



























































Apache Spark is a data analysis engine based on Hadoop MapReduce, which helps in the quick processing of Big Data. It overcomes the limitations of Hadoop and is emerging as the most popular framework for analysis.
With the advent of new technologies, the data generated by various sources such as social media, Web logs, IoT, etc, is proliferating in petabytes. Traditional algorithms and storage systems aren’t sophisticated enough to cope with this enormous volume of data. Hence, there is a need to address this problem efficiently.
Introducing the Apache Spark engine
Apache Spark is a cluster computing framework built on top of Apache Hadoop. It extends the MapReduce model and allows quick processing of large volumes of data significantly faster, as data persists in-memory. It has fault tolerance, data parallelism capabilities and supports many libraries such as GraphX (for graph processing), MLlib (for machine learning), etc. These features have led to Spark emerging as the most popular platform for Big Data analytics and it being used by the chief players in the tech industry like eBay, Amazon and Yahoo.
Spark was created in 2009 by Matei Zaharia at UC Berkeley’s AMPLab as a lightning fast cluster computing framework. In 2010, it was donated to the Apache Software Foundation under a BSD licence and has since been developed by contributors throughout the world. In November 2014, Zaharia’s enterprise, Databricks, sorted a large dataset in record time by using the Spark engine. Spark 2.0.0 is the latest release, which came out on July 26, 2016.
Hadoop has been widely used due to its scalability, flexibility and the MapReduce model, but it is losing its popularity to Spark since the latter is 100x faster for in-memory computations and 10x faster for disk computations. Data is stored on disk in Hadoop but in Spark, it’s stored in memory, which reduces the IO cost. Hadoop’s MapReduce can only re-use the data by writing it to an external storage and fetching it when needed again. Iterative and interactive jobs need fast responses, but MapReduce isn’t satisfactory due to its replication, disk IO and serialisation. Spark uses RDD (Resilient Distributed Dataset), which allows better fault tolerance than Hadoop, which uses replication. Though Spark is derived from Hadoop, it isn’t a modified version of it. Hadoop is a method to implement Spark, which has its own cluster management system and can run in standalone mode, hence obviating the necessity for the former. Hadoop provides only two functions to Spark—processing by MapReduce and storage using the Hadoop Distributed File System (HDFS). Spark doesn’t replace Hadoop as the two aren’t mutually exclusive. Instead, they complement each other and result in an extremely powerful model.
The power of the Apache Spark engine
Speed: Spark uses in-memory cluster processing, which means it reduces the I/O operations for iterative algorithms as it stores the intermediate data generated in the memory instead of writing it back to the disk. Data can be stored on the RAM of the server machine and, hence, runs 100x quicker in memory and up to 10x faster on disk as compared to Hadoop. Moreover, due to its bottom-up engineering and the usage of RDDs, the fundamental data structure of Spark allows transparent storage of data in memory and persistence to disk only when it’s needed. ‘Lazy evaluation’ is a feature that also contributes to Spark’s speed by delaying the evaluation of any expression or operation until the value is needed by another expression. This avoids repeated evaluation of the same expression, and allows the definition of control flow and potentially infinite sets.
Libraries: Spark is equipped with standard built-in high-level libraries, including compatibility with SQL queries (SparkSQL), machine learning (MLlib), and streaming data and graph processing (GraphX), in addition to the simple MapReduce functionalities of the MR model. These increase the productivity of developers by allowing them to use the functionalities in fewer lines of code, yet create complex workflows. Spark is compatible with real-time processing applications.
Multiple languages: Programmers have the advantage of coding in familiar languages as Spark provides stable APIs in Java, Scala, Python, R and SQL. The Spark SQL component allows the import of structured data and its integration with unstructured data from other sources. Spark has over 100 high-level operators as it is equipped with standard built-in high-level libraries, including compatibility with SQL queries (SparkSQL), machine learning (MLlib), streaming data and graph processing (GraphX) in addition to the simple MapReduce functionalities of the MR model. It can be used in real-time processing applications by applying transformations to semi-structured data with the option of allowing interactive querying within the Spark shell. This dynamic nature has led to it being more popular than Hadoop.
