


























































Explore the features, including HIPTensor and MIGraphX, that make AMD’s ecosystem a robust choice for the AI community, providing flexibility, efficiency, and accessibility in machine learning.
AMD has expanded its support for machine learning (ML) development workflows with the release of AMD ROC 5.7, targeting the Radeon RX 7900 XT GPU in addition to the Radeon RX 7900 XTX and Radeo PRO W7900 GPUs. This move opens up new avenues for AI developers and researchers seeking robust solutions from machine learning (ML) training and inference on their local desktop machines.

Based on the RDNA 3 GPU architecture, the GPU boasts 20GB of high-speed onboard memory and 168 AI accelerators. This makes it a good choice for accelerating ML workflows with PyTorch, offering users the computational horsepower they need for their AI tasks without relying heavily on cloud-based resources. With this expansion of GPU support, PyTorch users gain more options for harnessing the parallel computing capabilities of desktop GPUs. This enhances performance and provides a cost-effective alternative to cloud-based solutions.
Erik Hultgren, Software Product Manager at AMD, expressed excitement about adding the Radeon RX 7900 XT to their portfolio, emphasising how these high-end GPUs, combined with ROCm, make AI more accessible to developers and researchers. This flexibility allows them to choose the most suitable solution for their needs. The company’s commitment to the AI community continues to grow, with ROCm software and support extending to three high-end RDNA3 architecture-based GPUs for ML development using PyTorch. This expansion ensures that a broader range of professionals can leverage AMD’s cutting-edge technology for their AI projects.
Its advantages include its compact form factor and lower power requirements than the Radeon RX 7900 XTX. It is the most cost-effective RDNA™ 3 architecture-based GPU for accelerating ML development workflows with PyTorch. Enabling ML on desktop machines empowers users with a local, private, and affordable ML training and inference solution. It reduces dependence on cloud-based services, offering greater control and potentially saving on operational costs. In addition to GPU support, AMD ROCm 5.7 introduces new features and enhancements for high-performance computing (HPC) and AI communities. One notable addition is HIPTensor, a C++ library designed to accelerate tensor primitives, enhancing the flexibility and efficiency of HPC and AI workflows. HIPTensor supports various tensor contraction workflows and AMD GPUs, with plans for expanded data type support.
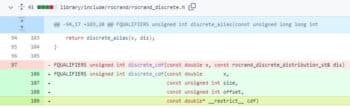
ROCm 5.7 also improves rocRAND RNG performance, optimising discrete distributions for better kernel occupancy. By introducing the __restrict__ keyword, AMD enables new compiler optimisations that enhance performance. Furthermore, the company introduces MIGraphX, a graph compiler focused on accelerating machine learning inference for AMD hardware. MIGraphX transforms and optimises machine learning models, offering a range of optimisations to boost inference performance. It supports ONNX and TensorFlow models, making it accessible through easy-to-use APIs in C++ and Python.
It has dynamic batch support, allowing users to run models with varying batch sizes, optimising for different data inputs during model compilation. This flexibility caters to a broader range of use cases and data scenarios. The company claims that the latest developments in ROCm and GPU support, coupled with the introduction of HIPTensor and MIGraphX, provide a comprehensive and robust ecosystem for AI developers and researchers, fostering innovation and accessibility in machine learning.















