

























































Regular expressions contain a series of characters that define a pattern of text to be matched. Let’s use Python for exploring the different things that regular expressions can do.
Regular expressions have become an integral part of natural language processing (NLP) and are very useful in the fields of text processing, information extraction and more. LLMs and machine learning models are being used today for tasks that can be easily done using regular expressions (regex). In fact, regex can even be used for many daily tasks in software development.
A regex is a special sequence of characters that is used to extract part of a string, or detect a particular string pattern. Log parsing is also a very important application of regular expressions. Here, we will use Python for exploring the different things that we can do using regex. We can even extract PII (personal identifiable information), emails, phone numbers, and more using regex.
Let us get started. Today the simplest way to run Python codes is to use Google Colab. This is useful for running any kind of Python projects including machine learning and data science models. Open https://colab.research.google.com, as shown in Figure 1.
In Python, the most popular library used for regex is ‘re’. It offers a set of functions that allow users to search, match, and manipulate strings based on specific patterns defined by regex. So, the first step before we move forward is to import this library using the following line of code:
import re
There are some special characters in the field of regular expressions, which help us perform different tasks. These are:
\ - drop special meaning of char
[] - represents a character class/set of characters
^ - Beginning of an expression
$ - Ending of an expression
. - Any character except the new line character (‘\n’)
| - Means OR - Matches with characters that are separated by it
? - Matches zero or One occurrence (Verifies whether the given character is there or not)
* - If the given character occurred zero or more times
+ - If the given character occurred one or more times
{}- The number occurrences of a preceding regex needed to match
()- Used to enclose a group of Regex
\ - To remove the special values of these characters
Let us now use these characters one by one, so that we understand them better.
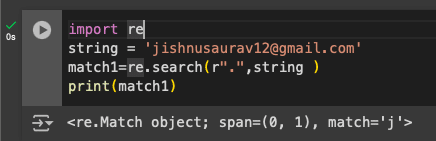
First, let us use the ‘.’ character. Paste the following code in a cell on the Google Colab notebook we created.
import re string = ‘jishnusaurav12@gmail.com’ match1=re.search(r”.”,string ) print(match1)
You can of course use your own string to test and experiment with these characters. In this case, the output would be ‘j’, because ‘.’ represents any character (as shown in Figure 2).
Looking at the functionality of ‘[]’, we can give a set of characters to match in it.
import re string = ‘jishnusaurav12@gmail.com’ match1=re.search(r”[jc]”,string ) print(match1)
As you can see in Figure 3, it will give the first occurrence of any of the characters given in [].
![Output of []](https://www.opensourceforu.com/wp-content/uploads/2025/01/Output-of-.png)
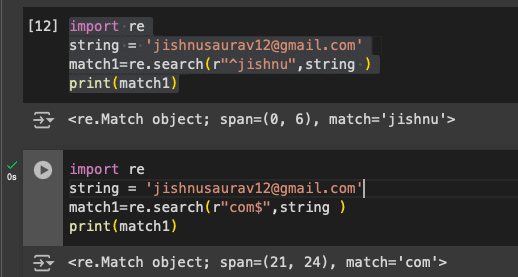
The next special characters are ‘^’ and ‘$’, which represent the beginning and the end of a regular expression. Let us look at an example. Paste the following code:
import re string = ‘jishnusaurav12@gmail.com’ match1=re.search(r”^jishnu”,string ) print(match1) import re string = ‘jishnusaurav12@gmail.com’ match1=re.search(r”com$”,string ) print(match1)
As shown in these two examples, the beginning and the end are being rightly detected (Figure 4).
The next character is ‘|’ which signifies ‘or’. The characters present before or after ‘|’ will be detected as shown in Figure 5.
