

























































Named after a flightless New Zealand bird, Weka is a set of machine learning algorithms that can be applied to a data set directly, or called from your own Java code. Weka contains tools for data pre-processing, classification, regression, clustering, association rules, and visualisation.
Machine learning is nothing but a type of artificial intelligence which enables computers to learn the data without help of any explicit programs. Machine learning systems crawl through the data to find the patterns and, when these are found, adjust the program’s actions accordingly.
Data mining analyses the data from different perspectives and summarises it into parcels of useful information. The machine learning method is similar to data mining. The difference is that data mining systems extract the data for human comprehension. Data mining uses machine language to find valuable information from large volumes of data.
Weka
Weka is data mining software that uses a collection of machine learning algorithms. These algorithms can be applied directly to the data or called from the Java code.
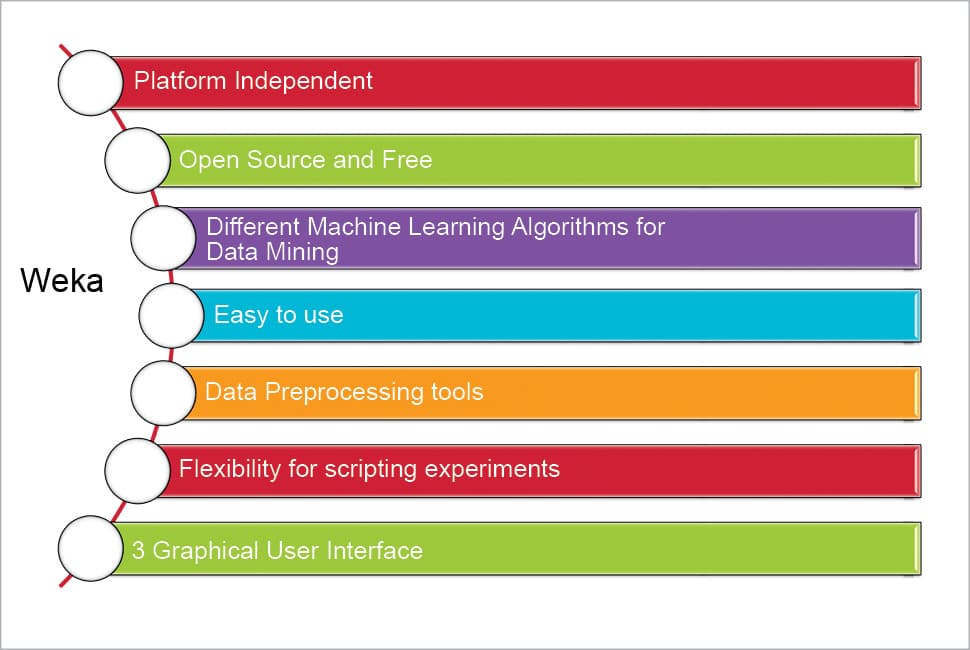
Weka is a collection of tools for:
- Regression
- Clustering
- Association
- Data pre-processing
- Classification
- Visualisation
The features of Weka are shown in Figure 1.
Installation of Weka
You can download Weka from the official website http://www.cs.waikato.ac.nz/ml/weka/.
Execute the following commands at the command prompt to set the Weka environment variable for Java, as follows:
setenv WEKAHOME /usr/local/weka/weka-3-0-2 setenv CLASSPATH $WEKAHOME/weka.jar:$CLASSPATH
Once the download is completed, run the exe file and choose the default set-up.
Weka application interfaces
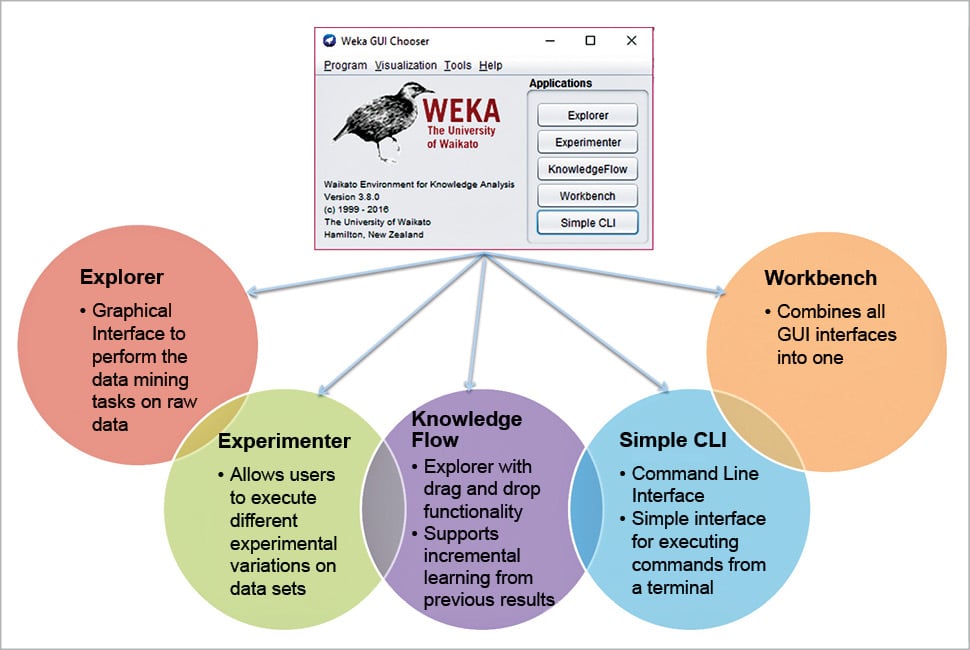
There are totally five application interfaces available for Weka. When we open Weka, it will start the Weka GUI Chooser screen from where we can open the Weka application interface.
