence key can be created for first-time users on signing up at https://mldb.ai/#license_management and filling the required details in the registration form.
Docker image
The classical MLDB distribution is the Docker image. While other distributions are available for virtual machines, the Docker image is executed as a container. This method is used for Linux flavours or private cloud deployments.
After the installation of Docker, the MLDB container is launched with a pre-specified mapped directory.
$ mkdir </my/system/path/myMLDBdata>
With the execution of the following commands, a port can be set using the mldbport parameter.
docker run --rm=true \ -v </my/system/path/myMLDBdata>:/mldb_data \ -e MLDB_IDS=”`id`” \ -p 127.0.0.1 (IP-Address):<mldbport>:80 (Port) \ quay.io/mldb/mldb:latest
For security and overall integrity, a tunnel is established for remote servers as in the following instruction using the SSH tunnel:
$ ssh -f -o ExitOnForwardFailure=yes <user>@<remotehost> -L <localport>:127.0.0.1 (IP-Address):<mldbport> -N
Once the message ‘MLDB Ready’ is viewed, the browsing and activation of MLDB can be done on a Web browser using the URL http://localhost:<localport>.
Virtual appliance
The installation of MLDB for virtualisation is very easy. The virtual application (OVA file) is available so that it can be imported using VirtualBox or any other virtualisation software.
After downloading VirtualBox from https://www.virtualbox.org/wiki/Downloads, the OVA file of MLDB Appliance at http://public.mldb.ai/mldb.ova can be imported.
Simply double-click the OVA file or select ‘Import Appliance’ in the File Menu of VirtualBox and finally point out to the downloaded MLDB OVA distribution.
The default user name to log in on OVA is ‘ubuntu’ and the password for successful authentication is ‘mldb’.
After these steps, the MLDB instance can be executed using the URL http://localhost:8080/ on any Web browser.
Cloud servers
MLDB can be installed and deployed on the cloud environment of Amazon Web Services (AWS). The Amazon Machine Image (AMI) is available for deployment on AWS, and can be easily attached in the dashboard of Amazon Cloud.
The steps needed for attaching and configuring AMI in AWS are as follows:
- Create an Amazon Web Services (AWS) account on http://aws.amazon.com/
- Create Instance Wizard’ should be selected from ‘N’, the Virginia Zone on the AWS dashboard.
- Select Amazon Machine Image (AMI).
- From Community AMIs, search ‘Datacratic MLDB’.
- Launch the latest AMI for MLDB.
- Any instance can be selected from AWS depending upon the usage and load of the application.
- Configure AWS instance details.
- Add up the storage or memory parameters in Amazon.
- Name the remote machine.
- Integrate SSH Port 22 with the machine.
- Launch the instance.
- Establish a security tunnel.
-
Activate MLDB.

















{kind=link}