


























































Data analysis requires the extraction, cleansing, transformation, sorting and the modelling of data in order to derive useful results from it—to make useful deductions and support decision making. Pivot tables are important in the field of data analysis because they help in summarising data quickly and efficiently.
A pivot table is a data organisation tool used frequently by data analysts to get summary reports of data in different formats. It is widely used to evaluate basic descriptive statistics of data. These include sorting, reorganising, grouping, counting, summarising and averaging of the recorded data. These statistics are used for further higher level data processing like pattern analysis or decision making. A pivot table allows data scientists to transform columns into rows and vice versa. It also allows data grouping by its constituent attribute fields. It provides a better solution for summarising a large volume of data and is widely used in Microsoft Excel. The pivot table concept can be implemented using SQL queries too. This technique is discussed here with a few examples on some common data sets. A pivot table requires a CASE statement to switch rows to columns. Let’s briefly explore CASE statements.
MySQL CASE expression
MySQL CASE expression is a control flow structure that allows if-else logic in a query. It can be used with SELECT, WHERE and ORDER BY clauses. The CASE expression has two forms: simple CASE and searched CASE. Simple CASE is used in the stored procedure and search CASE is used in the SELECT clause for queries.
A simple CASE syntax is as follows:
CASE value WHEN value1 THEN result1 WHEN value2 THEN result2 … [ELSE else_result]
A search CASE syntax is as follows:
CASE WHEN expression1 THEN result1 WHEN expression2 THEN result2 … [ELSE else_result] END
A simple CASE statement acts on the basis of the ‘value’ parameter, whereas the search CASE statement acts on the basis of the expression of the ‘when’ block and returns results for each record. Here I will use the search CASE syntax to implement the pivot table.
Stored virtual tables
SQL supports virtual tables. It contains no data but generates reports when executed. Tables are created using select queries and stored as SQL query files. SQL never stores data and remains inactive till it gets executed. In that sense, it is useful to store complex queries and is often used to generate tables, joining multiple tables based on specific relationships among their fields.
The SQL CREATE or REPLACE VIEW syntax is as follows:
CREATE VIEW view_name AS SELECT column1, column2, FROM table_name WHERE condition; CREATE OR REPLACE VIEW view_name AS SELECT column1, column2, ... FROM table_name WHERE condition;
Views can be deleted as follows:
DROP VIEW view_name;
Stored virtual tables are often used in high level query and report generation. Here I shall use the invoice virtual table for pivot table generation.
Resource
In this discussion I have used the Northwind database for pivot table implementation. Since it is well known to the database user community and the organisation of the tables is easy to understand, I hope a little browsing of the table will help readers to understand the implementation of a pivot table. Readers can download the database from https://code.google.com/archive/p/northwindextended/downloads. In this discussion I have used the Northwind.MySQL5 database.
Pivot table
Though a pivot table may have different forms, at its very core, it is a transposition of data from multiple rows into columns of a single row. This approach to rearrangement is particularly common in data analysis for report generation. To illustrate the technique in SQL over a table, here I have considered the orders table of the Northwind database. This table contains order-wise detailed information about different items for several years. If we want a report of month-wise total freight charges of every year, we can make ‘year’ as the pivot to transform the table orders into a per-year month-wise freight pivot table. To extract month-wise total freight charges, you need to run the query over a sub-query of orders, with the year and month extracted from the orderDate field. On the basis of extracted month values, we can now take the total of the month-wise freight charges and populate them in the 12 columns of the report. The following SQL example will make this clear.
Simple pivot table
Let’s have a look at the table orders. It has the field ‘freight’ indicating cargo charges for the shipment of orders. To have month-wise total freight charges for each year, we need a pivot table. To have a summary report on the months, we need a sub-query on OrderDate to extract the year and month so that the pivot table can be created for month-wise total freight charges.
