


























































Apache Spark is a unified analytics engine for Big Data processing, and has support for both batch and stream processing. What is it that makes it an attractive solution for developers and data scientists alike?
Data is everywhere and data is everything. Every purchase at a supermarket generates data. Every post on Twitter generates data. Every administered vaccine generates data. Every flight that takes off generates a stream of data.
These examples are sufficient to say that enormous amounts of data are getting generated every moment across the world. Organisations tend to look into this data for insights, predictions, analytics, and so forth. However, the data is now so big in size that traditional technologies are incapable of processing it. This is where Big Data steps in.
Big Data is a set of tools and technologies to process huge amounts of data. More and more organisations across various verticals have been implementing Big Data for their business needs in the last few years.
Apache Spark is one of the most promising open source unified engines to process Big Data. This article introduces the length and breadth of Apache Spark to help CTOs make architectural decisions for their organisations.
Architecture
Apache Spark is a cluster computing system that processes data in memory.
The cluster consists of a master node and a minimum of one worker node. In practice, the cluster usually consists of scores of worker nodes. Though Spark can manage the cluster on its own, other time-tested tools like Hadoop Yarn, Apache Mesos, or even Kubernetes can also be used for managing the cluster for Spark.
How does Spark use the cluster for computing?
Let’s take a simple analogy. Assume that a CEO wants to shortlist a few candidates for an important position in the organisation. Thousands of resumes are received in response to an advertisement. It takes significant time and effort for a single person to filter them based on the parameters like qualifications, experience, and so on. So the CEO asks the hiring manager for help in processing the resumes.
The hiring manager divides the resumes into smaller lots containing only a hundred resumes per lot, and requests for a few assistants from the HR department. Once the HR department allocates the assistants, the hiring manager distributes the lots to them for filtering. Each assistant processes only the resumes in the assigned lots, and submits the shortlisted resumes to the hiring manager.
Once all the assistants complete the processing, the hiring manager collates all the shortlisted resumes and gives the bundle to the CEO.
We can deduce the following observations from this analogy:
1. The work is to shortlist a few resumes from the thousands of resumes.
2. The hiring manager divides the work into smaller tasks.
3. The hiring manager requests for assistants from the HR department.
4. The hiring manager distributes the tasks to the assistants.
5. Each task consists of processing only a smaller set of resumes.
6. The assistants quickly finish the assigned tasks since they have only a few resumes to process.
7. The assistants submit the shortlisted resumes to the hiring manager.
8. The hiring manager collates all the shortlisted resumes from all the assistants.
9. The hiring manager submits the shortlisted resumes to the CEO.
In the Spark architecture, as illustrated in Figure 1, the driver plays the role of the hiring manager and the executors play the role of the assistants. As you might have guessed, the HR department plays the role of cluster manager.
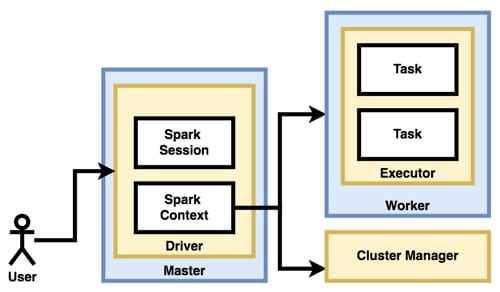
Driver: This is a program that is submitted to the cluster, to process Big Data using the Spark API. It can be written in Java, Scala, Python or R.
Spark context: The driver program that runs on the master node maintains the Spark context. Irrespective of the number of jobs that are submitted to the driver, it maintains only one context. Each job runs in a separate session, but all use the same context. The responsibilities of the context include analysing and dividing the job into smaller tasks with smaller data partitions, procuring workers from the cluster manager, allocating the tasks on the executors, and collating the responses from executors.
Executor: The worker nodes run one or more executors. Each executor may run multiple tasks as long as all of them belong to the same job. The executors of different jobs are inaccessible to each other. The responsibility of an executor is to run the task on the assigned data partitions and send the results back to the context.
Setting up Spark local
Though the real cluster is made up of several production machines, it can also be set up on a single development machine for experimentation. The only prerequisite is to have JDK, version 8 or later installed on the development machine. Since Apache Spark is written for JVM, the physical machine can be powered up by any operating system, though Linux is the most popular choice.
