


























































OpenShift is a Kubernetes based container application, designed for container based software deployment and management. It is an application development and hosting platform, which automates management and enables the developer to focus on the app itself.
The increase in the volume, velocity and the variety of data from multiple channels demands high performance computing resources that can process heterogeneous Big Data. It is not always possible to purchase costly computing resources like high performance multi-core processors with supercomputing powers, huge memory devices and related technologies to process, visualise and make predictions on the datasets related to live streaming and real-time supercomputing applications. To cope with and work with such technologies, cloud services are used, whereby computing resources can be hired on demand and billed for as per usage.
There are a number of cloud services providers in the global market with different delivery models including Infrastructure-as-a-Service (IaaS), Platform-as-a-Service (PaaS) and Software-as-a-Service (SaaS). Nowadays, there are some new keywords in the cloud delivery space, like Network-as-a-Service (NaaS), Database-as-a-Service (DBaaS), Testing-as-a-Service (TaaS) and many others. Each of these cloud delivery approaches has different resources, which are used for different applications.

Features of Red Hat OpenShift
Red Hat OpenShift is one of the leading cloud services providers in the PaaS (Platform as a Service) paradigm. It provides multiple platforms to cloud users with the flexibility to develop, deploy and execute applications on the cloud. OpenShift has high performance data centres with enormous processing power to work with different programming languages, which include Java, PHP, Ruby, Python, Node.js, Perl, Jenkins Server, Ghost, Go and many others.
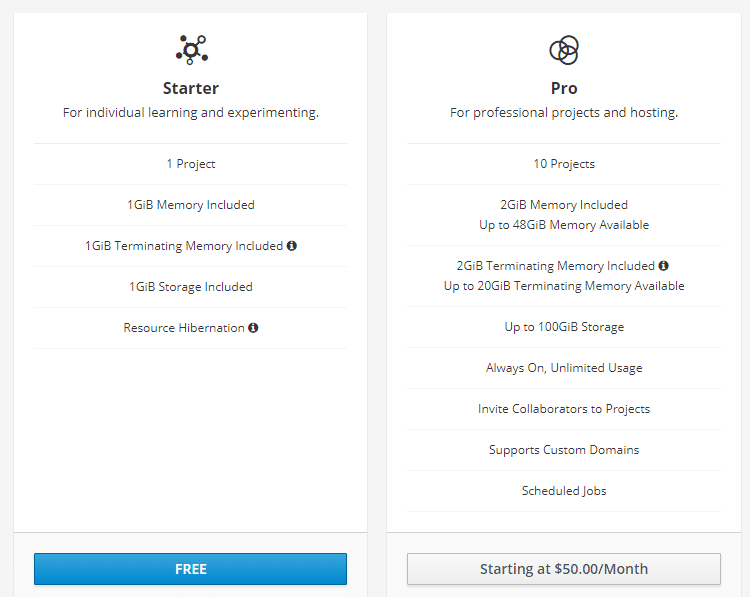
A beginner can use the Free Tier of Red Hat OpenShift for the development, deployment and execution of new cloud apps on the online platform provided by it. Any of the programming languages mentioned can be used for the development of apps with real-time implementation.
