

Data lakes capture, refine, and explore data in its raw form. Find out how they are shaping the future of data management and analytics.
With the advent of social media, IoT and other advancements in technology, a huge amount of data is getting generated. The concept of data lakes emerged in order to extract the maximum benefits from this data — for enhanced adaptability and strong data analytics. A data lake is a storage space for storing heterogeneous data, both organised as well as unstructured. It improves the capture, refinement, and exploration of raw data within an enterprise. The data is kept in its original form, and the structure of the data is defined at the time of use, eliminating complex and costly data modelling.
Traditional decision support systems (DSS) are incapable of handling the huge amount of structured, unstructured, or semi-structured data generated by different resources. The data warehouse (DW) is the solution used by DSS. Here, the data is extracted, transformed and loaded (ETL processes) according to predefined schemas. However, the cost of a DW increases significantly as the data size and complexity increase, and some information is lost through ETL processes.
Data lake architecture
Understanding data lake architecture can lead to more efficient data storage, faster processing, and better decision-making. The data lake architecture has two versions.
- Mono–zone: This is a flat architecture that stores data in its native format. This architecture does not process data or record any user operations. It contains five data ponds that store data according to their characteristics:
- Raw data ponds
- Analog data ponds, to store analog types of data
- Application data ponds, to store application data
- Textual data ponds, to store text data
- Archival data ponds, to store data that is no longer in use
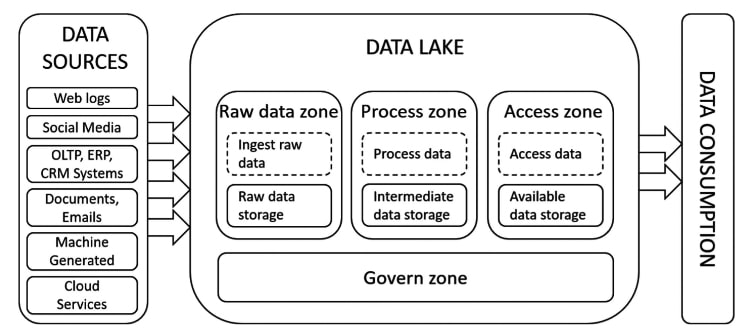
2. Multi-zone: The multi-zone architecture has the following zones.
- Ingestion: Contains the raw data.
- Storage: The ingested raw data is stored here.
- Processing: Whenever data is processed, it is stored in the processing zone.
This can be further divided into the following subzones.
- Batch processing
- Real-time processing
This zone controls data security, data quality, metadata management, and data life cycle.
Figure 1 defines the functional architecture of a data lake.
Data lake storage systems
Data lakes are changing the game for how businesses store and manage their data. Instead of siloed databases and spreadsheets, data lake systems allow you to store and access massive amounts of data in one place, giving you the flexibility to analyse it in real-time. They use different types of storage systems to achieve this. These are as follows.
- File-based storage systems: Hadoop Distributed File System (HDFS) and Azure Data Lake by Microsoft are file-based data lakes used for storage.
- Single data store: These types of data stores focus on specific types of data and use a single database system for their storage.
- Cloud-based data lakes: Large scale commercial data lakes are available on cloud infrastructure like Amazon Web Services (AWS), Azure Data Lake Store, Google Cloud Platform (GCP), Alibaba Cloud, and the Data Cloud from Snowflake.
Advantages of data lakes
Data lakes empower organisations to gain insights and create actionable strategies. However, there is a lot more to them.
- Cost-effective: Data lakes are less expensive to deploy than traditional decision-oriented databases.
- Data fidelity: They preserve the original data to avoid any data loss that could occur from data preprocessing and transformation operations. However, data fidelity also introduces a high risk of data inconsistency in data lakes due to data integration from multiple, disparate sources without any transformation.
- Flexibility and agility: Data lakes have a schema-on-read approach; so they can read any data type and format. Thus, data lakes enable a wider range of analyses than traditional decision-oriented databases, such as data warehouses and data marts, and show better flexibility and agility.
- Real-time data ingestion: Data is ingested into the data lake without any transformation, minimising the time lag between data extracted from sources and its ingestion into databases.
- High scalability: As data lakes are implemented using distributed technologies, they provide high scalability.
- Fault tolerance: The underlying technologies of data lakes provide high resilience to both hardware and software failures, resulting in excellent fault tolerance.
To sum up, data lakes empower organisations to uncover valuable insights from their data, paving the way for data-driven decision-making in the digital age.