CREATE TABLE `orders` ( `OrderID` INT(11) NOT NULL AUTO_INCREMENT, `CustomerID` VARCHAR(5) NULL DEFAULT NULL, `EmployeeID` INT(11) NULL DEFAULT NULL, `OrderDate` DATETIME NULL DEFAULT NULL, `RequiredDate` DATETIME NULL DEFAULT NULL, `ShippedDate` DATETIME NULL DEFAULT NULL, `ShipVia` INT(11) NULL DEFAULT NULL, `Freight` DECIMAL(10,4) NULL DEFAULT ‘0.0000’, `ShipName` VARCHAR(40) NULL DEFAULT NULL, `ShipAddress` VARCHAR(60) NULL DEFAULT NULL, `ShipCity` VARCHAR(15) NULL DEFAULT NULL, `ShipRegion` VARCHAR(15) NULL DEFAULT NULL, `ShipPostalCode` VARCHAR(10) NULL DEFAULT NULL, `ShipCountry` VARCHAR(15) NULL DEFAULT NULL, PRIMARY KEY (`OrderID`), INDEX `OrderDate` (`OrderDate`), INDEX `ShippedDate` (`ShippedDate`), INDEX `ShipPostalCode` (`ShipPostalCode`), INDEX `FK_Orders_Customers` (`CustomerID`), INDEX `FK_Orders_Employees` (`EmployeeID`), INDEX `FK_Orders_Shippers` (`ShipVia`), CONSTRAINT `FK_Orders_Customers` FOREIGN KEY (`CustomerID`) REFERENCES `customers` (`CustomerID`), CONSTRAINT `FK_Orders_Employees` FOREIGN KEY (`EmployeeID`) REFERENCES `employees` (`EmployeeID`), CONSTRAINT `FK_Orders_Shippers` FOREIGN KEY (`ShipVia`) REFERENCES `shippers` (`ShipperID`) ) ENGINE=InnoDB
The CASE statements of the main query will get months from the sub-query and will perform the aggregation of freight charges for the months of the year. This is shown in the following SQL query. To have the months of a year, it is necessary to summarise the table on the basis of ‘year’ also. The GROUP BY clause is used here to categorise all the rows/records on year values. This clause, in conjunction with the aggregation function SUM, is used to get the month-wise total freight report and return a single row for every grouped item.
SELECT year , SUM(CASE WHEN month = 1 THEN freight END) Jan_frg , SUM(CASE WHEN month = 2 THEN freight END) Feb_frg , SUM(CASE WHEN month = 3 THEN freight END) Mar_frg , SUM(CASE WHEN month = 4 THEN freight END) Apr_frg , SUM(CASE WHEN month = 5 THEN freight END) May_frg , SUM(CASE WHEN month = 6 THEN freight END) Jun_frg , SUM(CASE WHEN month = 7 THEN freight END) Jul_frg , SUM(CASE WHEN month = 8 THEN freight END) Aug_frg , SUM(CASE WHEN month = 9 THEN freight END) Sep_frg , SUM(CASE WHEN month = 10 THEN freight END) Oct_frg , SUM(CASE WHEN month = 11 THEN freight END) Nov_frg , SUM(CASE WHEN month = 12 THEN freight END) Dec_frg FROM (SELECT orders.* , EXTRACT(YEAR FROM OrderDate) year , EXTRACT(MONTH FROM OrderDate) month FROM Orders ) Orders GROUP BY year ORDER BY year
The pivot table output is given below:

This query will create a report table of the monthly total freight charges of each year, sorted in the descending order of years. The above data clearly shows the pattern of monthly freight charges of each year. This report can be made more statistically viable for data analysis, if we can take the mean and variance of freight charges.
Computed pivot table: Total month-wise yearly sales
Let us consider another example of the pivot table from the same database. To generate a report of the monthly total sales for each year, we can consider the virtual table invoice view. Unlike the above example, here we need a little bit of computation to get year-wise monthly sale values.