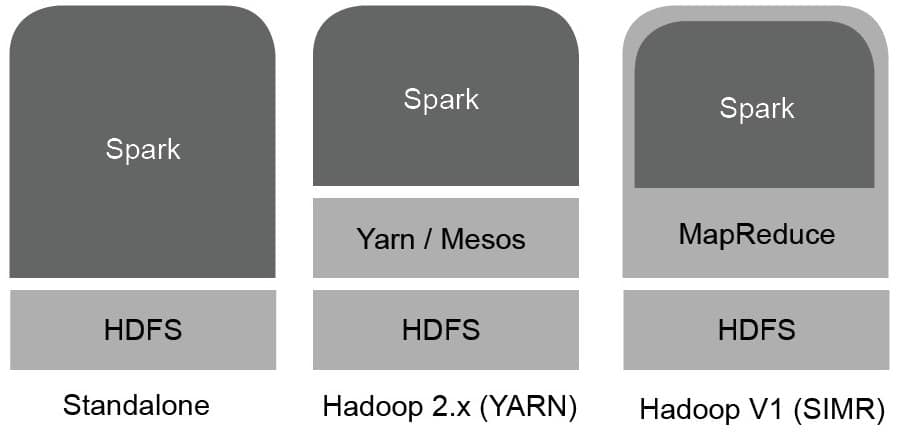
Hadoop support: Big Data and the cloud are synergistic and Spark’s support for cloud technologies is one of its biggest advantages. It is compatible with widely used Big Data frameworks like HDFS, Apache Cassandra, Apache Hbase, Apache Mesos and Amazon S3. Spark, which doesn’t have its own storage system, enhances the Hadoop stack by implementing it in three possible ways: 1) standalone mode, 2) over YARN, or 3) SIMR (Spark in MapReduce). It can also support existing pure Hadoop ecosystems.
MapReduce alternative: Spark can be used instead of MapReduce as it executes jobs in short, micro bursts of 5 seconds or less. It is a faster framework for batch processing and iterative algorithms in comparison to Hadoop-based frameworks like Twitter Storm for live processing.
Configuring Apache Spark on Ubuntu
It is easy to install and configure Apache Spark on Ubuntu. A native Linux system is preferred as it provides the best environment for deployment. Virtual OSs can also be used, but the performance gets compromised when compared to the native versions. Dual OSs work satisfactorily. There are options to use a standalone version or use a version pre-built for Hadoop, which utilises the existing Hadoop components such as HDFS or a version built to be deployed on YARN. The following section will explain how to get Spark 2.0.0 standalone mode running on Ubuntu 14.04 or later.
Installing Java: To install and configure Spark, your machine needs Java. Use the following commands in a terminal to automatically download and update Java:
$sudo apt-add-repository ppa:webupd8team/java $ sudo apt-get update $ sudo apt-get install oracle-java7-installer
You can check for an existing version by typing:
$ java –version
Installing Scala: Spark is written in Scala; so we need it to install the former. Download version 2.10.4 or later from http://www.scala-lang.org/.
Untar the file by using the following command:
$ sudo tar xvf scala-2.10.4.tgz
Add an entry for Scala in the file .bashrc, as follows:
nano ~/.bashrc
At the end of the file, add the path given below to show the location of the Scala file:
export SCALA_HOME=<path-where-scala-file-is-located> export PATH=$SCALA_HOME/bin:$PATH
Then we need to source the changed .bashrc file by using the command given below:
source ~/.bashrc
