

In today’s world, there is an explosion of data from social media and other sources. Enterprises carefully harvest this data and store it for meaningful reuse. Handling such vast quantities of data requires specialised tools and techniques. Big Data is here to stay as an important part of our lives.
Currently, logging in to our Facebook account, uploading pictures on Instagram or taking a peek at the various products on Flipkart, Amazon or Snapdeal has become part of our daily routine. We feel the day is incomplete when we don’t see our messages on Whatsapp. The tech savvy world is being ruled by online social media like FB, Whatsapp, Twitter, etc. So have you ever given a thought to the peta and exabytes of data being generated daily by social media or various enterprise applications? According to Wikipedia, 2.5 exabytes of data are created every day by various online apps. It becomes quite difficult to manage and play around with such a large amount of data.
Big Data, as the name itself suggests, refers to the huge amounts of data that are difficult to capture, manage or process, even with the help of various software tools. Big Data requires the use of various techniques and technologies such as predictive user behaviour or other advanced data analytics to obtain useful insights from them, which can be leveraged further. According to Wikipedia, Big Data is a term for data sets that are so large or complex that traditional data processing applications are inadequate. It needs to be acquired, organised and analysed computationally to identify certain patterns or trends that further facilitate the processing, updating or management of such huge amounts of data.
The five Vs of Big Data
We can identify Big Data with the help of the following characteristics:
1. Volume: Big Data is characterised largely on the basis of the quantity of generated and stored data.
2. Variety: The type and nature of the Big Data helps people who analyse it to effectively use the resulting insights.
3. Velocity: Big Data is also identified by the rate at which the data is generated and processed to meet various demands.
4. Variability: We can consider a data set to be Big Data if it’s not consistent, hampering various processes that are used to handle and manage it.
5. Veracity: In some sets of data, the quality varies greatly and it becomes a challenging task to analyse such sets, as this leads to a lot of confusion during analysis.
The various challenges associated with such large amounts of data include:
1. Searching, sharing and transferring
2. Curating the data
3. Analysis and capture
4. Storage, updation and querying
5. Information privacy
How enterprises began leveraging Big Data
Considering the tremendous increase in the demand for various online enterprise applications nowadays, the present era could well be named the Enterprise Era. This is best illustrated by the fact that around 1 million transactions per hour are being tracked by Walmart. This statistic makes one ponder over how difficult it has become for various enterprise applications to track and use such mammoth amounts of unstructured data.
Clearly, effectively using data can be a difficult task, specially with the increasing number of new data sources, the requirements for fresh data, and the need for increased processing speed. Hence, for advanced operational efficiencies and accelerated business growth, enterprises need to address and overcome these challenges. Various Big Data techniques and methodologies are being adopted to process and get the Right Data (that which is sufficient and appropriate for use) out of such unstructured data sets.
In the recent past, many enterprises have invested heavily on developing various data warehouses. These can serve as the central data system to report, extract, transform and load different processes, and also ingest data from different databases and other sources—both inside and outside the enterprise. Since the variety, velocity and volume of data continues to increase, it is overloading such expensive enterprise data warehouses, causing a significant processing burden.
To get rid of this bottleneck, organisations are opting for different open source tools like Hadoop to offload data warehouse processing functions. Hadoop can help organisations lower costs and turn highly efficient if it’s being used along with various data warehouses. However, as Hadoop requires some special skillsets to deploy it, organisations have started trying out other alternatives. A solution developed by the combined efforts of Dell, Intel, Cloudera and Syncsort works on the use-case driven Hadoop Reference Architecture. This technology simplifies data processing with the help of an architecture, which helps users to optimise an already existing data warehouse. This offloading solution provides a Hadoop environment using Cloudera Enterprise software. The Cloudera Distribution of Hadoop (CDH) delivers all the core elements of Hadoop, like scalable storage and distributed computing. It allows users to reduce the Hadoop deployment period to just several weeks, develop Hadoop jobs within hours, and become completely productive. CDH also ensures high availability, security and integration with the large set of other tools.
