































































Hadoop is an Apache open source software library written completely in Java, designed to deliver a distributed file system (HDFS) and a method for distributed computation called MapReduce. It can scale up from single servers to thousands of machines.
It provides a framework that allows distributed processing of large sets of data across clusters of computers using simple programming models.
Hadoop implements MapReduce, which runs in two phases: the map phase and the reduce phase. The input to these computations is the data set of key/pair values. In short, the application is divided into many small fragments, each of which may be assigned to the map task. These map tasks are distributed and executed on any node in the cluster. If the nodes fail during the computation process, the tasks assigned to them are redistributed among the remaining nodes.
The Apache Hadoop project includes the following modules:
Hadoop Common: The common utilities that support the other Hadoop modules.
Hadoop Distributed File System (HDFS): A distributed file system that provides high-throughput access to application data.
Hadoop Yarn: A framework for job scheduling and cluster resource management.
Hadoop MapReduce: A yarn-based system for parallel processing of large data sets.
Hadoop deployment methods
Here is a list of the methods used to deploy Hadoop.
Standalone: In this mode, there are no daemons running; everything runs as in a single JVM. This mode is suitable for running the MapReduce program during development, as it is easy to test and debug.
Pseudo-distributed: The Hadoop daemon process runs on a local machine simulating a cluster on a small scale.
Fully distributed: Here, Hadoop runs on a cluster of machines providing a production environment.
This article focuses on introducing Hadoop, and deploying single-node pseudo-distributed Hadoop on a Windows platform.
Prerequisite software or tools for running Hadoop on Windows
You will need the following software to run Hadoop on Windows.
Supported Windows OSs: Hadoop supports Windows Server 2008 and Windows Server 2008 R2, Windows Vista and Windows 7. For installation purposes we are going to make use of Windows 7 Edition and JDK.
As Hadoop is written in Java, we will need to install Oracle JDK 1.6 or higher. Download Java from the link given in References [1] at the end of this article, and install it to the default location.
Windows SDK: Download and install Windows SDK 7 from the link given in References [2]. Windows SDK provides the tools, compilers, headers and libraries that are necessary to run Hadoop.
Cygwin: Hadoop requires UNIX command line tools like Cygwin or GnuWin32. Download and install Cygwin from the link given in References [3], to its default location C:\cygwin64 and make sure to select the openssh package and its associated prerequisites from the Select packages tab.
Maven and the Protocol buffer: Install Maven 3.0 or later and the Protocol buffer 2.5.0 into the C:\maven and C:\protobuff directories, respectively.
Setting environment variables
Navigate to System properties—> Advanced —> Environment Variables. Add environment variables JAVA_HOME, M2_HOME (for Maven) and Platform (x64 or Win32 depending on the system architecture).
Note that the variable name, Platform, is case sensitive and values will be x64 or Win32 for 64-bit and 32-bit systems. Edit the path variable under System variables to add the following: C:\cygwin64\bin;C:\cygwin64\usr\sbin;C:\maven\bin; C:\protobuf
The dos and donts
Given below are some of the issues usually faced while installing Hadoop on Windows.
If the JAVA_HOME environment variable is set improperly, Hadoop will not run. Set environment variables properly for JDK, Maven, Cygwin and Protobuffer. If you still get a JAVA_HOME not set properly error, then edit the C:\hadoop\bin\hadoop-env.cmd file, locate set JAVA_HOME = and provide the JDK path (with no spaces).
Do not use the Hadoop binary, as it is bereft of Windowsutils.exe and some Hadoop.dll files. Native IO is mandatory on Windows and without it the Hadoop installation will not work on Windows. Instead, build from the source code using Maven. It will download all the required components.
Download Hadoop from the link in References [4]. Building from the source code requires an active Internet connection the first time.
