






























































MongoDB is a document-oriented database from the NoSQL family. Document databases are suitable for storing and managing Big Data-sized collections of literal documents like text documents, email messages, XML documents, etc. Documents are de-normalised (aggregate) representations of a database entity, and are suitable for storing semi-structured data that would require the extensive use of ‘nulls’ in an RDBMS. An aggregated document can be accessed with a single call to the database rather than having to join multiple tables to respond to a query. The schema in such databases are dynamic, unlike the relational databases, which require the schemas to be defined in advance. So for agile development approaches, traditional relational models are sometimes not suitable, because each time a new feature is added, the complete schema has to be modified.
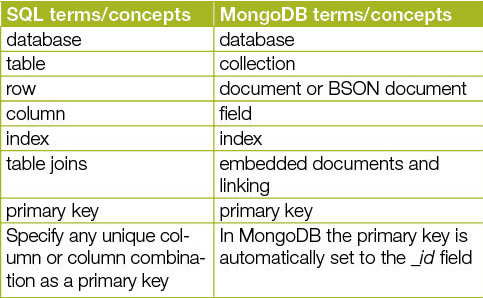
In MongoDB, a record is a document that gets stored in a binary (JSON) format and documents are grouped together into collections. Collections are similar to the tables from relational databases. Table 1 shows a comparison of SQL and MongoDB terms/concepts. The key features of MongoDB are: high performance by supporting embedded data models and indexes, high availability by replica sets (groups of MongoDB servers that maintain the same data set) to provide automatic failover and data redundancy, automatic scaling by automatic sharding (to distribute data across a cluster of machines) and flexible schema (as the schema of one document can be different from the other within the same collection).
Collections are grouped together in a database. There are several reserved databases, such as the following.
admin: This is a root database. There are certain server-wide commands like readAnyDatabase, readWriteAnyDatabase, dbAdminAnyDatabase, userAdminAnyDatabase, clusterAdmin, etc, that can be run only from the admin database. If users are added to the admin database, they automatically inherit permissions for all the databases.
local: In replication, the local database stores internal replication data for each member of a replica set. Collections from this database will not be replicated.
config: This database will store information about shards (which is explained later in this article).
Core components of the MongoDB package
Mongod: This is a core database process which handles data requests, manages data formats and performs background management operations.
Mongos: This is the controller and query router for sharded clusters, and does the routing service for MongoDB shard configurations, processes and queries from the application layer to determine the location of data in the sharded cluster.
Mongo: This interactive MongoDB shell provides a powerful interface for systems administrators as well as a way for developers to test queries and operations directly with the database.
Installation of MongoDB
MongoDB can be installed on most platforms (Linux, OS X, Windows’), and supports both 32-bit and 64-bit architectures. You can go through the following steps to install MongoDB on your machine, if you are using Ubuntu (version 14+).
Import the public key: The Ubuntu package management tools (i.e., dpkg and apt) ensure package consistency and authenticity by requiring that distributors sign packages with GPG keys. Issue the following command to import the MongoDB public GPG key:
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10
Reload the local package database, as follows:
sudo apt-get update
Install the latest version of MongoDB by using the following command:
sudo apt-get install mongodb-org
Issue the following command to start MongoDB:
sudo service mongod start
Once you have installed and started MongoDB, you can start the Mongo executable by issuing the following command:
$ mongo MongoDB shell version: xxx connecting to: test
By default, the MongoDB shell will be connected to the test database.
