


























































The constant generation of huge quantities of data needs data management and analysis. Let’s take a look at how the five best Apache Big Data frameworks compare in doing that.
Sets of huge volumes of complex data that cannot be processed using traditional data processing software are termed Big Data. The functions of Big Data include privacy, data storage, capturing data, data analysis, searching, sharing, visualisation, querying, updating, transfers, and information security.
There are many Big Data techniques that can be used to store data, to perform tasks faster, to make the system parallel, to increase the speed of processing and to analyse the data. There are also a number of distributed computation systems that can process Big Data in real-time or near real-time.
A brief description of the five best Apache Big Data frameworks follows.
Apache Hadoop
Apache Hadoop is an open source, scalable and fault tolerant framework written in Java. It is a processing framework that exclusively provides batch processing, and efficiently processes large volumes of data on a cluster of commodity hardware. Hadoop is not only a storage system but is a platform for storing large volumes of data as well as for processing.
Modern versions of Hadoop are composed of several components or layers that work together to process batch data. These are listed below.
- HDFS (Hadoop Distributed File System): This is the distributed file system layer that coordinates storage and replication across the cluster nodes. HDFS ensures that data remains available in spite of inevitable host failures. It is used as the source of data, to store intermediate processing results, and to persist the final calculated results.
- YARN: This stands for Yet Another Resource Negotiator. It is the cluster coordinating component of the Hadoop stack, and is responsible for coordinating and managing the underlying resources and scheduling jobs that need to be run. YARN makes it possible to run many more diverse workloads on a Hadoop cluster than was possible in earlier iterations by acting as an interface to the cluster resources.
- MapReduce: This is Hadoop’s native batch processing engine.
Apache Storm
Apache Storm is a stream processing framework that focuses on extremely low latency and is perhaps the best option for workloads that require near real-time processing. It can handle very large quantities of data and deliver results with less latency than other solutions. Storm is simple, can be used with any programming language, and is also a lot of fun.
Storm has many use cases: real-time analytics, online machine learning, continuous computation, distributed RPC, ETL, and more. It is fast—a benchmark clocked it at over a million tuples processed per second per node. It is also scalable, fault-tolerant, guarantees your data will be processed, and is easy to set up and operate.
Apache Samza
Apache Samza is a stream processing framework that is tightly tied to the Apache Kafka messaging system. While Kafka can be used by many stream processing systems, Samza is designed specifically to take advantage of Kafka’s unique architecture and guarantees. It uses Kafka to provide fault tolerance, buffering and state storage.
Samza uses YARN for resource negotiation. This means that, by default, a Hadoop cluster is required (at least HDFS and YARN). It also means that Samza can rely on the rich features built into YARN.
Apache Spark
Apache Spark is a general purpose and lightning fast cluster computing system. It provides high-level APIs like Java, Scala, Python and R, and is a tool for running Spark applications. It is 100 times faster than Big Data Hadoop and ten times faster than accessing data from the disk. It can be integrated with Hadoop and can process existing Hadoop HDFS data.
Apache Spark is a next generation batch processing framework with stream processing capabilities. Built using many of the same principles of Hadoop’s MapReduce engine, Spark focuses primarily on speeding up batch processing workloads by offering full in-memory computation and processing optimisation.
Spark can be deployed as a standalone cluster (if paired with a capable storage layer) or can hook into Hadoop as an alternative to the MapReduce engine.Apache Flink
Apache Flink is an open source platform; it is a streaming data flow engine that provides communication, fault tolerance and data distribution for distributed computations over data streams. It is a scalable data analytics framework that is fully compatible with Hadoop. Flink can execute both stream processing and batch processing easily.
While Spark performs batch and stream processing, its streaming is not appropriate for many use cases because of its micro-batch architecture. Flink’s stream-first approach offers low latency, high throughput, and real entry-by-entry processing.
















