






























































Having set up a DHCP server, I now plan to deploy a DNS server in my network. It is always a better option to have DNS and DHCP on the same server, so that IP addresses allocated by the DHCP server to a particular host can be updated in the DNS database, instantly. If, for some reason, this DNS-DHCP server goes down, it impacts the whole production environment adversely. As a preventive measure, we have to introduce a secondary DNS-DHCP server, which has to be configured in a high availability mode (HA), so that if the primary server goes down, the secondary server takes over and caters to the incoming requests.
PowerDNS is our prime choice for configuring the authoritative DNS server, with MySQL database as the backend, as this combination has its own merits. This set-up handles incoming queries, looks through DNS records in the MySQL database and provides appropriate responses. The DNS servers being HA, the databases in both the servers must always be kept in sync. Moreover, both the DHCP servers work in active-active mode, such that they divide the IP address pool among themselves and cater to the incoming DHCP requests working in tandem. As a result, there are multiple read/writes happening from both the servers in their own MySQL databases. In order to keep both the databases in sync, there has to be such a mechanism, such that if any server makes changes in the database, it should be reflected in the database of the other server and they all maintain the same DNS records.
To create a high availability environment, as mentioned above, MySQL provides two solutions – MySQL replication and the MySQL cluster. Master-slave replication, wherein we have one read/write and one or more read-only slaves, is not useful in this scenario, as the replication is one way (from master to slave). While MySQL master-master replication is one of the alternatives, it is not a good choice, especially when there are multiple masters receiving write requests simultaneously. The big disadvantage of circular replication (A to B, B to C, C to D, and D to A) is that if any node fails, replication halts for subsequent nodes in the chain.
On the other hand, the MySQL cluster is:
- An in-memory (or main-memory) database system, which relies on the main memory for data storage, management and manipulation, to achieve better performance while querying the data.
- A shared-nothing architecture database, which stores data over multiple independent data nodes in a cluster, instead of shared data storage, with no single point of failure (SPOF).
- A distributed database system, which stores portions of the database on multiple nodes in the cluster, which is managed by the central distributed database management system. So even if a node goes down, data integrity is maintained. Moreover, scaling becomes a handy task with almost 99.99 per cent availability.
- Database updates are synchronously replicated between all the data nodes in the cluster, guaranteeing data availability
in case of node failures.
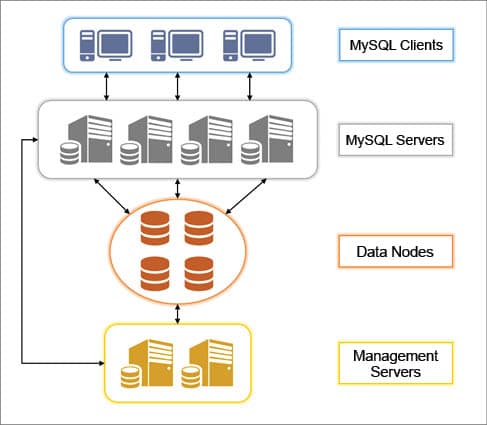
MySQL Cluster Components
Management node/server
This maintains the cluster’s global configuration file and provides cluster information whenever required. It also maintains logs of events happening in the cluster. The management client in the management node does all the administrative work, like starting/stopping nodes, starting/stopping backups and checking the cluster’s status.
MySQL nodes/servers
These servers contain local configuration files. They run the mysqld daemon and group together to form a cluster, thus achieving high performance (due to parallelism) and high availability. These nodes cater to all incoming queries, communicate with data nodes and provide application access to the cluster.
Data nodes
These nodes run the ndbd daemon and are responsible for data storage and retrieval. Multiple data nodes come together to provide storage for the entire cluster, so that clients see them as a single database. Besides data storage, they keep monitoring other data nodes in the cluster and inform the management server in case of failures.
How it works
At the heart of the MySQL cluster, there lies the NDB (network database) storage engine, which is actually responsible for the high-available environment and data redundancy. In the basic scenario, we have an application that sends a query, usually as INSERT/UPDATE/DELETE-like SQL statements, to the MySQL server. In the MySQL cluster, one of the MySQL servers runs the NDB storage engine (or NDBCluster), which receives incoming SQL queries and communicates with data nodes to store the data. After confirming the successful writing of the data into the data nodes, the MySQL server acknowledges the application with an OK status.