Developing PHP research based Web applications
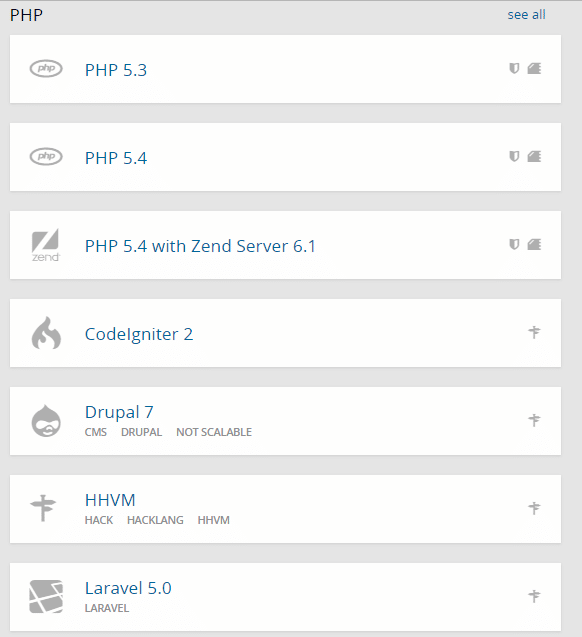
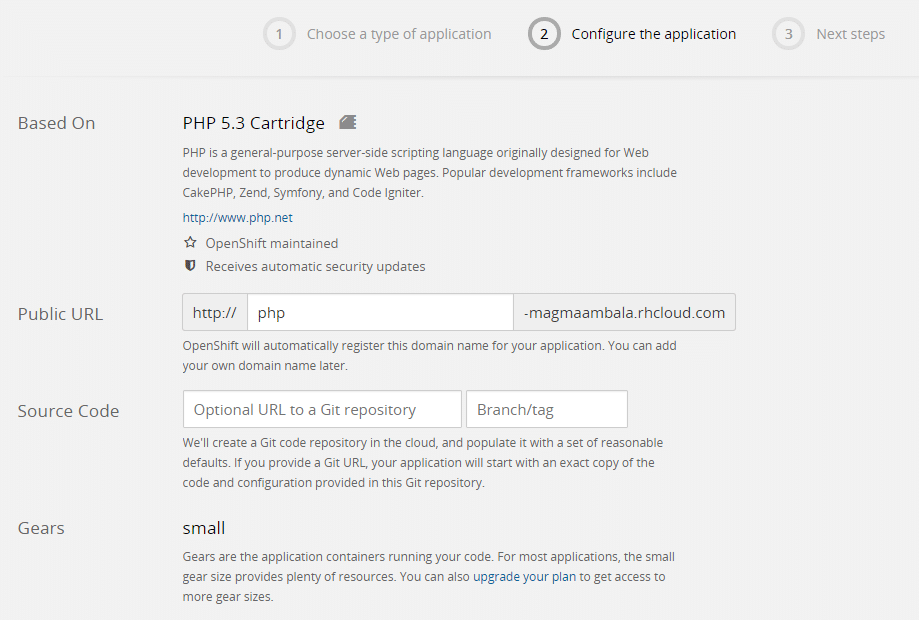
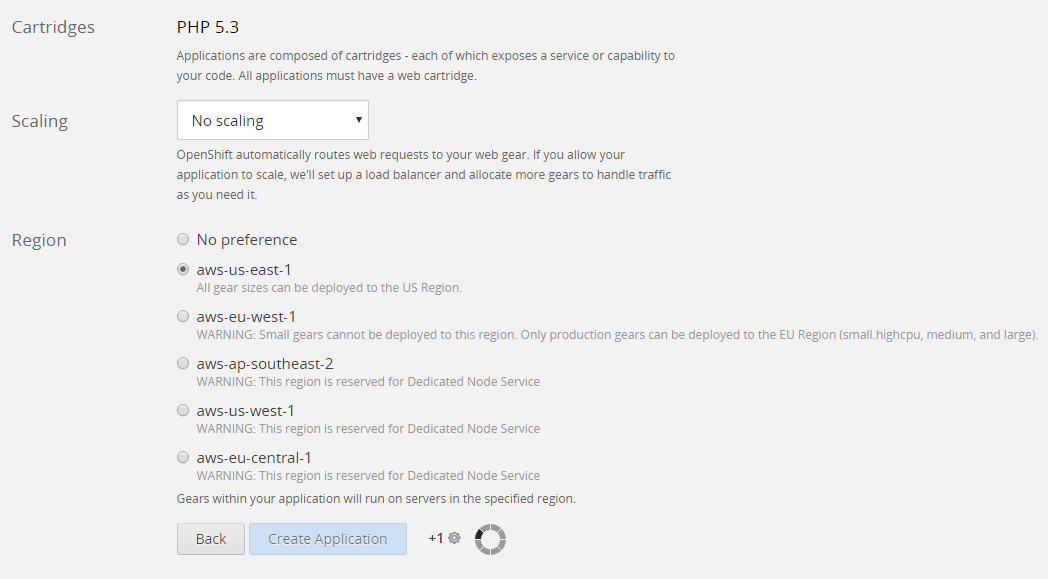
OpenShift provides multiple programming language options to cloud users for the development of apps. With each programming language, OpenShift delivers multiple versions so that the compatibility issues can be avoided at later stages.
