


























































This article demystifies the labyrinth of resource provisioning in a cloud-edge computing environment by looking at the concept, use cases and practical approaches.
Provisioning a resource in any type of a cloud environment is undoubtedly a daunting task.
Ensuring a fair share of resources while putting up a new workload on a cloud is complex but well understood as of now. However, the problem becomes challenging when we consider it in the context of cloud Internet of Things (IoT), where the resources need to be provisioned across the edge and the cloud. The presence of two different systems with varying characteristics makes it an interesting subject to study.
| Use case | Scenario |
| Data collection and analytics | Instead of sending back huge volumes of data to the cloud, deploy the analytics near the sensor site only, and pass the crux of analytics to the cloud for long-term trending and forecasting purposes. |
| Security | With the proliferation of mobiles and sensors, the chances of getting attacked also increase. Therefore, moving the security element closer to the originating source of the attack makes sense. |
| Compliance | This ranges from the locality of data to the ownership control – limiting data streaming back to the cloud makes compliance easier. |
| Network function virtualisation | This is the next generation of network infrastructure elasticity, where the telcos are increasingly trying to run their networking on top of NFV to reduce the cost, instead of being centrally managed. |
| Real-time | The advent of AR/VR, self-driven cars, telemedicine, smart cities and so on, adds flavour to cloud-edge computing. |
| Immersive | A new breed of applications includes AR/VR, 4K video, and 360° imaging for verticals like healthcare. |
| Network efficiency | Not all the applications need to be run centrally. Facial recognition or number plate recognition fit well into the edge itself. |
| Self-contained and autonomous site operations | A stable network is one of the challenges of edge for hostile sites like mining, power generation, etc. Hence, running wholistic apps in the edge is beneficial for these types of deployments. |
| Table 1: Cloud-edge use cases [Reference: https://www.openstack.org/use-cases/edge-computing/cloud-edge-computing-beyond-the-data-center/] | |
The story so far
Cloud computing resource provisioning encompasses putting up various types of resources like compute, storage, memory, network, and applications/ services/ microservices/ lambdas over the Internet. The proliferation of mobile technology makes things interesting. Nowadays our phones are equipped with good quality sensors, and hence all computations and their outcomes can potentially be context sensitive – both spatial and temporal. This results in a new variant, often loosely termed as mobile cloud computing.