Once the development machine is ready with JDK, download the latest Apache Spark from https://spark.apache.org/downloads.html
Spark can also be downloaded from a Linux terminal with the following command:
wget https://www.apache.org/dyn/closer.lua/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
Copy the downloaded archive to a folder of your choice, if needed. Extract the archive with the following command:
tar -xvf spark-3.1.2-bin-hadoop3.2.tgz
It creates a folder by the name spark-3.1.2-bin-hadoop3.2. This folder will be referred to as SPARK_HOME hereafter.
For simplification, add the Spark binaries to the path with the following commands:
export PATH=$PATH:<SPARK_HOME>/bin export PATH=$PATH:<SPARK_HOME>/sbin
Spark shell
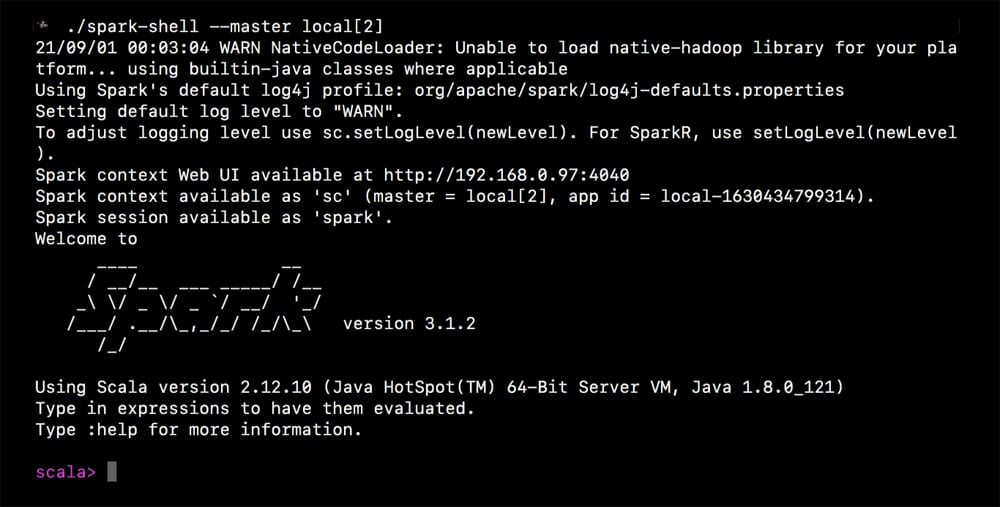
Apache Spark comes with an interactive shell, which can be used during prototyping. The shell starts a Spark application with a Spark context on the specified master node. It accepts commands from the user and submits them to the master. Spark shell supports Scala commands by default.
Start the shell with the following command on a terminal. The command is found under SPARK_HOME/bin:
spark-shell —-master local[2]
This command not only starts Spark shell, but also starts the cluster on the local machine. Since this cluster consists of only one node, obviously the local machine is the master. The number 2 within the brackets results in two worker threads.
It is clear from Figure 2 that the shell has the Spark context, which is accessible as sc.
Type the following on the Scala prompt to see the list of available commands:
scala> :help
Setting up Spark cluster
We have just created a Spark cluster on a single machine. In reality, the cluster consists of several machines. To set up such a cluster, install JDK 8+ and extract the downloaded Spark distribution on all the machines of the cluster.
On one of the machines, run the following command to start the master:
SPARK_HOME/sbin/start-master.sh
Once the master starts running, find out the master URL from the log file located under the folder SPARK_HOME/logs. For example, on the experimental setup, the following is printed as the master URL in the logs:
spark://localhost:7077
The next step is to set up the workers. Open the terminal on each of the worker nodes, move to the folder SPARK_HOME/conf and find the file named spark-defaults.conf.template. Make a copy of this file and save it as spark-defaults.conf. Open spark-defaults.conf and uncomment the line indicating spark.master. Edit the URL and other configuration properties, if required.
Once the configuration is ready, start the worker by running the following command:
SPARK_HOME/sbin/start-worker.sh <master-url>
For example, on the experimental machine, the worker is started with the following command:
SPARK_HOME/sbin/start-worker.sh spark://localhost:7077
Repeat this process on all the workers, to bring up the cluster.