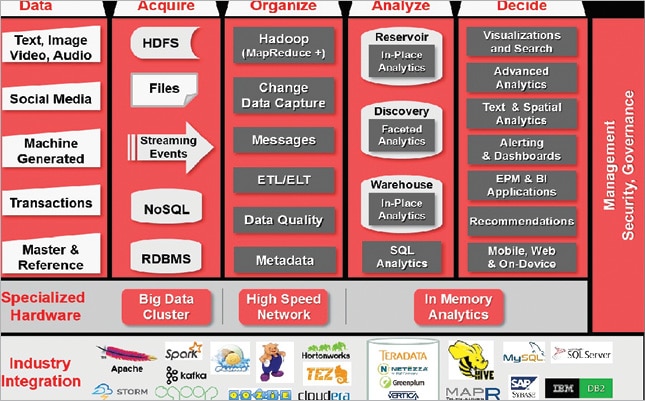
The Big Data enterprise model
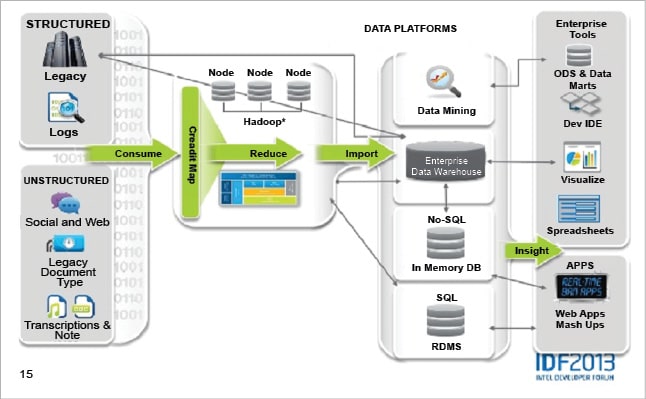
Let’s have an overview of the general Big Data model that enterprises are implementing, which mainly consist of several intermediate systems or processes that are featured below.
Data source: These are the datasets on which different Big Data techniques are implemented. They can exist in an unstructured, semi-structured or structured format. There are unstructured datasets which are extracted from several social media applications in the form of images, audio/video clips or text. The semi-structured datasets are generated by different machines and require less effort to convert them to the structured form. Some data sets are already in the structured form, as in the case of transaction information from several online applications or other master data.
Acquire: After various types of data sets are taken from several sources and inserted, they can either be written straight away to real-time memory processes or can be written as messages to disk, database transactions or files. Once they are received, there are various options for the persistence of these data. The data can either be written to several file systems, to RDBMS or even various distributed-clustered systems like NoSQL and Hadoop Distributed File System.
Organise: This is the process of organising various acquired data sets so that they are in the appropriate form to be analysed further. The quality and format of data is changed at this stage by using various techniques to quickly evaluate unstructured data, like running the map-reduce process (Hadoop) in batch or map-reduce process (Spark) in memory. There are other evaluation options available for real-time streaming data as well. These are basically extensive processes which enable an open ingest, data warehouse, data reservoir and analytical model. They extend across all types of data and domains by managing the bi-directional gap between the new and traditional data processing environments. One of their most important features is that they meet the criteria of the four Vs — a large volume and velocity, a variety of data sets, and they also help in finding value wherever our analytics operate. In addition to that, they also provide all sorts of data quality services, which help in maintaining metadata and keeping a track of transformation lineage as well.
Analyse: After the data sets are converted to an organised form, they are further analysed. So the processing output of Big Data, after having been converted from low density data to high density data, is loaded into a foundation data layer. Apart from the foundation data layer, it can also be loaded to various data warehouses, data discovery labs (sets of data stores, processing engines and their analysis tools), data marts or back into the reservoir. As the discovery lab requires fast connections to the event processing, data reservoir and data warehouse, a high speed network like InfiniBand is required for data transport. This is where the reduction-results are basically loaded from processing the output of Big Data into the data warehouse for further analysis.
We can see that both the reservoir and the data warehouse offer in-situ analytics, which indicates that analytical processing can take place at the source system without the extra step needed to move the data to some other analytical environment. SQL analytics allows for all sorts of simple and complex analytical queries at each data store, independently. Hence, it is the point where the performance of the system plays a big role as the faster the data is processed or analysed, the quicker is the decision-making process. There are many options like columnar databases, in-memory databases or flash memory, using which performance can be improved by several orders of magnitude.
Decide: This is where the various decision-making processes take place by using several advanced techniques in order to come to a final outcome. This layer consists of several real-time, interactive and data modelling tools. They are able to query, report and model data while leaving the large amount of data in place. These tools include different advanced analytics, in-reservoir and in-database statistical analysis, advanced visualisation, as well as the traditional components such as reports, alerts, dashboards and queries.
Significance and role of Big Data for enterprise applications
Big Data has been really playing quite a significant role in a number of enterprise applications, which is why large enterprises are spending millions on it. Let’s have a look at a few scenarios where these enterprises are benefiting by implementing Big Data techniques.
1. The analysis and distillation of Big Data in combination with various traditional enterprise data, leads to the development of a more thorough and insightful understanding of the business, for enterprises. It can lead to greater productivity, greater innovation and a stronger competitive position.
2. Big Data plays a much more important role in healthcare services. It helps in the management of chronic or other long-term conditions of patients by using in-home monitoring devices, which measure vital signs and check the progress of patients to improve their health and reduce both hospital admissions and visits to doctors’ clinics.