The structure of the invoice view is as follows:
SELECT Orders.ShipName, Orders.ShipAddress, Orders.ShipCity, Orders.ShipRegion, Orders.ShipPostalCode, Orders.ShipCountry, Orders.CustomerID, Customers.CompanyName AS CustomerName, Customers.Address, Customers.City, Customers.Region, Customers.PostalCode, Customers.Country, (Employees.FirstName + ‘ ‘ + Employees.LastName) AS Salesperson, Orders.OrderID, Orders.OrderDate, Orders.RequiredDate, Orders.ShippedDate, Shippers.CompanyName As ShipperName, `Order Details`.ProductID, Products.ProductName, `Order Details`.UnitPrice, `Order Details`.Quantity, `Order Details`.Discount, (((`Order Details`.UnitPrice*Quantity*(1-Discount))/100)*100) AS ExtendedPrice, Orders.Freight FROM Customers JOIN Orders ON Customers.CustomerID = Orders.CustomerID JOIN Employees ON Employees.EmployeeID = Orders.EmployeeID JOIN `Order Details` ON Orders.OrderID = `Order Details`.OrderID JOIN Products ON Products.ProductID = `Order Details`.ProductID JOIN Shippers ON Shippers.ShipperID = Orders.ShipVia
To get the monthly sale values, it is required to get the OrderDate based grouping of records. The month-wise sale values can be computed by summing the product of unitPrice and Quantity of each month of each year.
SELECT year , SUM(CASE WHEN month = 1 THEN unitPrice*Quantity END) Jan , SUM(CASE WHEN month = 2 THEN unitPrice*Quantity END) Feb , SUM(CASE WHEN month = 3 THEN unitPrice*Quantity END) Mar , SUM(CASE WHEN month = 4 THEN unitPrice*Quantity END) Apr , SUM(CASE WHEN month = 5 THEN unitPrice*Quantity END) May , SUM(CASE WHEN month = 6 THEN unitPrice*Quantity END) Jun , SUM(CASE WHEN month = 7 THEN unitPrice*Quantity END) Jul , SUM(CASE WHEN month = 8 THEN unitPrice*Quantity END) Aug , SUM(CASE WHEN month = 9 THEN unitPrice*Quantity END) Sep , SUM(CASE WHEN month = 10 THEN unitPrice*Quantity END) Oct , SUM(CASE WHEN month = 11 THEN unitPrice*Quantity END) Nov , SUM(CASE WHEN month = 12 THEN unitPrice*Quantity END) Dec FROM (SELECT Invoices.* , EXTRACT(YEAR FROM OrderDate) year , EXTRACT(MONTH FROM OrderDate) month FROM Invoices ) Invoices GROUP BY year ORDER BY year
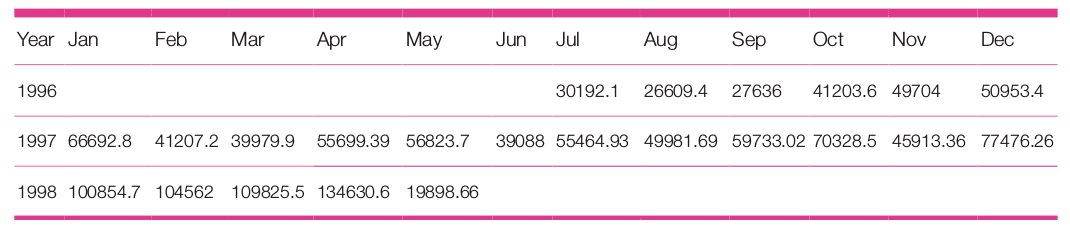
Similar to the last pivot table, this query will produce a report of year-wise monthly sales, as given above. Further statistical analysis may be used for high level analysis of revenue:
SELECT STD(jan_sales), STD(feb_sales), STD(mar_sales), STD(apr_sales), STD(may_sales), STD(jun_sales), STD(jul_sales), STD(aug_sales), STD(sep_sales), STD(oct_sales), STD(nov_sales), STD(dec_sales) FROM (SELECT year , SUM(CASE WHEN month = 1 THEN unitPrice*Quantity END) jan_sales , SUM(CASE WHEN month = 2 THEN unitPrice*Quantity END) feb_sales ….. …… …….. FROM (SELECT Invoices.* , EXTRACT(YEAR FROM OrderDate) year , EXTRACT(MONTH FROM OrderDate) month FROM Invoices ) Invoices GROUP BY year) AS stat
Readers are encouraged to explore pivot tables with other high level data analysis techniques in SQL.