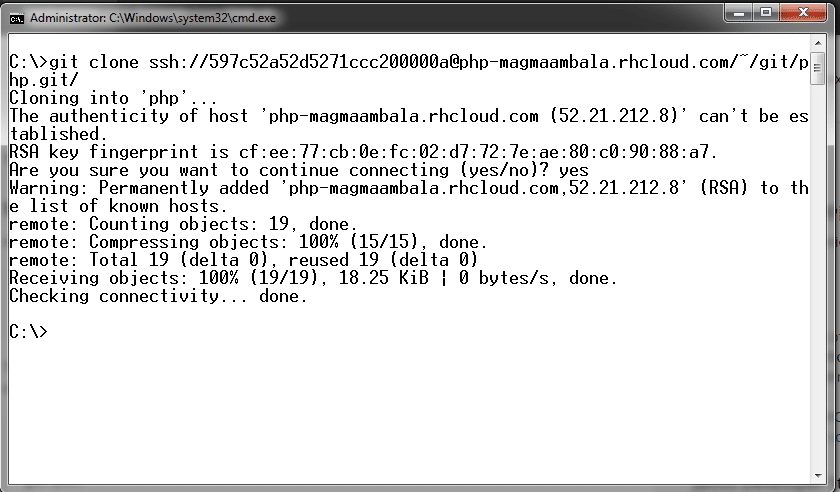
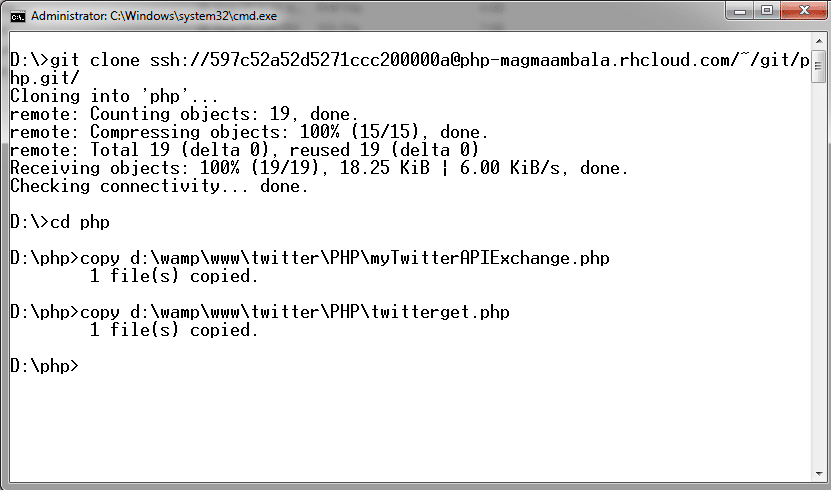
The cloud applications can be uploaded using mapping with GIT via a local command prompt (Windows CMD or Linux Terminal). OpenShift specifies the commands that should be executed on the local command prompt or in the Linux Shell.