Alternatively, edit the SPARK_HOME/conf/workers.sh file on the master node, add the IP addresses of all the worker nodes, and run the command:
SPARK_HOME/sbin/start-workers.sh
…to bring up the cluster in one shot.
Either way, once the cluster is ready, use the following command to run the Spark shell on a machine that is connected to the cluster:
SPARK_HOME/bin/start-shell –master <master-url>
Job submission
The Spark shell can be used to submit jobs to the cluster. For example, the following command submits a job that computes the sum of the specified numbers:
scala> sc.parallelize(Array(1, 2, 3, 4, 5), 2).reduce((a,b)=>a+b)
This command refers to an array of five elements as the source data, and submits a reduction function for the computation. Also, the command suggests the data be divided into two partitions.
Obviously, an array of five elements does not represent Big Data. Often, the Big Data is present in local files, HDFS, Cassandra, Hbase, AWS S3, etc, in the production environments. We can point the Spark shell to such data sources.
For example, the following command loads the data file from the local disk and prints the word count:
scala> sc.textFile(“data.txt”).flatMap(line=>line.split(“ “)).count
Both the above jobs are small in size. When the job is complex, a separate Spark application can be written in Scala, R, Java, or Python. Such applications are submitted to the cluster for processing using the tool SPARK_HOME/bin/spark-submit.
A typical Spark application that is written in Scala looks like this:
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD.rddToPairRDDFunctions
object HelloWorld {
def main(args: Array[String]) {
val sc = new SparkContext(new SparkConf().setAppName(“HelloWorld”))
print(sc.textFile(“data.txt”).flatMap(line => line.split(“ “).count)
sc.stop
}
}
If this application is compiled and archived as hello.jar, it can be submitted to Spark with the following command:
SPARK_HOME/bin/spark-submit –class HelloWorld –master <master-url> hello.jar
Resilient distributed data set
Let us look at one of the jobs that we submitted to the Spark shell:
sc.parallelize(Array(1, 2, 3, 4, 5), 2).reduce((a,b)=>a+b)
As indicated earlier, this command is requesting the Spark context to partition the supplied data into two partitions. Each of the partitions is referred to as resilient distributed data set or RDD in short. The RDD is the fundamental abstraction in Spark. In other words, everything in Spark operates on RDDs behind the curtains.
The RDD is fault-tolerant and immutable. The workers work only on the allocated RDDs. Even if an executer crashes, another executor can be started with the same RDDs.
Primarily, there are two kinds of operations done on the RDDs — transformations and actions.
Transformations: A transformation accepts an RDD and maps it to a new RDD. Several transformations can form a pipeline. Transformations are lazy. In other words, Spark optimises the pipeline before actual execution. Operations like map, filter, join, etc, are some of the examples of transformations.
Actions: Actions return the results to the driver after computation. Operations like reduce, collect and count are some examples of actions.
Both transformations and actions are executed by loading the RDDs into the memory for best-in-class performance.
However, it is not recommended to program around just the RDDs, as there are better and high-level abstractions available on top of RDDs. Coding around RDDs is like writing assembly instructions when we have an option to use a high-level language.
Data sets and DataFrames
Spark holds data in the form of RDDs or in the form of DataFrames. A DataFrame is an abstraction built on top of an RDD, and is a distributed collection of structured data analogous to tables with schema.
DataFrames can be created from RDDs or directly from Spark Datasources like JDBC, Hive tables, etc. In other words, the DataFrames can be created both from structured or semi-structured data.