We can verify the Spark installation by using the following command:
$scala -version
Installing Spark: Download the standalone cluster version of Spark from its website http://spark.apache.org/downloads.html
Then extract the file by typing the following command in the terminal:
$ tar xvf spark-2.0.0-bin-hadoop2.6.tgz
Add entry to .bashrc by:
nano ~/.bashrc
Add the line specifying the location to ~/.bashrc by:
export SPARK_HOME=/home/sapna/spark-2.0.0-bin-hadoop2.6/ export PATH=$PATH:$SPARK_HOME/bin
Then source it by using the command below:
$ source ~/.bashrc
Start Spark services and the shell. Then let’s change the directory by going into Spark’s folder and manually starting the master cluster using the command shown below:
cd spark-2.0.0-bin-hadoop2.6 ./sbin/start-master.sh
After running this, you can view the user interface of the master node by typing the following command in the browser:
http://localhost:8080
You can start the slave node by giving the following command:
./sbin/start-slave.sh <name of slave node to run>
To check if the nodes are running, execute the following:
Jps
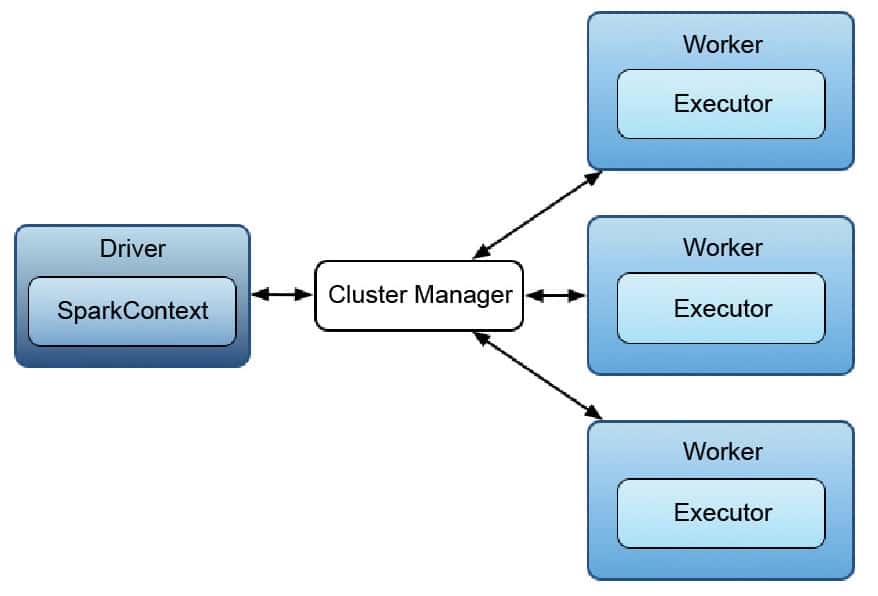
Architecture of the Apache Spark engine
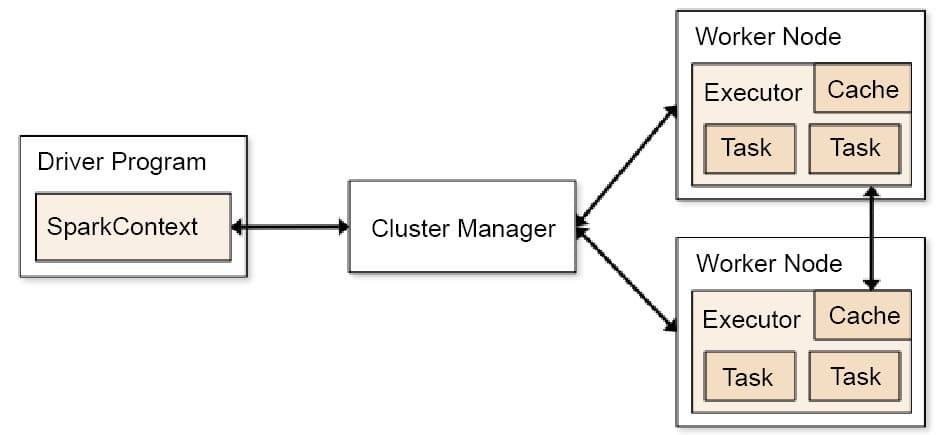
Spark uses a master/worker architecture. There is a driver called the Spark Context object, which interacts with a single coordinator called the master that manages workers in which executors run.
Spark is founded on two chief concepts—the RDD (Resilient Distributed Dataset) and DAG (Directed Acyclic Graph) execution engine. An RDD, a read-only immutable collection of objects, is the basic data structure of Spark. The data is partitioned, and each RDD can be computed on a different node and can be written in many languages. It stores the state of the memory as an object across the jobs and the object is shareable between those jobs. RDD can transform data by mapping or filtering it, or it can perform operations and return values. RDDs can be parallelised and are intrinsically fault-tolerant. They can be created through two methods—by taking an existing collection in your driver application and parallelising it or by creating a reference from an external storage system like HDFS, HBase, AWS, etc. The DAG helps to obviate the multi-staged model of MapReduce which offers processing advantages.