Building and configuring Hadoop on Windows
Select Start —> All Programs —> Microsoft Windows SDK v7.1 and open the Windows SDK 7 command prompt as the administrator. Change the directory to C:\hadoop (if it doesnt exist, create it). Run the command prompt:
C:\Program Files\Microsoft SDKs\Windows\v7.1>cd c:\hadoop C:\hadoop>mvn package -Pdist,native-win -DskipTests Dtar
Note: The above step requires an active Internet connection because Maven will download all the dependencies. A successful build will generate a native binary package C:\hadoop\hadoop-dist\target\hadoop-2.2.0.tar.gz directory. Extract hadoop-2.2.0.tar.gz under C:\hdp.
Starting a single node installation: If the build is successful, check out which Hadoop version by running the following command:
C:\hadoop>hadoop version
Startup scripts: The C:\hdp\bin directory contains the scripts used to launch Hadoop DFS and MapReduce daemons.
start-dfs.cmd: Starts the Hadoop DFS daemons, the namenode and datanode.
start-mapred.cmd: Starts the Hadoop MapReduce daemons, the jobtracker and tasktrackers.
start-all cmd: Starts all Hadoop daemons, the namenode, datanode, the jobtracker and tasktrackers.
start-dfs.cmd: Starts the Hadoop DFS daemons, the namenode and datanode. Use this before start-mapred.sh
start-mapred.cmd: Starts the Hadoop MapReduce daemons, the jobtracker and tasktrackers.
start:all.cmd – Starts all Hadoop daemons, the namenode, datanode, the jobtracker and tasktrackers.
The following section contains details on how to configure Hadoop on Windows. Assuming the install directory is C:\hdp, run the command C:\hadoop> cd C:\hdp\etc\hadoop\
Edit the file hadoop-env.cmd (which contains the environment variable settings used by Hadoop) in Notepad++ and add the following lines at the end of the file. Run the command prompt:
set HADOOP_PREFIX=c:\hdp set HADOOP_CONF_DIR=C:\hdp\etc\hdp set YARN_CONF_DIR=C:\hdp\etc\hadoop set PATH=%PATH%;C:\hdp\bin
Before we get started with setting Hadoop environment variables and running Hadoop daemons, we need to configure the following files: core-site.xml, hdfs-site.xml, yarn-site.xml mapred-site.xml and the slave files located in C:\hdp\etc\hadoop. The minimum configuration settings are given below.
Edit or create the file C:\hdp\etc\hadoop\core-site.xml (all Hadoop services and clients use this file to locate namenode; it contains the name of the default file system) and make sure it has the following configuration key:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
Edit or create the file C:\hdp\etc\hadoop\hdfs-site.xml (HDFS services use this file and it contains HTTP addresses for namenode and datanode) and add the following configuration key:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/hdp/data/dfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/hdp/data/dfs/datanode</value> </property> </configuration>
Note that if namenode and datanode directories in the path C:\hdp\data\dfs\ are not present, you must create them.
Edit or create the file C:\hdp\etc\hadoop\slaves. (This file lists the hosts, one per line, where the Hadoop slave daemons datanode and tasktrackers will run. By default, this contains the single entry localhost.) Make sure it has the following entry:
localhost
Edit or create C:\hdp\etc\hadoop\mapred-site.xml (contains the framework for executing MapReduce jobs) and add the following entries:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Finally, edit or create yarn-site.xml and add the following entries:
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.application.classpath</name> <value> %HADOOP_HOME%\etc\hadoop, %HADOOP_HOME%\share\hadoop\common\*, %HADOOP_HOME%\share\hadoop\common\lib\*, %HADOOP_HOME%\share\hadoop\mapreduce\*, %HADOOP_HOME%\share\hadoop\mapreduce\lib\*, %HADOOP_HOME%\share\hadoop\hdfs\*, %HADOOP_HOME%\share\hadoop\hdfs\lib\*, %HADOOP_HOME%\share\hadoop\yarn\*, %HADOOP_HOME%\share\hadoop\yarn\lib\* </value> </property> </configuration>
Initialising environment variables
Once all four files are configured, run hadoop-env.cmd and format the namenode file system. Run the following command prompt:
C:\hdp\etc\hadoop>hadoop-env.cmd C:\hdp\etc\hadoop>C:\hdp\bin\hdfs namenode -format
The output should be something like the message above along with: \hadoop\data\dfs\namenode has been successfully formatted
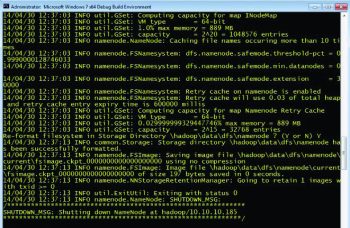
Starting HDFS daemons
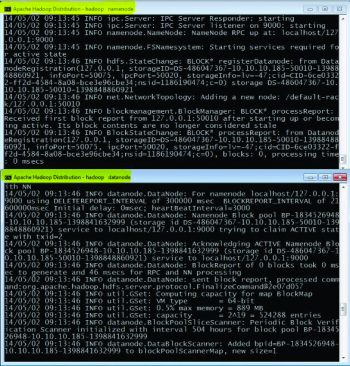
Start namenode and datanode on the localhost by running the following command prompt:
C:\hdp\sbin>start-dfs.cmd
Two command prompts named namenode and datanode will open (Figure 2).