Here is an illustration:
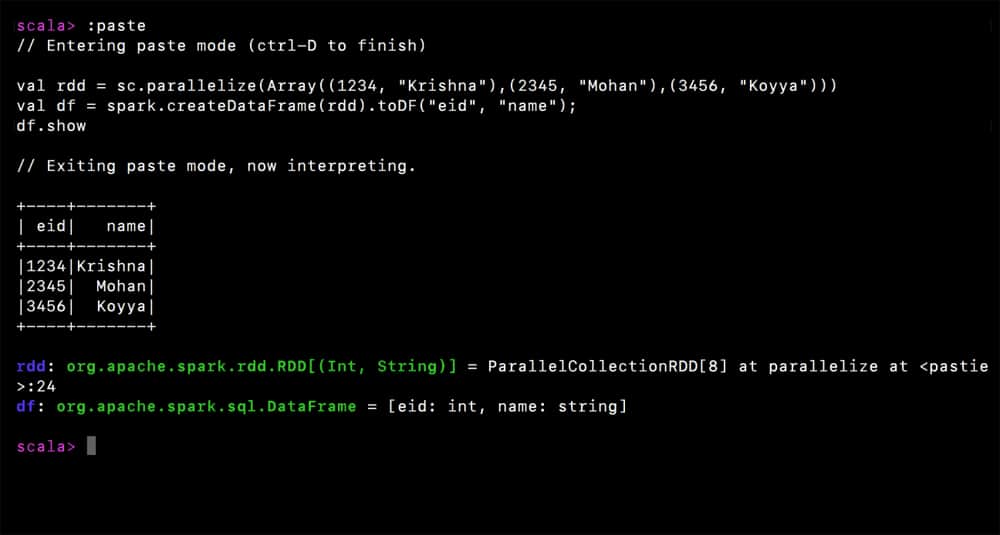
val rdd = sc.parallelize(Array((1234, “Krishna”),(2345, “Mohan”),(3456, “Koyya”))) val df = spark.createDataFrame(rdd).toDF(“eid”, “name”); df.show
The above program indicates the context to create RDDs from the supplied array and then create a DataFrame from those RDDs. Figure 3 indicates that it is ok to say that DataFrames can be viewed as tables with schema.
Spark SQL
Once the DataFrame is created, it is quite easy to create a view of it and run operations that are similar to SQL operations.
Since we already have the DataFrame in the variable df in the above snippet, let’s create a view named employees from the df with the following code:
df.createOrReplaceTempView(“employees”)
Now we are all set to execute SQL-like operations on this employee’s view. Spark SQL supports the aggregations, restrictions and projections that we normally expect in an SQL environment.
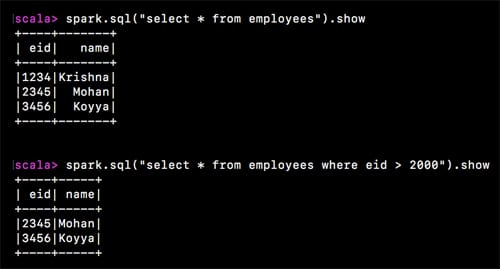
Here are some examples that are self-explanatory:
spark.sql(“select * from employees”).show spark.sql(“select * from employees where eid > 2000”).show
Stream processing
A few years ago, organisations used to process data primarily in batches. For instance, a news publisher would update its online portal once an hour. However, with the penetration of the Internet and mobile devices, the demand for real-time news is only growing. Publishers are expected to update the portal as and when an event is reported. In other words, organisations are expected to process streams of data, round-the-clock.
Apache Spark has excellent support for stream processing. Though the abstractions like RDDs and DataFrames are best suited for batch processing, Spark also uses them to build scalable, fault-tolerant stream processing capabilities.
The secret of Spark’s stream processing is in the way it divides the streamed data. By applying a time window, a stream of data can be treated as several batches of data. When the size of the window is sufficiently small, stream processing turns out to be just micro batch processing, but at a high frequency. Spark does exactly this. In other words, a discrete stream is treated just as a sequence of RDDs.
A typical stream processing job written in Scala looks like the following:
val lines = spark.readStream.format(“socket”).option(“host”, “localhost”).option(“port”, 1234).load() val words = lines.as[String].flatMap(_.split(“ “)) val counts = words.groupBy(“value”).count() val ctx = counts.writeStream.outputMode(“complete”).format(“console”).start ctx.awaitTermination()
The above code creates a Spark job to listen to TCP socket at port 1234 on the local machine, for a stream of data, and print the word count on the console. To run the above job, a server should be started on that port, beforehand. A simple tool like netcat can be used for experimentation as follows:
$nc -lk 1234
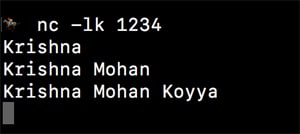
Enter some lines of text in the server window, as shown in Figure 5. These lines will be received by the Spark job that is listening to this port, as a stream. The results are demonstrated in Figure 6.