Developing a Twitter extraction using PHP on the OpenShift PaaS
To develop a Twitter extraction on the OpenShift PaaS, use the code given below:
<?php
error_reporting(0);
require_once(‘TwitterAPIExchange.php’);
$settings = array(
‘oauth_access_token’ => “XXXXXXXXXXXXXXXXXXXXXXXXX”,
‘oauth_access_token_secret’ => “ XXXXXXXXXXXXXXXXXXXXXXXXX “,
‘consumer_key’ => “ XXXXXXXXXXXXXXXXXXXXXXXXX “,
‘consumer_secret’ => “ XXXXXXXXXXXXXXXXXXXXXXXXX “
);
$twitterurl = “https://api.twitter.com/1.1/statuses/user_timeline.json”;
$requestMethod = “GET”;
if (isset($_GET[‘user’])) {$user = $_GET[‘user’];} else {$user = “gauravkumarin”;}
if (isset($_GET[‘count’])) {$count = $_GET[‘count’];} else {$count = 20;}
$field = “?screen_name=$user&count=$count”;
$mytwitter = new TwitterAPIExchange($settings);
$str = json_decode($mytwitter->setGetfield($field)
->buildOauth($twitterurl, $requestMethod)
->performRequest(),$assoc = TRUE);
if($str[“errors”][0][“message”] != “”) {echo “<h3>Sorry, there was a problem.</h3><p>Twitter returned the following error message:</p><p><em>”.$str[errors][0][“message”].”</em></p>”;exit();}
foreach($str as $current)
{
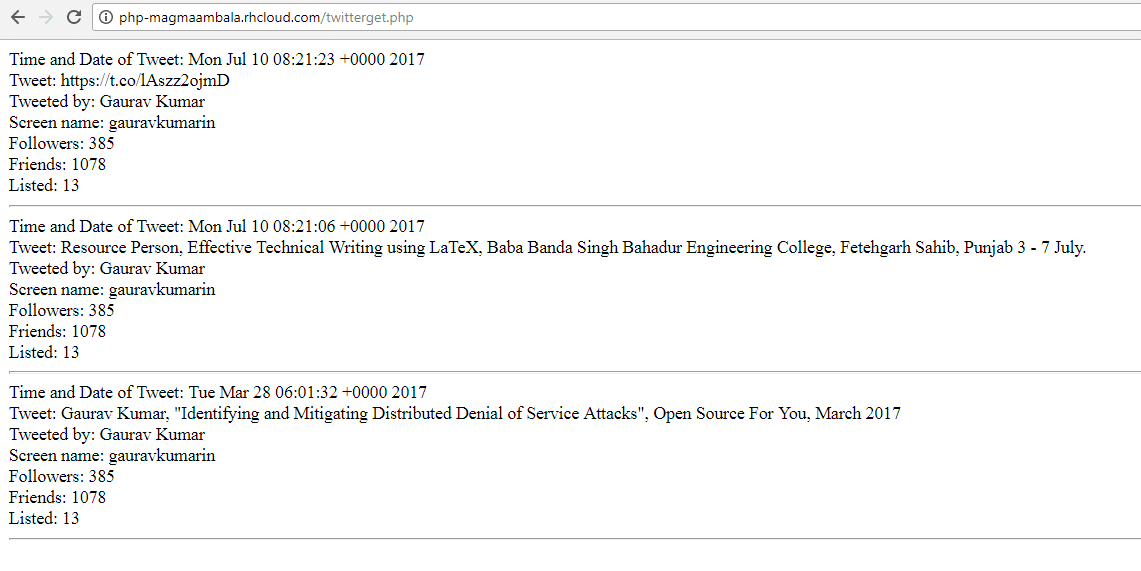
echo “Time and Date of Tweet: “.$current[‘created_at’].”<br />”;
echo “Tweet: “. $current[‘text’].”<br />”;
echo “Tweeted by: “. $current[‘user’][‘name’].”<br />”;
echo “Screen name: “. $current[‘user’][‘screen_name’].”<br />”;
echo “Followers: “. $current[‘user’][‘followers_count’].”<br />”;
echo “Friends: “. $current[‘user’][‘friends_count’].”<br />”;
echo “Listed: “. $current[‘user’][‘listed_count’].”<br /><hr />”;
}
?>
PHP based machine learning on the OpenShift PaaS
Machine learning is a powerful science that makes use of soft computing and meta-heuristic approaches for effectual predictive mining even from a huge dataset (https://php-ml.readthedocs.io/en/latest/). It has been traditionally used for fraud detection, market analytics, email spam filtering, malware analysis, fingerprint evaluation, face detection and many other applications. In machine learning, the algorithms are implemented in a way in which better classifications and predictions can be made—somewhat similar to the intelligence of the human brain. In traditional implementations, artificial neural networks are used with machine learning to solve complex classification problems.