Start MapReduce or Yarn with the following command prompt:
C:\hdp\sbin>start-yarn.cmd Starting yarn daemon
Two command prompts will open, named yarn nodemanager and yarn resourcemanager,
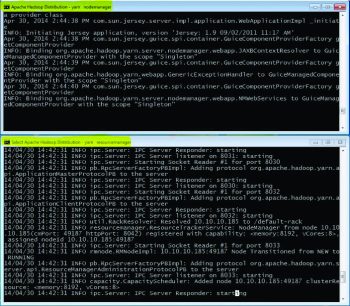
Verifying the installation
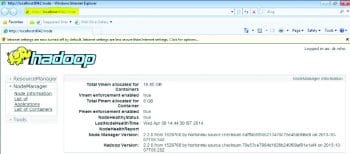
If the entire configuration and installation is successful, then open Internet Explorer to run Resource Manager and Node Manager at http://localhost:8042 and Namenode at http://localhost:50070.
What Hadoop is not!
Hadoop is not a replacement for a database or a SAN file system.
It is not a substitute for a database: Hadoop does not index files but, instead, it stores data in files. In order to search for something, we have to run a MapReduce job, which goes through all data. Hadoop is suitable in a scenario where the data is too vast to be handled by a database.
MapReduce is not always the best algorithm: MapReduce is a simple functional programming operation and it can be applied, in parallel, to gigabytes or terabytes of data. For that parallelism, you need to have each MR operation independent from all the others.
For more information refer to the Apache Hadoop link in Reference [5]
References
[1] http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
[2] http://www.microsoft.com/en-in/download/details.aspx?id=8442
[3] http://cygwin.com/setup-x86_64.exe
[4] http://www.apache.org/dist/hadoop/core/hadoop-2.2.0/hadoop-2.2.0-src.tar.gz
[5] http://wiki.apache.org/hadoop/HadoopIsNot
[6] http://hadoop.apache.org/
[7] https://svn.apache.org/viewvc/hadoop/common/branches/branch-2/BUILDING.txt?view=markup
[8] https://wiki.apache.org/hadoop/Hadoop2OnWindows
[9] http://en.wikipedia.org/wiki/Apache_Hadoop

















Hello, I am trying to execute the wordcount example and I get a
“Diagnostics: Not able to find a working directory for Cuser” error. How
can configure the local working directory to avoid this error?
useful stuff thanks.
one question regarding env variables: when you add JAVA_HOME, M2_HOME etc what values do you assign to them? is it C:cygwin64bin;C:cygwin64usrsbin;C:mavenbin; C:protobuf?
Some details will be appreciated.
In this section there is a big blunder . Building and configuring Hadoop on Windows
Illegal argument Dtar
C:\hadoop>mvn package -Pdist,native-win -DskipTests Dtar
it should be -Dtar