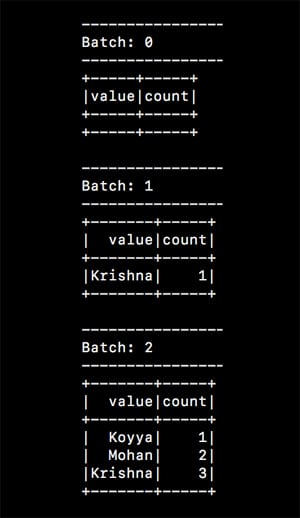
Spark supports data sources including Apache Kafka, Apache Flume, AWS Kinesis, TCP sockets, files, etc, out-of-the-box. When it comes to processing, it supports algorithms including but not limited to map-reduce, join, and sliding window. The processed data can be channelled into files, databases, live dashboards, and more.
Machine learning with Spark
Another interesting part of the Spark ecosystem is MLib for machine learning. Data scientists can focus on data processing while Spark takes care of the infrastructure. MLib interoperates with Numpy in Python and R libraries. Any Hadoop data source like HDFS and Hbase can be used to fit into Hadoop workflows, if these exist.
MLib supports all major algorithms like classification, regression, clustering, decision trees, etc. It also offers utilities for constructing, evaluating, saving and loading models and pipelines.
Admin interface
Everything in Spark runs as a job. As noted earlier, the job is split into tasks that carry out in-memory transformations and actions, in parallel, on the workers across the cluster. This model gives Spark an edge in parameters like performance and throughput.
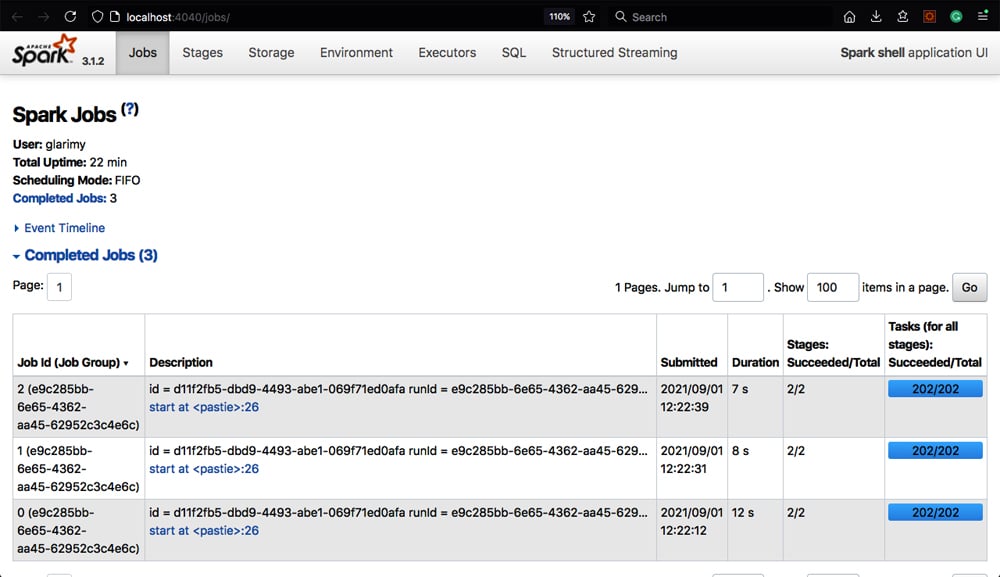
However, this model also poses a challenge to the administrator. Since the job is running across the cluster and is automatically scheduled by the driver, the administrator will have the additional responsibility of tracking it on not just one machine, but on the entire cluster. The admin interface provided by Spark immensely helps the administrator in this regard.
For example, the admin interface for the Spark shell can be accessed at http://localhost:4040/jobs/, which is similar to what is shown in Figure 7. Such an interface is available for every Spark application using which the status of the jobs, storage, and executors can be tracked.
Spark Big Data ecosystem
No organisation possibly uses just one or other Big Data technology. Often, the CTOs deploy several tools and technologies for various processing needs. Apache Spark is one such tool that can be used for batch processing, stream processing, and machine learning at scale.
Spark can work with other big data technologies like Hadoop data sources, Hadoop cluster managers, Apache Kafka, and Apache Flume, to name a few.
On its website, Apache Spark claims 100 times faster performance compared to the nearest competitor. This speed is attributed to the clusterwide in-memory computation model. With first-class support in Java, Python, Scala, and R, Apache Spark’s popularity and adoption are only growing!


















