





























































This article introduces the reader to Java Collections, which is a framework that provides an architecture for collecting and manipulating a group of objects. Operations such as searching, sorting, insertion, manipulation, deletion, etc, can easily be performed by Java Collections.

The modern IT world revolves around data. Every new site asks for a sign-up and, in the process, collects information and saves it. There is cut-throat competition in gathering data. Sites that have a large user base and hence a vast store of data have the upper hand. Whether it is Google, Amazon, Flipkart, WhatsApp, Facebook or Twitter, all of them gather information and save it because data is of utmost importance in the present-day world.
Data in its raw form is like a chunk of ore from which the diamond is yet to be extracted. It is hard to process the raw data so the need for structured data arises, which is when data structures become handy. In computer science, a data structure is a particular way of organising data in a computer so that it can be used efficiently. Searching a particular book from millions of books on Amazon or sorting through the endless choice of mobile phones on the basis of price are all done with low cost and low complexity algorithms, which work on structured data.
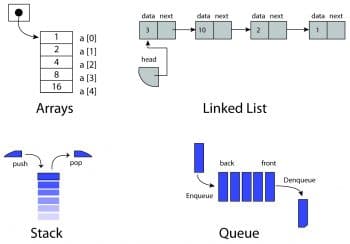
Data can be structured in many ways but the commonly used practices are given below:
Arrays
This is a data structure that can store a fixed-size sequential collection of elements of the same type. Elements are accessed using indexes.
Linked List
This data structure consists of a group of nodes, which together represent a sequence. Under the simplest form, each node is composed of data and a pointer to the next node. This structure allows for efficient insertion or removal of elements from any position in the sequence.
Stack
This is a data structure that implements the LIFO (Last In First Out) paradigm. It is like a pile of plates – the one put in last is removed first. It can be implemented both through arrays and Linked List. Push and Pop are the two main operations on the stack. This is basically used in recursion.
Queue
This is a FIFO (First In First Out) data structure. It is similar to a queue of people at a movie ticket counter. The first element added to the queue will be the first one to be removed.
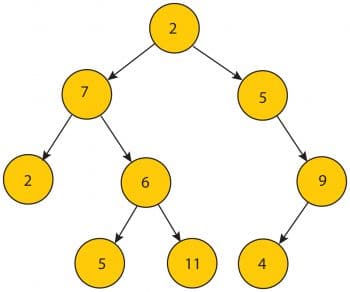
Tree
A tree consists of a set of elements (nodes) which can be linked to other elements, sometimes hierarchically and sometimes not. A tree data structure can be defined recursively (locally) as a collection of nodes (starting at a root node), where each node is a data structure consisting of a value, together with a list of references to nodes (the Children), with the constraint that no reference is duplicated or points to the root.
Earlier, all these data structures were written in C or C++ and had to be created every time in order to store data. Java came up with a solution that provided an API in the java.util package. This contains classes and interfaces which implement all these data structures, are ready to be used and make work easy for the coder.
In looking further to find how Java implements the structuring of data, I came across the Java Collection framework. This provides the architecture to store and manipulate a group of objects. Operations like searching, sorting, insertion, deletion and manipulation are all performed using the collection framework.
