




























































Apache Ignite is a powerful in-memory computing platform that has remarkable speed and scalability, and is highly resilient. Here we focus on its features, use cases, and the advantages it brings to high-performance applications.
Apache Ignite is an in-memory computing platform that is robust, reliable, and extensively accessible with powerful SQL, key-value, and processing APIs. This rich, open source memory-centric distributed platform has numerous components. We can use it as a caching system, as a database, or for in-memory data processing. The platform leverages memory as a storage layer, therefore boasting impressive performance rates. It can be considered one of the fastest atomic data processing platforms currently in production use. Apache Ignite is a distributed database management system intended for high-performance computing that can also be used to support enterprise applications. In simpler terms, it can be described as a RAM-first distributed cache.
This distributed database can be used to support in-memory apps, as an in-memory database or cache, and/or a data grid that exists between an application and different databases. However, it has customs hardware RAM as a caching and storage layer, authorising it to absorb and process complex data sets in parallel and at faster speeds than conventional databases that are dependent on disk storage.
Apache Ignite provides very low latency and very rapid read performance – up to 1000x better than disk-based systems (although it has natural perseverance and can use disk storage, mainly for large data sets that don’t fit in memory). It can also scale open-endedly, meaning it can handle very large data sets, and is highly resilient and fault tolerant. Ignite provides integration with existing databases and data stores, as well as SQL and ACID transactions, with some limitations.
Some notable users of Apache Ignite are Netflix, Microsoft, Apple, Bloomberg and PayPal.
What is a data grid, and is Apache Ignite a data grid?
A data grid is a collection of structured services that offers multiple capabilities like the ability to access, adjust and transfer very huge amounts of geographically separated data, particularly for research and collaboration purposes. Data from diverse regions is pulled from administrative domains, filtered for security purposes, and made available to end users by means of a middleware application.
The short answer is: “Yes!” or we can also say: “Yes, but it is much more.” Originally, Apache Ignite was created and developed as a data grid. However, today it integrates some interesting and unique features that significantly expand its applicability, beyond our traditional understanding of a data grid.
Memory architecture
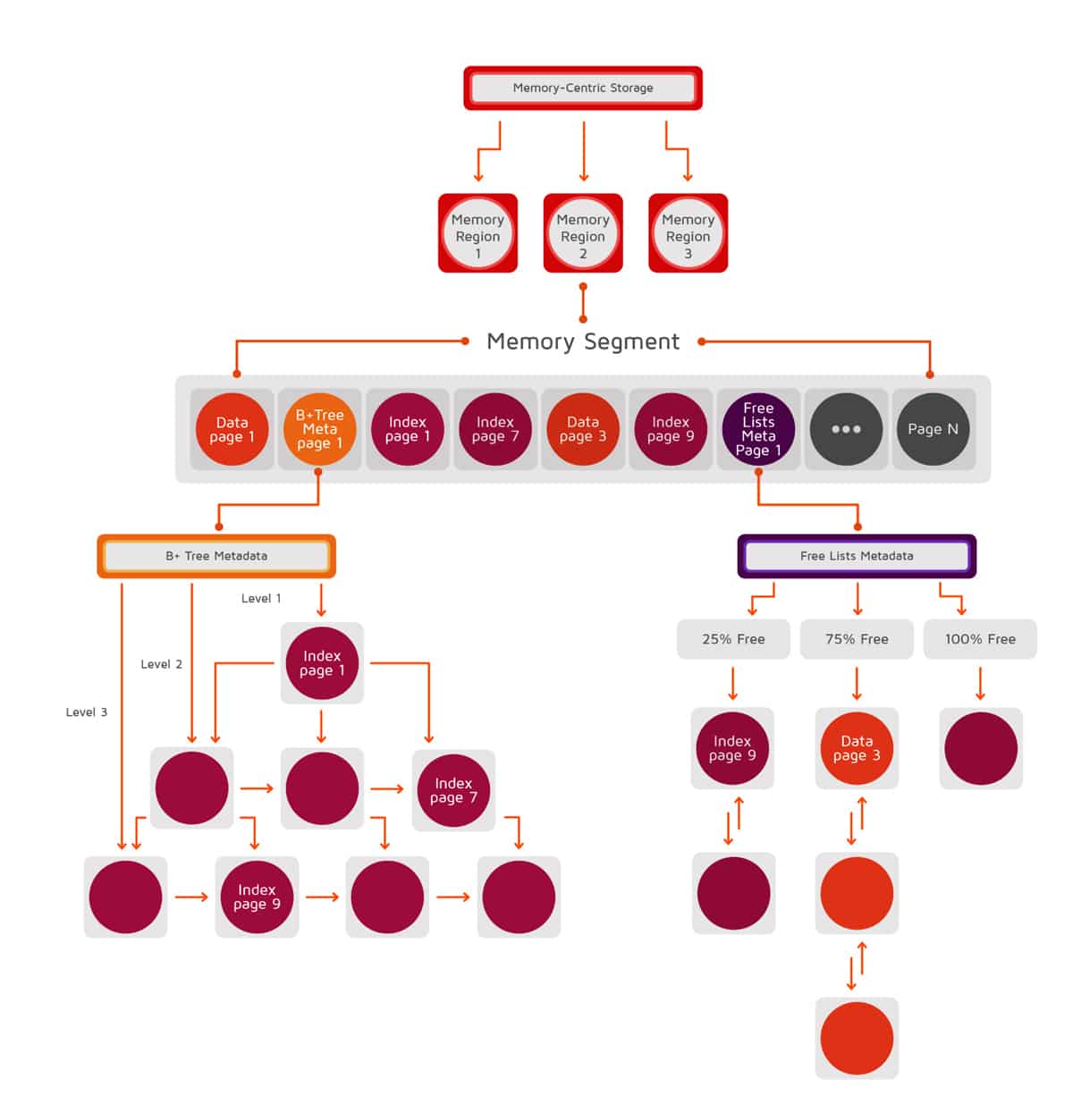
