


























































Entrepreneurial decisions are made using data and business acumen. Big Data is today a tool that helps to maximise revenue and customer engagement. Open source tools like Hadoop, Apache Spark and Apache Storm are the popular choices when it comes to analysing Big Data. As the volume and variety of data in the world grows by the day, there is great scope for the discovery of trends as well as for innovation in data analysis and storage.
In the past five years, the spate of research focused on machine learning has resulted in a boom in the nature and quality of heterogeneous data sources that are being tapped by providers for their customers. Cheaper compute and widespread storage makes it so much easier to apply bulk data processing techniques, and derive insights from existing and unexplored sources of rich user data including logs and traces of activity whilst using software products. Business decision making and strategy has been primarily dictated by data and is usually supported by business acumen. But in recent times it has not been uncommon to see data providing conclusions seemingly in contrast with conventional business logic.
One could take the simple example of the baseball movie ‘Moneyball’, in which the protagonist defies all notions of popular wisdom in looking solely at performance statistics to evaluate player viability, eventually building a winning team of players – a team that would otherwise never have come together. The advantage of Big Data for enterprises, then, becomes a no brainer for most corporate entities looking to maximise revenue and engagement. At the back-end, this is accomplished by popular combinations of existing tools specially designed for large scale, multi-purpose data analysis. Apache, Hadoop and Spark are some of the most widespread open source tools used in this space in the industry. Concomitantly, it is easy to imagine that there are a number of software providers offering B2B services to corporate clients looking to outsource specific portions of their analytics. Therefore, there is a bustling market with customisable, proprietary technological solutions in this space as well.
Traditionally, Big Data refers to the large volumes of unstructured and heterogeneous data that is often subject to processing in order to provide insights and improve decision-making regarding critical business processes. The McKinsey Global institute estimates that data volumes have been growing at 40 per cent per year and will grow 44x between the years 2009 and 2020. But there is more to Big Data than just its immense volume. The rate of data production is an important factor given that smaller data streams generated at faster rates produce larger pools than their counterparts. Social media is a great example of how small networks can expand rapidly to become rich sources of information — up to massive, billion-node scales.
Structure in data is a highly variable attribute given that data is now extracted from across the entire spectrum of user activity. Conventional formats of storage, including relational databases, have been virtually replaced by massively unstructured data pools designed to be leveraged in manners unique to their respective use cases. In fact, there has been a huge body of work on data storage in order to leverage various write formats, compression algorithms, access methods and data structures to arrive at the best combination for improving productivity of the workflow reliant on that data. A variety of these combinations has emerged to set the industry standards in their respective verticals, with the benefits ranging from efficient storage to faster access.
Finally, we have the latent value in these data pools that remains to be exploited by the use of emerging trends in artificial intelligence and machine learning. Personalised advertising recommendations are a huge factor driving revenue for social media giants like Facebook and companies like Google that offer a suite of products and an ecosystem to use them. The well-known Silicon Valley giant started out as a search provider, but now controls a host of apps and most of the entry points for the data generated in the course of people using a variety of electronic devices across the world. Established financial institutions are now exploring the possibility of a portion of user data being put on an immutable public ledger to introduce a blockchain-like structure that can open the doors to innovation. The pace is picking up as product offerings improve in quality and expand in variety. Let’s get a bird’s eye view of this subject to understand where the market stands.