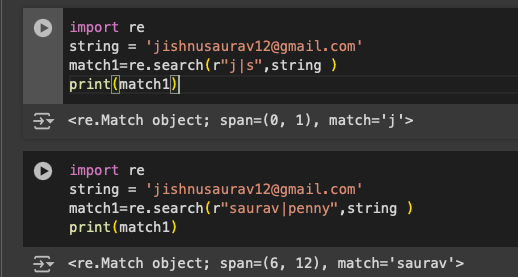
import re string = ‘jishnusaurav12@gmail.com’ match1=re.search(r”j|s”,string ) print(match1) string = ‘jishnusaurav12@gmail.com’ match1=re.search(r”saurav|penny”,string ) print(match1)
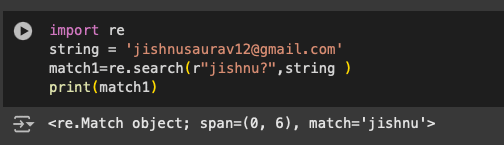
The next character is the ‘?’. This verifies whether the given regex is there in the given string. Let us check it out using the following lines of code.
import re string = ‘jishnusaurav12@gmail.com’ match1=re.search(r”a?”,string ) print(match1)
We will get the index as ‘nothing’ because it is not there, but we will still get it and it will be recognised as shown in Figure 6.
We have explored the functionality of re.search that will help us search for a given regular expression pattern in a string. Let us now explore another important functionality of the ‘re’ library, which is ‘findall’. We can understand the remaining special characters of regular expressions through the findall functionality. All the special characters are applicable to all the functions in the re library.
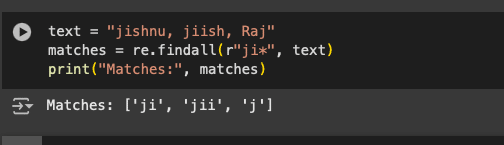
The next character we are going to look at is ‘*’. The ‘*’ implies that the pattern will be recognised if the regex is present zero or more times. The following code can be used to test this.
text = “jishnu, jiish, Raj” matches = re.findall(r”ji*”, text) print(matches)
As we can see in Figure 7, all the strings with ‘j’ followed by zero or more ‘i’s are detected and listed.
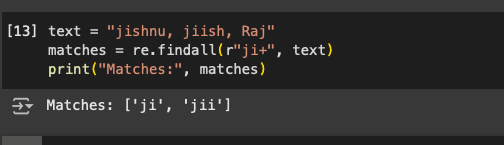
The next character is the ‘+’. The ‘+’ implies that the pattern will be recognised if the regex is present one or more times. The same code as in the previous example can be used to test this.
text = “jishnu, jiish, Raj” matches = re.findall(r”ji+”, text) print(matches)
As we can see in Figure 8, all the strings with ‘j’ followed by only one or more ‘i’s are detected and listed.
We now look at the character ‘{}’, which is used to specify the count of the repeating regular expression that we want to verify.
This can be tested using the code given below. As we can see in Figure 9, only the words that have ‘R’ with three ‘a’s are being listed out.
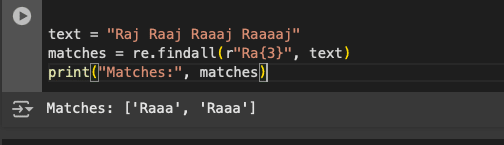
text = “Raj Raaj Raaaj Raaaaj”
matches = re.findall(r”Ra{3}”, text)
print(“Matches:”, matches)
The next character is the ‘()’, which is used to specify a group of characters/regex that we want to verify. This can be tested in the code given below. As we can see in Figure 10, the words that have ‘Ra’ will be listed out.
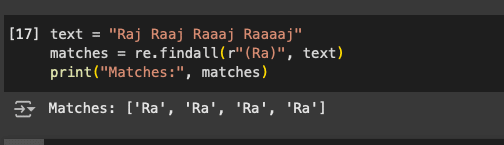
text = “Raj Raaj Raaaj Raaaaj” matches = re.findall(r”(Ra)”, text) print(“Matches:”, matches)
We have seen how the major functions and special characters in regular expressions can be used in Python. You can expand on these to build complex regular expressions for identifying emails, addresses, and more.