The Weka GUI screen and the available application interfaces are seen in Figure 2.

Weka data formats
Weka uses the Attribute Relation File Format for data analysis, by default. But listed below are some formats that Weka supports, from where data can be imported:
- CSV
- ARFF
- Database using ODBC
Attribute Relation File Format (ARFF)
This has two parts:
1) The header section defines the relation (data set) name, attribute name and the type.
2) The data section lists the data instances.
An ARFF file requires the declaration of the relation, attribute and data. Figure 3 is an example of an ARFF file.
· @relation: This is the first line in any ARFF file, written in the header section, followed by the relation/data set name. The relation name must be a string and if it contains spaces, then it should be enclosed between quotes.
· @attribute: These are declared with their names and the type or range in the header section. Weka supports the following data types for attributes:
- Numeric
- <nominal-specification>
- String
- date
- @data – Defined in the Data section followed by the list of all data segments
Weka Explorer
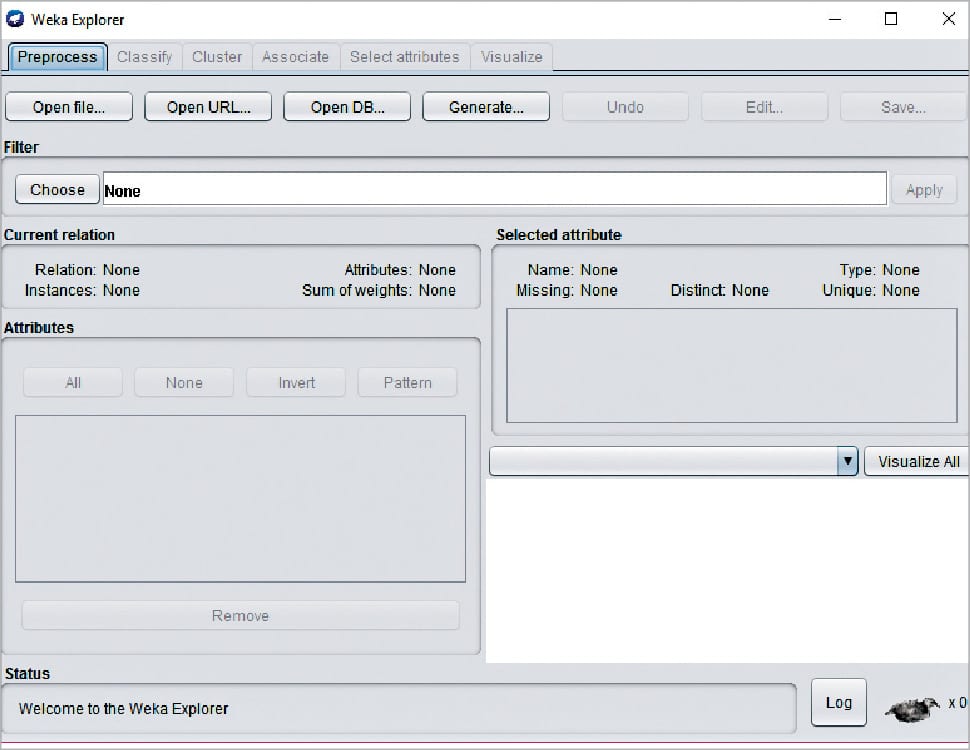
The Weka Explorer is illustrated in Figure 4 and contains a total of six tabs.
The tabs are as follows.
1) Preprocess: This allows us to choose the data file.
2) Classify: This allows us to apply and experiment with different algorithms on preprocessed data files.
3) Cluster: This allows us to apply different clustering tools, which identify clusters within the data file.
4) Association: This allows us to apply association rules, which identify the association within the data.
5) Select attributes: These allow us to see the changes on the inclusion and exclusion of attributes from the experiment.
6) Visualize: This allows us to see the possible visualisation produced on the data set in a 2D format, in scatter plot and bar graph output.
The user cannot move between the different tabs until the initial preprocessing of the data set has been completed.
