


The buzzwords these days are Big Data and Hadoop, which is there to tame it. We know that Hadoop has three components, namely HDFS, MapReduce and Yarn. HDFS stands for the Hadoop Distributed File System, which is used to store data across machines in the form of blocks, across the cluster. MapReduce is a programming model that can be used to write our business logic and fetch the required data, while Yarn acts as an interface between HDFS and other applications like Spark, HBase, etc. What we dont know is that Hadoop uses many other applications which help in its optimal performance and utilisation. In this article, I will outline the five pillars of Hadoop that make it powerful enough to operate on Big Data.
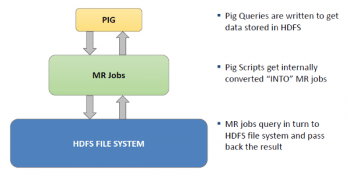
Pig
This is a platform for analysing large data sets, which consists of a high-level language that expresses data analysis programs, coupled with infrastructure for evaluating these programs. Pig is a high level language that mainly works on semi-structured data like log files. It supports the language called Pig Latin. A query planner compiles queries written in Pig Latin into maps and reduces, which are then executed on a Hadoop cluster. Using Pig, you can create your own function to do special processing. In simple MapReduce, it is really tough to write the joins between tables. This is easy in Pig because it is best at joining data sets, sorting data sets, filtering data, grouping by methods and more specifically, you can write user-defined functions (UDFs). The MapReduce programming model can be thought of as composed of three distinct phases, i.e., processing of input records, forming groups of related records and processing groups into outputs. In MapReduce, the first two of these steps is handled by the mapper, and the third step is handled by the reducer. Pig Latin exposes explicit primitives that perform actions from each phase. These primitives can be composed and reordered. Pig works in two modesthe local mode and the Hadoop mode. Local mode uses a single JVM and works on the local file system, whereas the Hadoop mode or MapReduce mode renders Pig Latin into MapReduce jobs and executes them on the cluster.
Hive
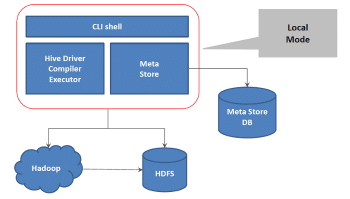
Hive is the data warehouse of Hadoop. Those who dont have a Java background and know SQL queries, find it difficult to write MapReduce jobs in Java. To address this problem, Hive was developed. Using Hive, queries are written which get compiled to MapReduce jobs at the backend. This quickens the process as writing queries is faster than writing code. Moreover, Hive supports DDLs like create table, create view, create index and DMLs like select, where clause, group by, order by and joins. The point to remember is that Hive is not an RDBMS; it should be used for batch processing and not OLTP. Hive has its default metastore, which contains the location of table files, table definitions, storage formats, row formats, etc. Hive query is called HQL (Hive Query Language). Derby is the default database for Hive.
Sqoop
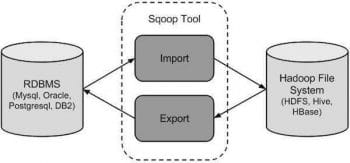
If you have data in some other RDBMS database, like Oracle or MySQL, and now want to move to using Hadoop, you have to move your data to HDFS; this is when Sqoop comes handy. Sqoop is an open source tool used for data interaction between traditional RDBMS and the Hadoop environment. Using Sqoop, data can be moved into HDFS, Hive and HBase from MySQL, PostgreSQL, Oracle, SQL Server or DB2, and vice versa. It is used widely in the industry, as it is the first Apache product to be used from the minute you decide to move from a relational DB to the Hadoop ecosystem.
Sqoop works in three steps. In the first step, it sends the request to the relational DB to return the metadata information about the table (metadata here is the data about the table in the relational DB). In the second step, Sqoop generates the Java classes from the received information, for which Java must be installed in the system. In the final step, a jar is made out of the compiled files. Sqoop needs to have a primary key to work best, but do not worry if your table structure inherently doesnt have it; it will be created for you but without affecting your tables metadata structure.
HBase
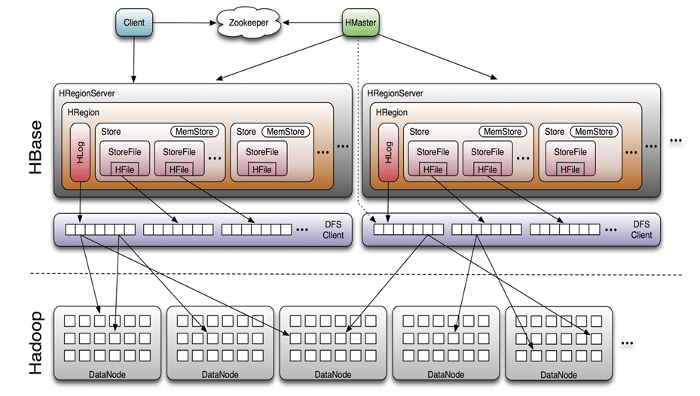
HBase is a distributed column oriented database built on top of HDFS. It is the Hadoop application to use when you need real-time read/write random access to a very large data set. HBase provides APIs that enable development in practically any programming language, and is well suited for sparse data sets. It is written in Java and doesnt enforce relationships within the data. The key point in HBase is that it doesnt care about data types, storing an integer in one row and a string in another, in the same column. It stores a key value pair and stores versioned data. The HBase shell is written with JRuby (the Ruby implementation of JRE) wrapping the Java client API (i.e., one can access Java libraries). HBase runs in three different modes: standalone (running in a single JVM on a single machine), pseudo-distributed (running multiple JVMs on a single machine), and full-distributed (running multiple JVMs on multiple machines).
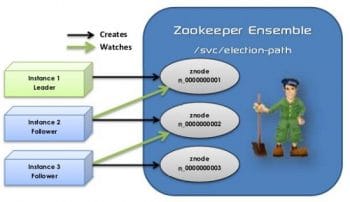
Zookeeper
This is a distributed coordination service for distributed applications. Problems like centralised configuration, synchronisation, partial failures, deadlocks, race conditions and networking are all solved with Zookeeper. It actually handles the nitty-gritty of distributed application development on the Hadoop ecosystem so that the developer can focus on functionality. Zookeper always has an odd number of nodes in the cluster as the selection of the master is via voting. Zookeper has a leader, follower and observer. In the leader, the writes are quorum based and are committed by followers. The followers forward the writes to the leader. Only one leader can write and commit to a file, and all the requests come to the leader via the followers. In case the leader goes down, voting is done among followers to select the leader. Observers just observe the results of votes but never take part in the voting process.