Now lets carefully analyse each data structure and look at how these are implemented by Collection. The Java Collection framework provides many interfaces (Set, List, Queue, Deque, etc) and classes (ArrayList, Vector, LinkedList, HashSet, LinkedHashSet, TreeSet, etc).
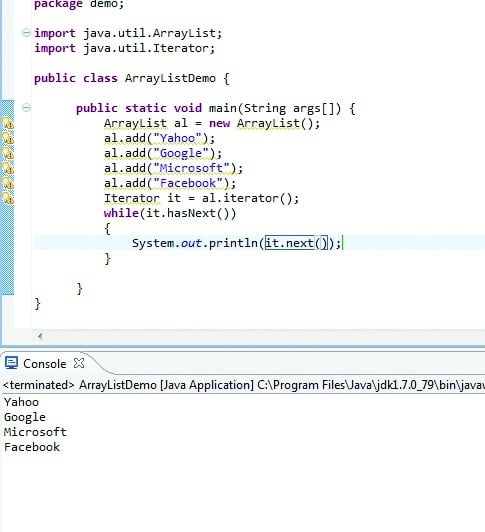
ArrayList class
This class uses dynamic arrays for storing elements, and arrays are sequentially arranged in the memory. It implements the List interface and extends the AbstractList class. It can contain duplicate elements, and it maintains an insertion order. The elements can be accessed using the index notation. This class contains various inbuilt methods, which help in making data retrieval and manipulation easy.
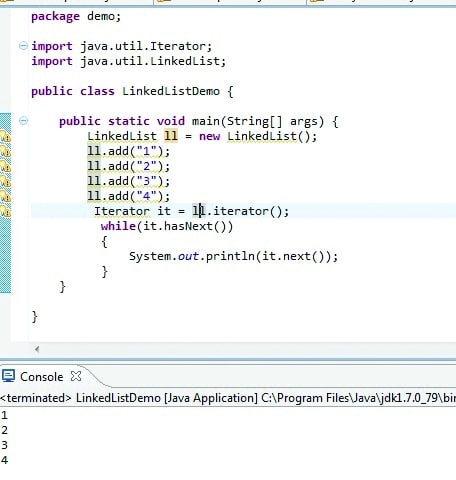
LinkedList class
This class uses a doubly-linked list to store elements. It maintains an insertion order, and it can be used as a list, stack or queue. It actually implements the List and Dequeue interfaces and extends the Abstract class. The add and remove methods are used to add and delete. The size method returns the number of lists in the list.
HashMap
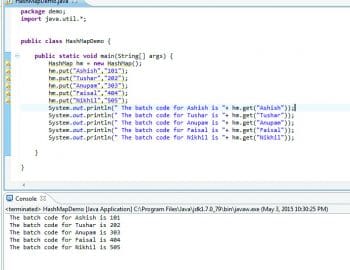
This is used to store key value pairs. It implements the Map interface and is not a part of the collection. HashMap uses the hashing technique to store key value pairs. The key value pair is called a bucket. Each bucket is stored in an array in the HashMap class. The hashing function works on the key and returns an index at which the bucket is stored. There are chances of two keys returning the same index upon hashing. In such cases, the buckets are stored at the same index but are linked, the same as in a Linked List. Each bucket contains the pointer to the next bucket. The equals method is overridden, and the value is fetched when the key matches the key in the bucket. HashMap contains two basic methods, called get and put, to get the value and put the key value pair in the map.
TreeMap
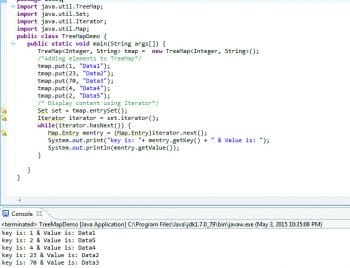
The TreeMap class implements the Map interface by using a tree. A TreeMap provides an efficient means of storing key/value pairs in sorted order, and allows rapid retrieval. You should note that, unlike a HashMap, a TreeMap guarantees that its elements will be sorted in ascending key order. You can specify the sorting order while creating TreeMap by providing an explicit comparator to TreeMap. Basically, you can create TreeMap in Java in different waysa TreeMap with a natural sorting order, and TreeMap with custom sorting order by providing the comparator, by copying the sorting order from the other SortedMap, etc.

TreeSet
This provides an implementation of the Set interface that uses a tree for storage. Objects are stored in sorted, ascending order. Access and retrieval times are quite fast, which makes TreeSet an excellent choice when storing large amounts of sorted information that must be found quickly. It contains unique elements only.
To end this discussion, I must say that Java has simplified the use of data structures by providing the ready to use collection framework. For more details, you can visit the Oracle website.

















{kind=link}
Thanks, It was helpful.
Collections in java is a framework that provides an architecture to store and manipulate the group of objects. Java Collection simply means a single unit of objects. Java Collection framework provides many interfaces . Many thanks for sharing this.
Hello,
I found your article very useful and the tools you talked about were unique.
thanks for posting..