Preprocessing
Data preprocessing is a must. There are three ways to inject the data for preprocessing:
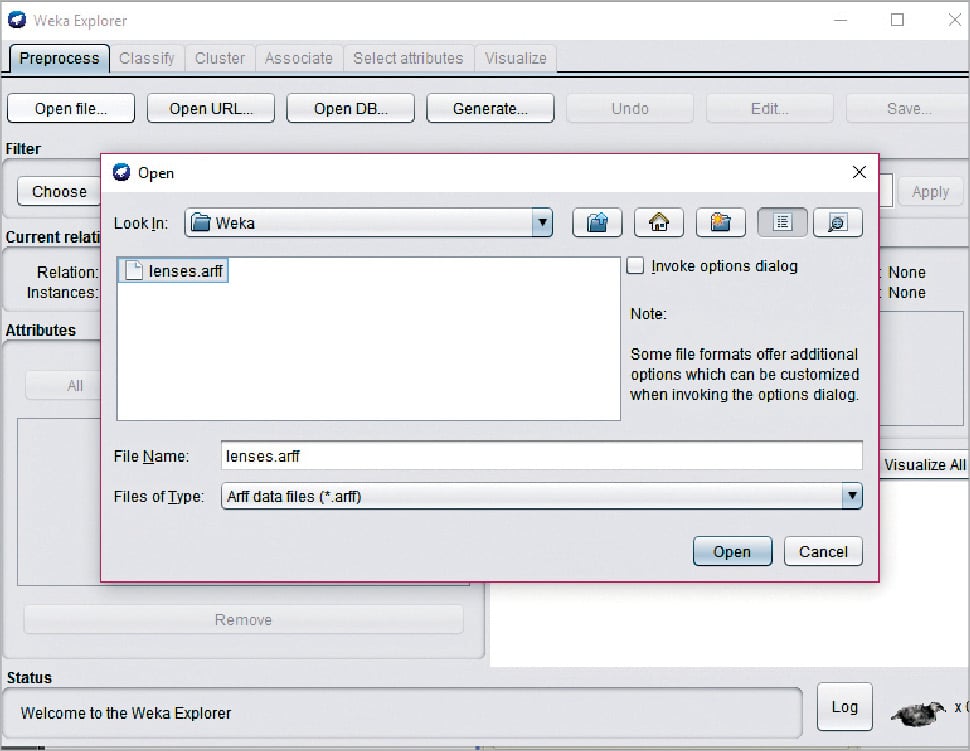
- Open File – enables the user to select the file from the local machine
- Open URL – enables the user to select the data file from different locations
- pen Database – enables users to retrieve a data file from a database source
A screen for selecting a file from the local machine to be preprocessed is shown in Figure 5.
After loading the data in Explorer, we can refine the data by selecting different options. We can also select or remove the attributes as per our need and even apply filters on data to refine the result.
Classification
To predict nominal or numeric quantities, we have classifiers in Weka. Available learning schemes are decision-trees and lists, support vector machines, instance-based classifiers, logistic regression and Bayes’ nets. Once the data has been loaded, all the tabs are enabled. Based on the requirements and by trial and error, we can find out the most suitable algorithm to produce an easily understandable representation of data.
Before running any classification algorithm, we need to set test options. Available test options are listed below.
Use training set: Evaluation is based on how well it can predict the class of the instances it was trained on.
Supplied training set: Evaluation is based on how well it can predict the class of a set of instances loaded from a file.
Cross-validation: Evaluation is based on cross-validation by using the number of folds entered in the ‘Folds’ text field.
Split percentage: Evaluation is based on how well it can predict a certain percentage of the data, held out for testing by using the values entered in the ‘%’ field.
To classify the data set based on the characteristics of attributes, Weka uses classifiers.
Clustering
The cluster tab enables the user to identify similarities or groups of occurrences within the data set. Clustering can provide data for the user to analyse. The training set, percentage split, supplied test set and classes are used for clustering, for which the user can ignore some attributes from the data set, based on the requirements. Available clustering schemes in Weka are k-Means, EM, Cobweb, X-means and FarthestFirst.
Association
The only available scheme for association in Weka is the Apriori algorithm. It identifies statistical dependencies between clusters of attributes, and only works with discrete data. The Apriori algorithm computes all the rules having minimum support and exceeding a given confidence level.
Attribute selection
Attribute selection crawls through all possible combinations of attributes in the data to decide which of these will best fit the desired calculation—which subset of attributes works best for prediction. The attribute selection method contains two parts.
- Search method: Best-first, forward selection, random, exhaustive, genetic algorithm, ranking algorithm
- Evaluation method: Correlation-based, wrapper, information gain, chi-squared
All the available attributes are used in the evaluation of the data set by default. But it enables users to exclude some of them if they want to.
Visualisation
The user can see the final piece of the puzzle, derived throughout the process. It allows users to visualise a 2D representation of data, and is used to determine the difficulty of the learning problem. We can visualise single attributes (1D) and pairs of attributes (2D), and rotate 3D visualisations in Weka. It has the Jitter option to deal with nominal attributes and to detect ‘hidden’ data points.