| Tenets | Role |
| Workload analysis and modelling |
|
| Application optimisation |
|
| Infrastructure optimisation |
|
| Table 2: Resource provision tenets | |
IoT adds another dimension in this context. IoT devices are big storehouses of data. They are designed to operate in hostile environments such as unstable networks, with constraints of memory and storage, and so on. Hence, to provide contextual and personalised recommendations, the overall system architecture needs to process huge amounts of data and keep on transferring the digest from the edge towards cloud. In such a scenario, maintaining the integrity of the continuum resource availability from edge to cloud is of paramount importance.
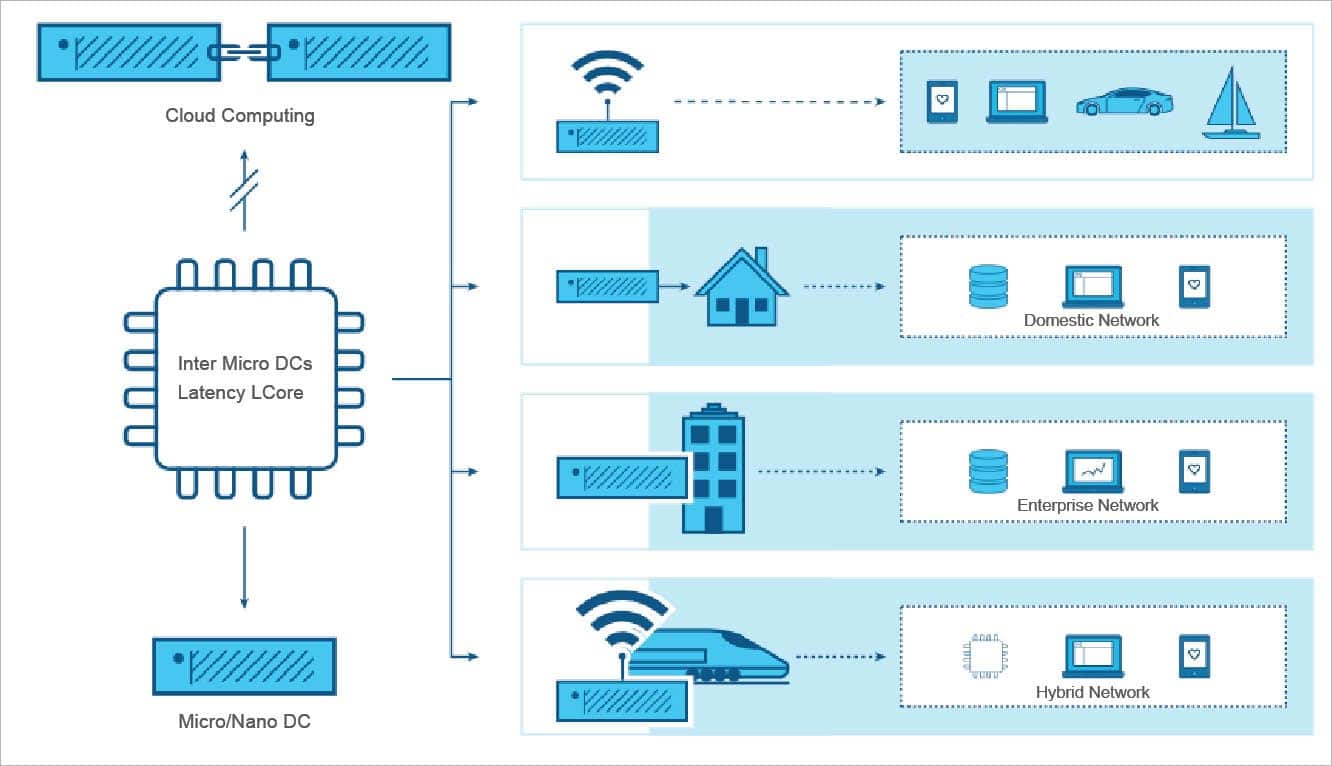
To understand the problem at hand, one must look at other aspects too like the standardisation of the IoT ecosystem. To facilitate the convergence of networking and IT, the Mobile Edge Computing (MEC) Working Committee has proposed a model in which compute (in the cloud) and IT are merged into the radio access network (RAN) in the proximity of the end user.
Application architecture is another important aspect.
The emergence of data intensive 5G mobile telephony mandates a reformed look at the system architecture. As of today, the typical cloud architecture consists of a set of services/components deployed across nodes. The shift of services from the traditional cloud deployments towards edge makes it possible for the application to be less network hungry and quicker in response. Hence, we see the proliferation of microservices beyond the traditional multi-tier service-oriented architectures.
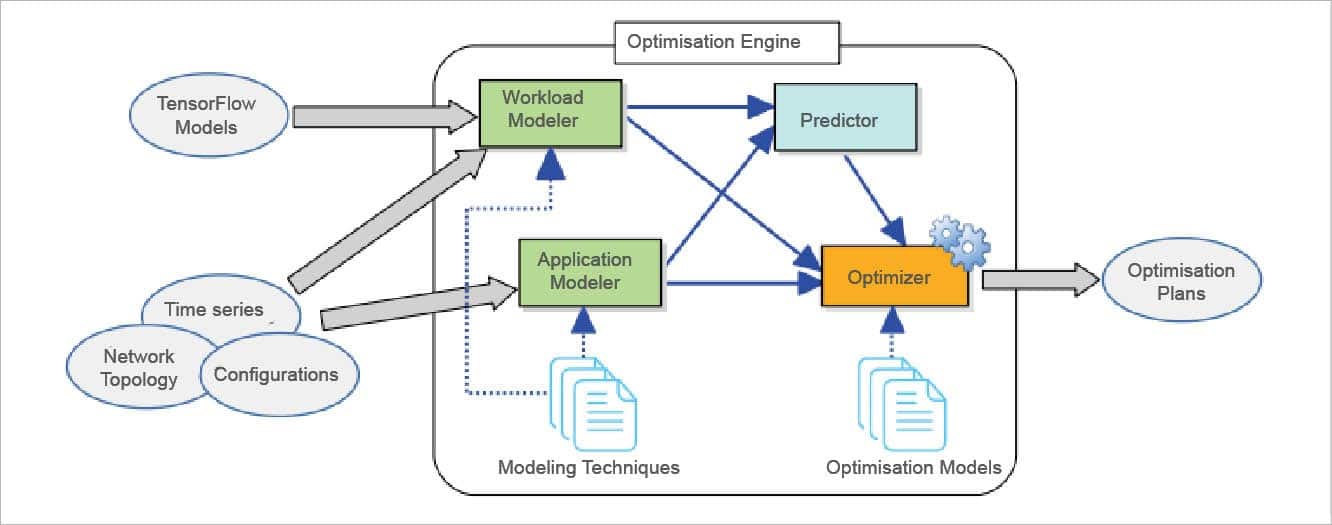
A reference architecture
Figure 2 gives a helicopter view of a sample reference architecture.
Here we need two types of modelling. The first one is to understand the workload pattern and the second is to understand the application pattern. The predictor predicts the workload and application behaviour. The optimiser yields the optimisation plan to place the VM/container working on the prediction values.
The workload modeller takes two sorts of input: raw data in terms of current metrics, network topology and the configurations; and models generated by the third party modelling tools. The predictor depends not only on the workload modeller output, but also on the application modeller’s output to manage the workload propagation or workload distribution throughout the components of the application.