> db test
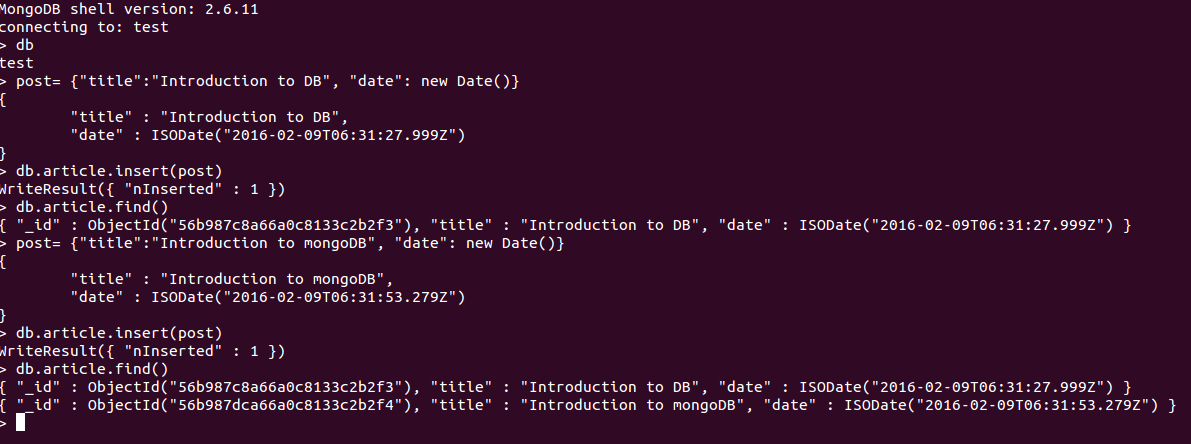
The commands given in Figure 1 can be used for four basic CRUD (create, read, update, delete) operations.
In Figure 1, ‘post’ is a document that is getting saved to the ‘article’ collection in the database. The find command can be used to query a collection. MongoDB will not permanently create a database until you insert data into it, and it will create a collection implicitly upon its first use. So it is not required to create a collection before inserting data. Every document stored in MongoDB will have an _id (default type is ObjectID) key, which will automatically be inserted in the document, whose value will be unique for a particular collection.
For updates, the db.collection.update() and the db.collection.save() methods are available. These methods update a single document, by default. With the multi option, update() can update all documents in a collection that match a query.
· db.article.update({title:Introduction to MongoDB},{$set:{date:2 Feburary 2016} })
To remove documents from a collection, use the db.collection.remove() method, and you can also pass a query criteria to determine which documents to remove.
MongoDB supports horizontal scalability and high throughput by sharding – a method for storing data across multiple machines. Sharding is done to increase available RAM and disk space, reduce load on a server, read or write data with better throughput, etc. In sharding, data is distributed across multiple servers and the ordered collections are saved across many machines. Shards are further replicated to allow failover. Each shard processes fewer operations and stores less data as the server grows; thus the capacity and throughput of the cluster will be increased horizontally. For example, a large collection could be split into many shards, say, five, and each shard in turn may be replicated four times. This would create 20 units of a MongoDB server. The three additional copies of each shard server will act as failover units.
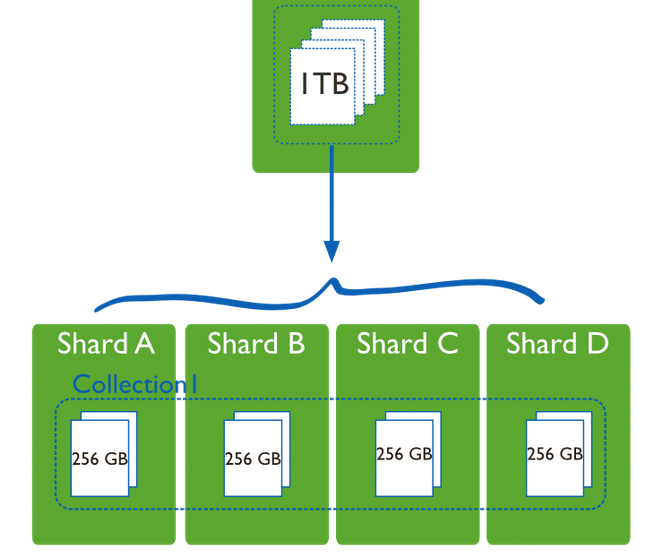
In Figure 2, if a database has a 1 terabyte data set, and there are four shards, then each shard might hold only 256GB of data. If there are 40 shards, then each shard might hold only 25GB of data and thus the load on each shard will decrease. The MongoDB sharded cluster has shards, query routers and config servers. Shards store the data, and provide high availability and data consistency. Query routers (mongos instances) direct client operations to the appropriate shards. Config servers store the clusters metadata, which is a mapping of the cluster’s data set to the shards.
While MongoDB is a database which supports horizontal scalability, by adding more and more nodes to a cluster, it can give faster results for big data sets, but it should be avoided if the system requires lots of transactions. It is a more read-intensive system. The security options are also limited to the database level. The option to grant permissions at the collection level is not available.
References
[1] https://docs.mongodb.org/manual/mongo/
[2] MongoDB The Definitive Guide by OReilly
[3] https://docs.mongodb.org/manual/reference/sql-comparison/)

















{kind=link}