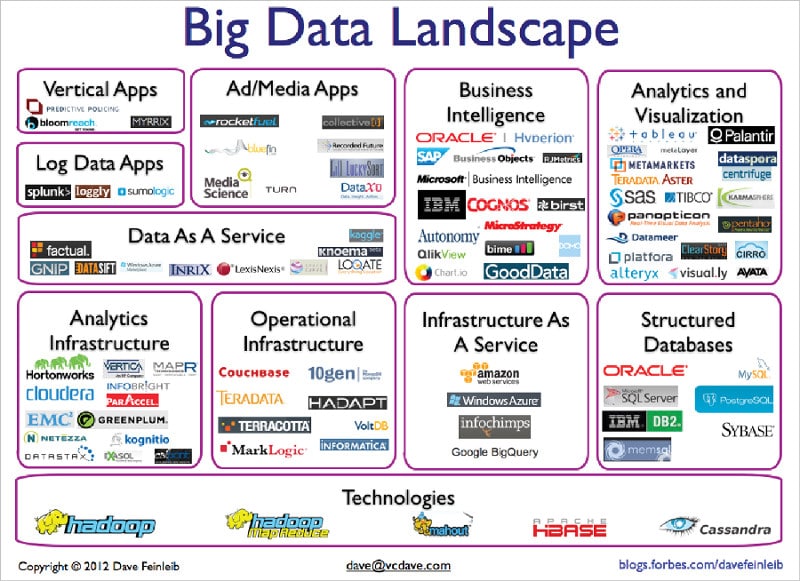
The idea behind building better frameworks is increasingly turning into a race to provide more add-on features and simplify workflows for the end user to engage with. This means the categories have many blurred lines because most products and tools present themselves as end-to-end platforms to manage Big Data analytics. However, we’ll attempt to divide this broadly into a few categories and examine some providers in each of these.
Big Data storage and processing
Infrastructure is the key to building a reliable workflow when it comes to enterprise use cases. Earlier, relational databases were worthwhile to invest in for small and mid-sized firms. However, when the data starts pouring in, it is usually the scalability that is put to the test first. Building a flexible infrastructure comes at the cost of complexity. It is likely to have more moving parts that can cause failure in the short-term. However, if done right – something that will not be easy because it has to be tailored exactly to your company – it can result in life-changing improvements for both users and the engineers working with the said infrastructure to build and deliver state-of-the-art products.
There are many alternatives to SQL, with the NoSQL paradigm being adopted and modified for building different types of systems. Cassandra, MongoDB and CouchDB are some well-known alternatives. Most emerging options can be distinguished based on their disruption, which is aimed at the fundamental ACID properties of databases. To recall, a transaction in a database system must maintain atomicity, consistency, isolation, and durability − commonly known as ACID properties − in order to ensure accuracy, completeness, and data integrity (from Tutorialspoint). For instance, CockroachDB, an open source offshoot of Google’s Spanner database system, has gained traction due to its support for being distributed. Redis and HBase offer a sort of hybrid storage solution while Neo4j remains a flag bearer for graph structured databases. However, traditional areas aside, there are always new challenges on the horizon for building enterprise software.
Backups are one such area where startups have found viable disruption points to enter the market. Cloud backups for enterprise software are expensive, non-trivial procedures and offloading this work to proprietary software offers a lucrative business opportunity. Rubrik and Cohesity are two companies that originally started out in this space and evolved to offer added services atop their primary offerings. Clumio is a recent entrant, purportedly creating a data fabric that the promoters expect will serve as a foundational layer to run analytics on top of. It is interesting to follow recent developments in this burgeoning space as we see competitors enter the market and attempt to carve a niche for themselves with their product offerings.
Big Data analytics in the cloud
Apache Hadoop remains the popular choice for many organisations. However, many successors have emerged to offer a set of additional analytical capabilities: Apache Spark, commonly hailed as an improvement to the Hadoop ecosystem; Apache Storm that offers real-time data processing capabilities; and Google’s BigQuery, which is supposedly a full-fledged platform for Big Data analytics.
Typically, cloud providers such as Amazon Web Services and Google Cloud Platform tend to build in-house products leveraging these capabilities, or replicate them entirely and offer them as hosted services to businesses. This helps them provide enterprise offerings that are closely integrated within their respective cloud computing ecosystem. There has been some discussion about the moral consequences of replicating open source products to profit off closed source versions of the same, but there has been no consensus on the topic, nor any severe consequences suffered on account of this questionable approach to boost revenue.
Another hosted service offering a plethora of Big Data analytics tools is Cloudera which has an established track record in the market. It has been making waves since its merger with Hortonworks earlier this year, giving it added fuel to compete with the giants in its bid to become the leading enterprise cloud provider in the market.
Overall, we’ve seen interesting developments in the Big Data storage and analysis domain and as the volume and variety of data grows, so do the opportunities to innovate in the field.