In order to keep data available even after a node failure, it is divided into a number of chunks called partitions, which are equal to the number of nodes present in the cluster. So, each node has to store one partition along with a copy of a partition – this is called a replica. The number of the replica is mentioned in the configuration file on the management node. The MySQL cluster boasts of 99.999 per cent availability and replicas are key elements.
Handling failures
When a MySQL node fails, being a shared-nothing architecture, no other nodes (MySQL/data nodes or management nodes) in the cluster are affected – they continue doing their tasks. It’s up to the application to connect to another MySQL node in the cluster. On the other hand, if a data node fails, another data node in the cluster takes over the responsibility and due to data redundancy (replicas), data will also be available. While the MySQL cluster takes care of node failures, you need to take care that the failed data node wakes up as early as possible, as you never know when other node(s) will stop working. Failure of the management node doesn’t hamper the set-up much, as this node deals only with monitoring and backup tasks but then you might not be able to start/stop other cluster nodes. Having two management nodes is definitely a solution.
Implementation
Considering that I have three subnets and I do not have any budget issues, I opt to deploy four DNS-DHCP servers, of which three will be primary for their respective networks and the fourth will be secondary. I will have MySQL databases on all these four nodes (MySQL + Data nodes) and these are to be clustered such that they are in sync. For setting up the MySQL cluster, I will need another two nodes to be configured as management nodes. The scenario is given in the table below.
Management nodes
mgmtsrv01 172.22.100.10
mgmtsrv02 172.22.96.10
MySQL and data nodes
dhcpsrv01 172.22.11.100 (Primary DHCP for Region 1
dhcpsrv02 172.22.22.100 (Primary DHCP for Region 2)
dhcpsrv03 172.22.33.100 (Primary DHCP for Region 3)
dhcpsrv04 172.22.44.100 (Secondary DHCP for all)
System: Linux based virtual machines
Operating system: CentOS release 6.7
RAM: 8GB
CPU cores: 4
Packages dependencies
1. libaio.x86_64 0:0.3.107-10.el6.rpm
2. libaio-devel.x86_64 0:0.3.107-10.el6.rpm
3. numactl-2.0.9-2.el6.x86_64.rpm
4. cryptopp-5.6.1-8.1.x86_64.rpm (required for PDNS)
5. php-pear-MDB2-Driver-mysql-1.5.0-0.8.b4.el6.noarch.rpm
(required for PDNS)
6. php-pear-MDB2-2.5.0-0.7.b4.el6.remi.noarch.rpm (required for PDNS)
7. php-mysql-5.3.3-46.el6_6.x86_64 (required for PDNS)
8. php-pear-1.9.4-4.el6.noarch (required for PDNS)
9. php-pdo-5.3.3-46.el6_6.x86_64 (required for PDNS)
10. perl-DBD-MySQL-4.013-3.el6.x86_64 (required for PDNS)
Packages installed
1. MySQL-Cluster-client-gpl-7.3.11-1.el6.x86_64.rpm
2. MySQL-Cluster-server-gpl-7.3.11-1.el6.x86_64.rpm
3. MySQL-Cluster-shared-compat-gpl-7.3.11-1.el6.x86_64.rpm
(required for PDNS)
Packages that need to be removed (if any)
1 mysql-server 2. mysql 3. mysql-libs
Configuration for data nodes
Edit the /etc/my.cnf file as shown below:
[mysqld] ndbcluster # IP address of the cluster management node ndb-connectstring=172.22.100.10,172.22.96.10 socket=/var/lib/mysql/mysql.sock user=mysql innodb_data_file_path = ibdata1:10M:autoextend pid-file=/var/run/mysqld/mysqld.pid explicit_defaults_for_timestamp = 1 [mysql_cluster] # IP address of the cluster management node ndb-connectstring=172.22.100.10,172.22.96.10 [mysqld_safe] log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid
Configuration for management nodes
Edit the /var/lib/mysql-cluster/config.ini file as shown below:
[ndbd default] NoOfReplicas=4 DataDir=/opt/mysql-cluster/data MaxNoOfAttributes=10000 MaxNoOfConcurrentOperations=150000 MaxNoOfOrderedIndexes=512 # MANAGEMENT NODES [ndb_mgmd] NodeId=1 hostname=172.22.100.10 datadir= /var/lib/mysql-cluster [ndb_mgmd] NodeId=2 hostname=172.22.96.10 datadir= /var/lib/mysql-cluster # DATA NODES [ndbd] NodeId=3 hostname=172.22.11.100 datadir=/usr/local/mysql/data [ndbd] NodeId=4 hostname=172.22.44.100 datadir=/usr/local/mysql/data [ndbd] NodeId=5 hostname=172.22.33.100 datadir=/usr/local/mysql/data [ndbd] NodeId=6 hostname=172.22.22.100 datadir=/usr/local/mysql/data #MYSQL NODES [mysqld] NodeId=7 hostname=172.22.11.100 [mysqld] NodeId=8 hostname=172.22.44.100 [mysqld] NodeId=9 hostname=172.22.33.100 [mysqld] NodeId=10 hostname=172.22.22.100
Note: It is recommended that the MySQL root password is set before proceeding.