The optimiser also evaluates multiple models to fine tune the optimisation plans for the controlled placement of the components across available resources under the SDI abstraction.
Techniques
As we now have a glimpse of the architecture, let us now look into some implementation details.
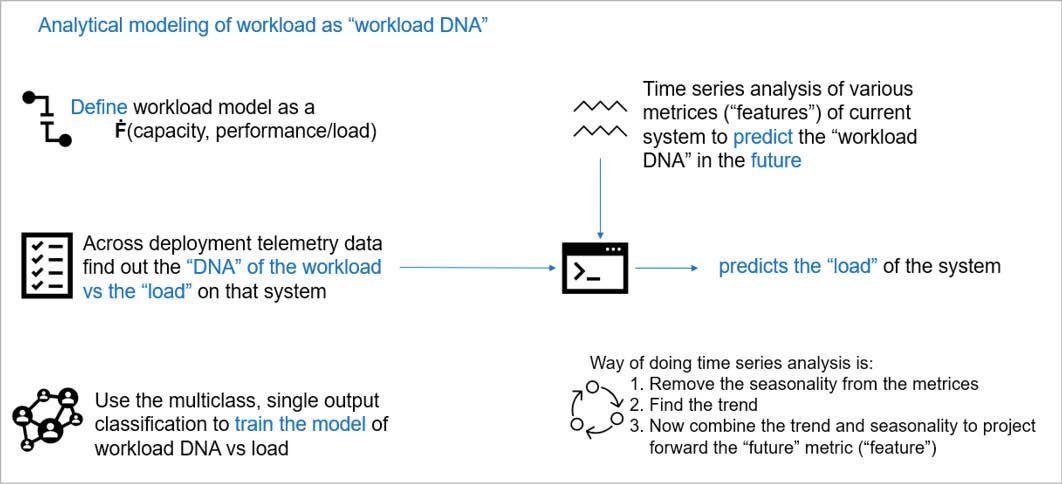
Workload modelling, analysis, prediction: Figure 3 depicts one of the many ways to synthesise a workload fingerprint for systems under deployment.
Placement optimisation: Deploying application components into bare metal servers, VMs, containers, etc, raises different issues related to replicas or content placements similar to those in CDN. The problem has its own set of constraints primarily coming from various key performance indicators (KPIs), optimal resource utilisation and the quality of service (QoS). There are various well-studied techniques that are available, namely but not limited to:
- Linear programming based resource placement
- Graph to graph mapping of resources
- Multi-objective optimisations
Resource elasticity and remediation: The following techniques are applicable here:
- Geographical load balancing through cost function modelling, considering service delay and energy consumption.
- Placement decision based on attributes of every single container (size and resource demand).
- Particle swarm optimisation algorithm (multiple objective particle swamp optimisation, MOPSO).
Network function virtualisation: Network Function Virtualisation (NFV) is a technique for modelling the network functions into basic building blocks at the software layer. The primary advantage is that these NFVs can run on any standard server or cloud without requiring any specialised network appliance. Typical techniques of NFV resource allocations are:
- Markov decision process.
- Graph neural network model based prediction. The training is done with historical and topological information (i.e., behaviour of neighbouring components).
- Often, genetic programming approaches are used, as they do better than their linear counterparts.
| Scenario | Details |
| Cloud in a box | Local caching of content or providing a whole stack of compute, network, storage in a self-contained fashion near the usage site overcomes the limitation of networking. |
| Mobile connectivity | Ubiquitous use of mobiles, specially with the emergence of 5G, is going to benefit from computing moving closer to the workloads. |
| Network-as-a-service | Small footprint of network service provider’s distribution network at the edge makes it more affordable. |
| Universal Customer Premises Equipment (uCPE) | Applicable especially for NFV, where different sites need to host different applications, but they need to work in concert. |
| Satellite enabled communication (SATCOM) |
Massive distribution of terminal devices often in very remote and adverse conditions, e.g., aircrafts, oil exploration, mining, and military grade instruments. |
| Table 3: Cloud edge deployment scenarios | |
Open source in cloud-edge
This is really an emerging field and tools are yet to show up. However, OpenStack – which is a widely used cloud data management framework – is also delving into this field through its initiative called OpenStack Foundation Edge Computing Working Group (OSF Edge WG). It has classified the scenarios into various categories, as shown in Table 3.
Going forward
Resource provisioning in cloud deployment is a well-studied subject. We have discussed the various tenets associated with the problem statement, which leads to a general reference architecture consisting of various modellers, predictors and optimisers to get optimal placement decisions for placement planning.
We also discussed some of the underlying techniques to get things done in a viable and feasible way. We hope that the overall architectural reference diagram along with the techniques in our arsenal will be invaluable for further studies on the resource provisioning problem.