The memory architecture of Apache Ignite allows storing and processing data. It indexes data both in-memory and on disk, which helps to attain in-memory performance with the durability of disk. The multi-layered storage functions in a way like the virtual memory of operating systems, such as Linux. However, one important difference between these two types of architecture is that the multi-layered storage always treats the disk as the superset of the data (if Ignite native persistence is enabled), capable of persisting crashes and restarts, while the conventional virtual memory uses the disk only as a swap extension, which gets removed once the process stops. The multi-layered architecture is a page-based memory structure that is fragmented into pages of fixed size. Managed off-heap regions are where these pages are stored in RAM (outside of the Java heap) and are organised in a special hierarchy on disk. Apache Ignite maintains the same binary data representation both in memory and on disk. This eliminates the need for costly serialisation when moving data between memory and disk.
Figure 1 shows the multi-layered architecture.
Features and FAQs
Below are some general doubts people have with Ignite’s features.
- Is Ignite a distributed cache?
Yes. If Ignite native persistence is disabled, it can function as a distributed in-memory cache which assists distributed ACID transactions.
- Is Ignite an SQL database?
Not entirely. It assists SQL natively, although there are some differences in how Ignite handles constraints and indexes. It also supports primary and secondary indexes, but the uniqueness can only be enforced for the primary indexes. Apache Ignite does not currently support foreign key constraints.
- Is Ignite a key-value store?
Yes. Ignite offers a feature rich key-value API that is JCache (JSR-107) compliant and supports Java, C++, and other languages.
- Is Ignite a NoSQL database?
Not precisely. Just like any other NoSQL database, Ignite is highly available and horizontally scalable. Though, unlike other NoSQL databases, it supports SQL and ACID transactions over multiple cluster nodes.
Is Ignite a distributed database?
Yes. It is a distributed database with high-performance computing and in-memory speed. As we already know, Ignite stores data as in-memory and/or on-disk and is either partitioned or replicated over a cluster of multiple nodes. This offers high performance, resiliency, and scalability.
Apache Ignite use cases
Ideal conditions for using Apache Ignite are:
- Enhancing scalability and speed of live applications
- Creating new, modern, highly performant and scalable transactional and/or analytical applications
- Building streaming analytics applications, often with Apache Kafka, Apache Spark and other streaming technologies
- Incorporating continuous deep learning and machine learning into applications to advance decision automation
If any one of these conditions is met, then using Apache Ignite will provide significant benefits.
Use of Apache Ignite and Grid Gain is increasing, primarily as shared data and processing infrastructure across projects, to deliver in-memory speed and unlimited scalability for transactions and analytics. Apache Ignite offers a great solution to the problem of handling Big Data at very high speeds with great reliability.