MySQL cluster set-up
On management nodes: To start the cluster, use the following command:
ndb_mgmd -f /var/lib/mysql-cluster/config.ini
It should show the following output:
MySQL Cluster Management Server mysql-5.6.27 ndb-7.3.11 2016-01-13 11:21:54 [MgmtSrvr] INFO -- The default config directory /usr/mysql-cluster does not exist. Trying to create it... 2016-01-13 11:21:54 [MgmtSrvr] INFO -- Sucessfully created config directory
On data nodes: To start the NDB cluster engine, use the following command:
ndbd
It should show the output given below:
2016-01-13 11:22:40 [ndbd] INFO -- Angel connected to 172.22.100.10:1186 2016-01-13 11:22:40 [ndbd] INFO -- Angel allocated nodeid: 3
On MySQL nodes: To start the MySQL service, use the command shown below:
service mysql start
To check the cluster status from the management node, use the following command:
ndb_mgm show
If the cluster is healthy, it must display the following output:
mgmtsrv02 root [mysql-cluster] > ndb_mgm -- NDB Cluster -- Management Client -- ndb_mgm> show Connected to Management Server at: 172.22.100.10:1186 Cluster Configuration --------------------- [ndbd(NDB)] 4 node(s) id=3 @172.22.11.100 (mysql-5.6.27 ndb-7.3.11,Nodegroup: 0, *) id=4 @172.22.44.100 (mysql-5.6.27 ndb-7.3.11, Nodegroup: 0) id=5 @172.22.33.100 (mysql-5.6.27 ndb-7.3.11, Nodegroup: 0) id=6 @172.22.22.100 (mysql-5.6.27 ndb-7.3.11, Nodegroup: 0) [ndb_mgmd(MGM)] 2 node(s) id=1 @172.22.100.10 (mysql-5.6.27 ndb-7.3.11) id=2 @172.22.96.10 (mysql-5.6.27 ndb-7.3.11) [mysqld(API)] 4 node(s) id=7 @172.22.11.100 (mysql-5.6.27 ndb-7.3.11) id=8 @172.22.44.100 (mysql-5.6.27 ndb-7.3.11) id=9 @172.22.33.100 (mysql-5.6.27 ndb-7.3.11) id=10 @172.22.22.100 (mysql-5.6.27 ndb-7.3.11)
Otherwise, in case if any node goes down, it would show:
[ndbd(NDB)] 4 node(s) id=3 @172.22.11.100 (mysql-5.6.27 ndb-7.3.11, Nodegroup: 0, *) id=4 @172.22.44.100 (mysql-5.6.27 ndb-7.3.11, Nodegroup: 0) id=5 (not connected, accepting connect from 172.22.33.100) id=6 @172.22.22.100 (mysql-5.6.27 ndb-7.3.11, Nodegroup: 0)
Any DBMS uses storage engines or database engines to write, read, update or delete data from a database. InnoDB is the default storage engine used by MySQL since version 5.5, such that whenever a table is created without the ENGINE clause, it creates an InnoDB table, by default. With InnoDB, data is read and written from the hard disk, where the MySQL server runs, and hence it necessitates configuring the disks in RAID, to achieve data redundancy.
On the other hand, the MySQL cluster uses the NDBCluster engine, which uses network connectivity in order to access data spread across different data nodes (not on MySQL servers like InnoDB). Hence, while creating tables, one must explicitly mention the NDBCluster storage engine in order to instruct MySQL servers that data has to be stored on the data nodes.

















{kind=link}