Spark can be deployed in three popular ways to cater to different scenarios. The first way is to use a standalone mode. Here, Spark is placed above HDFS and allocates memory to it manually. All Spark jobs on the clusters are executed with Spark and MapReduce running simultaneously. The second way is to use a cluster management system such as Hadoop YARN (Yet Another Resource Manager), which doesn’t require any pre-installation or root access to integrate with the Hadoop stack or ecosystem. Other components can be externally added on top to increase the functionality. The third way is to use SIMR (Spark in MapReduce) which, in addition to a manager, also executes a Spark job. Spark shell can be used without any administrative authorisation.
The main elements that constitute Spark are: Spark Core, MLlib, GraphX, Spark Streaming and Spark SQL. Spark Core is the basic platform engine that serves as a foundation for building other functionalities. The Spark SQL component, which provides the abstraction called SchemaRDD, which allows the loading, analysis and processing of semi-structured and structured datasets, is built on top of this. Spark Streaming allows live streaming and analysis of data loaded into RDDs as mini-batches. MLlib is an extensive library, which helps to implement machine learning methods on Big Data sets. It is created by a community of programmers from across the world. GraphX is a distributed graph-processing framework, which provides an API for expressing graph computation that can model the user-defined graphs by using the Pregel abstraction API. In addition, GraphX includes a growing collection of graph algorithms and builders to optimise graph analytics tasks.
Spark applications run independently on sets of clusters that are managed by a SparkContext object in the driver program. A SparkContext instance can connect with managers such as Mesos or YARN and can allocate resources to different commodity machines for optimised performance. After allocation, the executors on each job receive the application code and tasks, which are utilised to execute the job. Each Spark application has its own executors which can do multi-threading. Data needs to be stored on external storages for different Spark applications to share it.
Getting started with the Apache Spark engine
The following section explores how to start the Spark engine and get the services started. It will show how to execute existing programs, how to start the client or server and how to launch the shell.
Starting Spark services and the shell
We will change the directory, go into Spark’s folder and manually start the master cluster by using the following command:
cd spark-2.0.0-bin-hadoop2.6 ./sbin/start-master.sh
After running this, you can view the user interface of the master node by typing the following command in the browser:
http://localhost:8080
You can start the slave node by using the following command:
./sbin/start-slave.sh <name of slave node to run>
To check if nodes are running, execute the following:
jps
Running the Spark shell
You can run the Spark shell for Scala using the command given below:
$ bin/spark-shell
You can run the Spark shell for Python by using the following command:
$ bin/pyspark
Submitting an existing application in Spark
First, let us compile a file that contains the code for a program which is to be run in Spark later on:
$ scalac -classpath “spark-core_2.10-2.0.0.jar:/usr/local/spark/lib/spark-assembly-2.0.0-hadoop2.6.0.jar” <file name>
Then, let’s create a JAR file out of the compiled file, as follows:
jar -cvf wordcount.jar SparkWordCount*.class spark-core_2.10-1.3.0.jar/usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jar
Now, submit the JAR file to Spark to run the application, as follows:
$ spark-submit --class <application name> --master local <jar file name>
Writing and executing basic scripts in the Apache Spark engine
Since we have already learnt how to start the shell and submit jobs through it after creating and compiling JAR files, let’s now write and execute a simple WordCount example in Scala to be deployed on Spark.
First, create a simple input.txt file from the sentence given below and put it in the Spark application folder containing all other jar files and program code:
“This is my first small word count program using Spark. I will use a simple MapReduce program made in Scala to count the frequency of each word.”
Next, open the Spark shell:
$ spark-shell
Then make an RDD, which will read the data from our input.txt file. sc is SparkContext object, which is a manager of all the RDDs:
scala> val inputfile = sc.textFile(“input.txt”)
We apply transformations to the data by splitting each line into individual words. Earlier, one line was one entity but now each word is an entity. Next, let’s count the frequency of each word and then reduce it by its key, by adding the frequency of each distinct word, using the code shown below:
scala> val counts = inputfile.flatMap(line => line.split(“ “)).map(word => (word, 1)).reduceByKey(_+_);
We can cache the output for it to persist, as follows:
scala> counts.cache()
Or we can store it to an external text file, as follows:
scala> counts.saveAsTextFile(“output”)
We can check the output as follows:
$ cd output/ $ ls -1
Print the output on the Spark screen, using the command shown below:
$ cat part-00000 $ cat part-00001
Analysing Big Data using the Apache Spark engine
With the advancement in technology, Web servers, machine log files, IoT, social media, user clicks, Web streaming, etc, are all generating petabytes of data, daily. Most of this is semi-structured or unstructured. This Big Data is characterised by high velocity, high volume and high variability; hence, traditional algorithms and processing technologies are unable to cope with it. MapReduce was able to process this data satisfactorily using a cluster of commodity hardware. But the ever-increasing volume of data is exceeding the capability of MapReduce due to the reasons mentioned earlier. Spark was designed as an answer to the limitations of MapReduce. It provides an abstraction of memory for sharing data and for in-memory computing. RDD can be persisted and re-used for other computations. Spark’s multi-platform support, the ability to integrate with Hadoop, and its compatibility with the cloud make it tailor-made for Big Data.