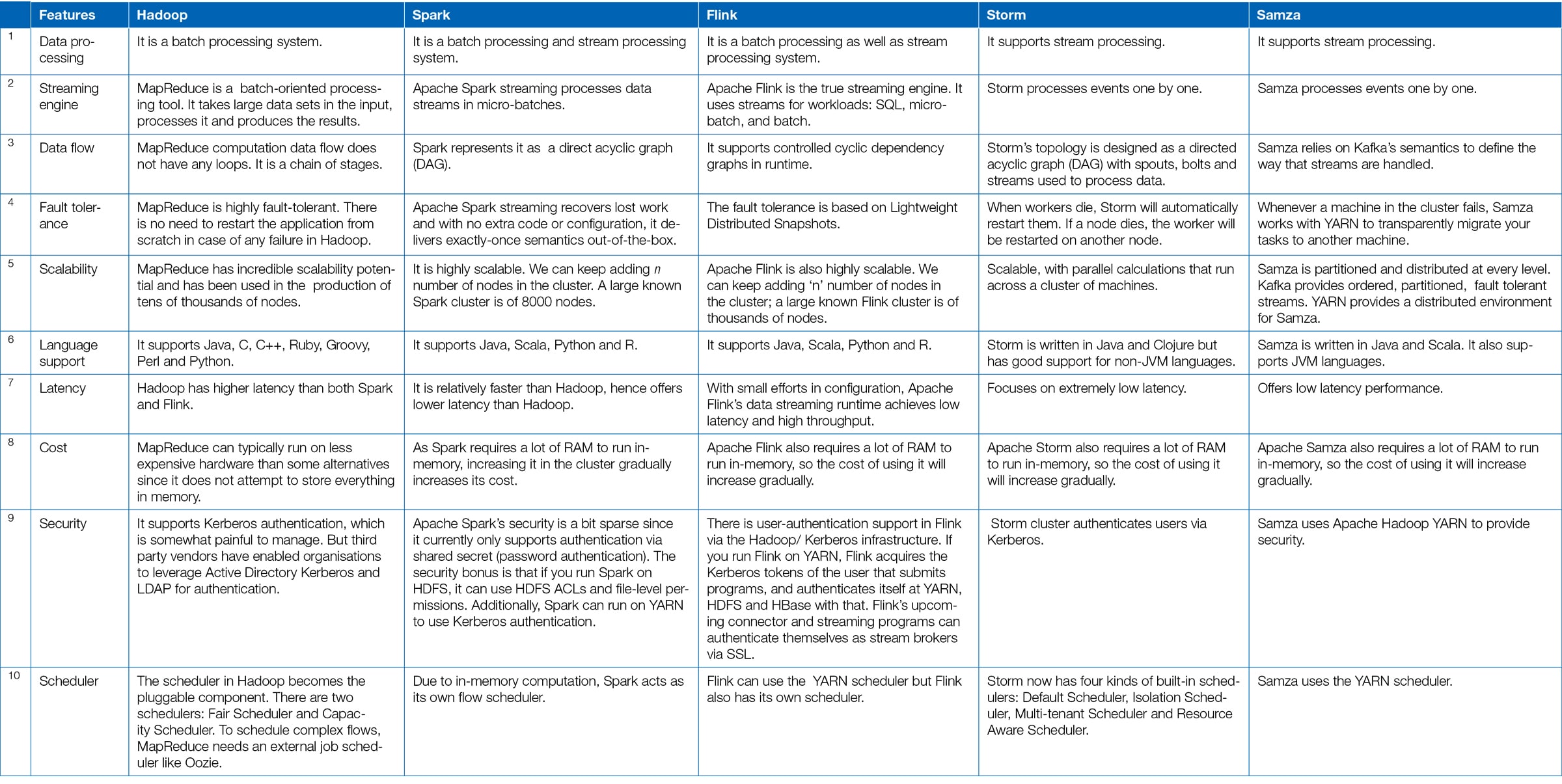
The image (table showing the comparisons) need to be high resolution. Practically nothing can be read off.