3. Manufacturing companies also deploy sensors in their products to gather data remotely, as in the case of General Motor’s OnStar or Renault’s R-Link. These help in delivering communications, navigation and security services. They also reveal usage patterns, rates of failure and other such opportunities for product improvement that can further reduce assembly and development costs.
4. The phenomenal increase in the use of smartphones and other GPS devices provides advertisers an opportunity to target their consumers when they are in close proximity to a store, restaurant or a coffee shop. Retailers know the avid buyers of their products better. The use of various social media and Web log files from their e-commerce sites helps them get information about those who didn’t buy their products and also the reason for why they chose not to. This can lead to more effective micro, customer-targeted marketing campaigns as well as improved supply chain efficiencies, as a result of more accurate demand planning.
5. Finally, different social media websites like Facebook, Instagram, Twitter and LinkedIn wouldn’t have existed without Big Data. The personalised experience provided by them to their different users can only be delivered by storing and using all the available data about that user or member.
How secure is Big Data for enterprise apps?
As it plays around with all sorts of significant data belonging to several organisations which may or may not be related to each other, or their users, it is very important that Big Data should have a high grade of security so that there is no fear among the several enterprises implementing it. Big Data basically provides a comprehensive data security approach.
1. It ensures that the right people (internal or external) get access to the appropriate information and data at the right time and at the right place, through the right channel (typically using Kerberos).
2. High security prevents malicious attacks and it also protects the information assets of the organisation by encrypting (using Cloudera Navigator Encrypt) and securing the data while it is in motion or at rest.
3. It also enables all organisations to separate their different roles and responsibilities, and protect all sensitive data without compromising on the privileged user access like administration of DBAs, etc, using various data masking and subset techniques.
4. It also extends auditing, monitoring and compliance reporting across all traditional data management to the big data systems.
Surprising statistics
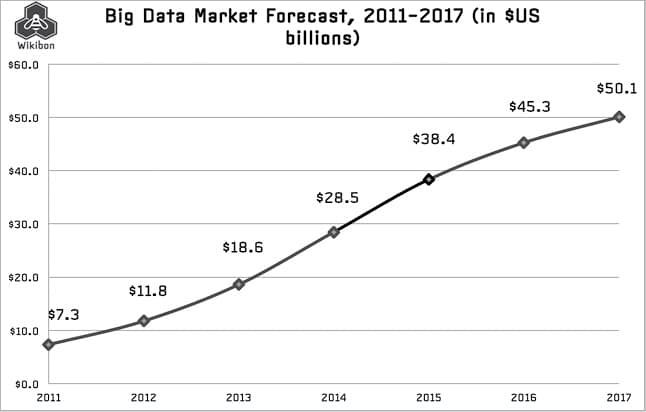
- Ninety per cent of the world’s data has been created in the last two years, and Big Data is projected to grow into a US$ 50 billion market by 2017, up from US$ 12 billion in 2012.
- Seventy per cent of the digital universe (900 exabytes) is being generated by users.
- Enterprises store 80 per cent of all their data.
- The White House administration is investing US$ 200 million in Big Data research projects.
- China will account for one-fifth of the world’s data by 2020.
- A 10 per cent increase in data accessibility translates into an additional US$ 65.7 billion in net income for a typical Fortune 1000 company.
According to Tom Peters, a best selling author of business management books, “Organisations that do not understand the overwhelming importance of managing data and information as tangible assets in the new economy, will not survive.” Hence, the Big Data promise has really motivated businesses and enterprises to invest. We need to continue researching and designing new technologies and techniques to provide a fast and reliable path for various businesses to adopt Big Data. We need to keep improving our skills and managing various open source tools and technologies to leverage the best Big Data capabilities. This will help various enterprises to manage the increasing data sets and use them effectively.



Good and informative post on Big Data and enterprise. Although now many enterprise owners started hiring Data analytics specialist for those reasons now students are taking this course from platforms like “ExcelR Solutions”.
Nice article
I really liked your article. Its good to read article like this. You’ve mentioned 5 Vs of Big Data i.e Volume, Variety, Velocity, Variability and Veracity, I was aware about first 3 but last two i didn’t knew about that. In volume, companies get a large volume of data from various sources like social media channels, online business transactions, online filling forms, machine to machine sensor data and much more. This large volume of data will help you to understand the consumer behavior and market conditions. In variety, there is a variety of forms the companies will receive the data and they should be dealt in a proper manner. In Velocity, the data is coming to the organizations quickly and they need to format and use it quickly too or they will be left behind. Hence, the tools should be employed to make the data more readable in no time. If you’d liked to know more about Big data stuff you can follow this URL for sure: https://goo.gl/erxz9j