In the real world, Spark is used for many applications. Banks analyse large volumes of data from sources like social media, email, complaint logs, call records, etc, to gain knowledge for credit risk assessment, customer segmentation or targeted advertising. Even credit card fraud can be checked by it. E-commerce sites use the streaming clustering algorithm to analyse real-time transactions for advertising or to recommend products to customers by gaining insights from sources like review forums, comments, social media, etc. Shopify, Alibaba and eBay use these techniques. The healthcare sector benefits from Spark as it enables quick diagnosis and filters out individuals who are at risk. The MyFitnessPal app uses Spark to process the data of all its active users. Spark is widely used in genome sequencing and DNA analysis as millions of strands of chromosomes have to be matched. This task earlier took weeks but now takes only hours. Spark is also being used by the entertainment industry (such as Pinterest, Netflix and Yahoo News) for personalisation and recommendation systems.
Sample Big Data processing using the Apache Spark engine
Let’s look at a simple application for beginners that can process Big Data. Let’s load the dataset of ‘Five Thirty Eight’, a popular US TV show, and perform simple aggregation functions. Download the data for the past 50 years using https://github.com/fivethirtyeight/data/blob/master/daily-show-guests/daily_show_guests.csv.
Create an RDD, read the data and print the first five lines using the following code.
raw_data = sc.textFile(“daily_show_guests.csv”) raw_data.take(5)
Then, split each word by using a map function, as follows:
daily_show = raw_data.map(lambda line: line.split(‘,’)) daily_show.take(5)
Next, define a function to calculate the tally of guests each year, as shown below:
tally = dict() for line in daily_show: year = line[0] if year in tally.keys(): tally[year] = tally[year] + 1 else: tally[year] = 1
Execute the function by using the Reduce transformation, as shown below:
tally = daily_show.map(lambda x: (x[0], 1)) .reduceByKey(lambda x,y: x+y) print(tally) tally.take(tally.count())
Now use a filter function, which segregates according to professions to create an RDD from an existing RDD:
def filter_year(line): if line[0] == ‘YEAR’: return False else: return True filtered_daily_show = daily_show.filter(lambda line: filter_year(line))
Now, execute this filter by doing reduce transformations:
filtered_daily_show.filter(lambda line: line[1] != ‘’) \ .map(lambda line: (line[1].lower(), 1))\ .reduceByKey(lambda x,y: x+y) \ .take(5)
This completes the overview of one of the most promising technologies in the domain of Big Data. Spark’s features and architecture give it an edge over prevailing frameworks such as Hadoop. Spark can be implemented on Hadoop, and its efficiency increases due to the use of both technologies synergistically. Due to its several integrations and adapters, Spark can be combined with other technologies as well. For example, we can use Spark, Kafka and Apache Cassandra together — Kafka can be used for streaming the data, Spark for computation and Cassandra NoSQL database to store the result data. However, Spark is still being developed. It is comparatively a less mature ecosystem and there are a lot of areas, such as security and business integration tools, which need improvement. Nevertheless, Spark is here to stay for a long time.
















[…] like Java, Python. Additionally, there is support for machine learning frameworks such as Apache SparkML, TensorFlow and H2O that all are maintained by the developer […]
What is the 1st and best book to start learning spark with scala as I know hadoop, basic java. Thanking you.
You can start off with :-
Learning Spark: Lightning-Fast Big Data Analysis
Book by Andy Konwinski, Holden Karau, Matei Zaharia, and Patrick Wendell
[…] Spark users have faced the low-level APIs problem while indexing strings and assembling feature vectors. Although Spark is powerful enough to build […]