A number of libraries and frameworks are available under Free and Open Source Software (FOSS) distribution for machine learning. FOSS libraries that can be integrated for research and development include PHP-ML, Apache Mahout, Shogun, Apache Singa, Apache Spark Mlib, TensorFlow, Oryx2, Accord.NET, Amazon Machine Learning, Scikit-Learn, H2O, ConvNetJS, etc.
PHP-ML is a powerful machine learning library used for R&D in the domain of machine learning for different applications. It integrates assorted algorithms in the form of classes and methods for high performance computing with the analytics from real-time datasets. PHP-ML has a rich set of algorithms implemented in PHP Scripts, and these can be easily integrated on the real-time cloud of
OpenShift by uploading the code and mapping with GIT.
Key features and algorithms in PHP-ML
Association rule learning: Apriori
Classification: KNearestNeighbors, Naive Bayes, SVC, etc
Clustering: k-Means, DBSCAN
Cross validation: Random split, stratified random split
Feature extraction: Token count vectoriser, Tf-idf transformer
Metric: Accuracy, confusion matrix, classification report
Models management: Persistency
Math: Distance, matrix, set, statistic
Neural network: Multi-layer perceptron classifier
Preprocessing: Normalisation, imputation missing values
Regression: Least squares, SVR
Workflow: Pipeline
Datasets: Array, CSV, files, datasets for research: Iris, Wine and Glass
KNearestNeighbors Classifier in PHP-ML
KNearestNeighbors implements the k-nearest neighbours (k-NN) algorithm for solving the classification problems for a specific set of data items.
In the following example, inputs with their corresponding targets are specified in terms of classes ‘0’ or ‘1’. If these values are carefully analysed, the corresponding classes can be mapped. In the dataset of [2, 5], [3, 6], [4, 7], the values in each set are in increasing order and there is a difference of +3, which is assigned to the class ‘0’. Similarly, in [4, 2], [5, 3], [7, 5], the values in each set are decreasing and assigned class ‘1’. This data can be trained using k-NN with the implementation of the train() function.
$input = [[2, 5], [3, 6], [4, 7], [4, 2], [5, 3], [7, 5]]; $target = [‘0’, ‘0’, ‘0’, ‘1’, ‘1’, ‘1’]; $classifier = new KNearestNeighbors(); $classifier->train($input, $target);
For the prediction of new input data, the predict() function is implemented. As in the following example, predict ([5, 7]) is passed as input, the output will be returned as class ‘0’ because the values in [5, 7] are in increasing order and almost of the same behaviour as class ‘0’. The exact difference of +3 is not mandatory, because machine learning approaches make use of results with a higher degree of approximation, probability and optimisation.
$classifier->predict([[10, 6], [1, 3]]); // The function will return [‘1’, ‘0’] depending upon the pattern and behavior of input
Scope of R&D
As there are many applications for which classification and predictive mining can be used, the free and open source libraries can be integrated on the real-time clouds of Red Hat OpenShift, IBM Bluemix, Amazon, Google Apps Engine and many others, depending upon the algorithms to be used. The aspects and logs associated with performance, complexity, security and integrity can be analysed with the implementation of algorithms on real-time clouds.
















Get rid of stereotype & generic designing because we provide modern
looking and appealing website designs & logos for creating your
unique identity in the world of business.