



























































Apache SystemML is an important machine learning platform that focuses on Big Data, with scalability and flexibility as its strong points. Its unique characteristics include algorithm customisation, multiple execution modes and automatic optimisation. This article introduces readers to the core features of Apache SystemML.
Machine learning (ML) has applications across various domains, and has transformed the manner in which these are built. The traditional sequential algorithmic approaches are now getting replaced with learning based dynamic algorithms. ML’s most important benefit is its ability to handle novel scenarios.
Machine learning research can be divided into two parts — one is the development of the underlying ML algorithms, which requires a detailed understanding of core mathematical concepts. The other part is the application of machine learning algorithms, which doesn’t require the developer to know the underlying mathematics down to the smallest detail. The second part, i.e., the application of ML, involves people from various domains. For example, ML is now applied in bio-informatics, economics, earth sciences, etc.
Another positive change in the ML space is the creation of various frameworks and libraries by many leading IT majors. These frameworks have made both the development and the application of ML easier and more efficient. As of 2019, developers no longer need to burden themselves with the implementation of core components. Most of these components are available as off-the-shelf solutions.
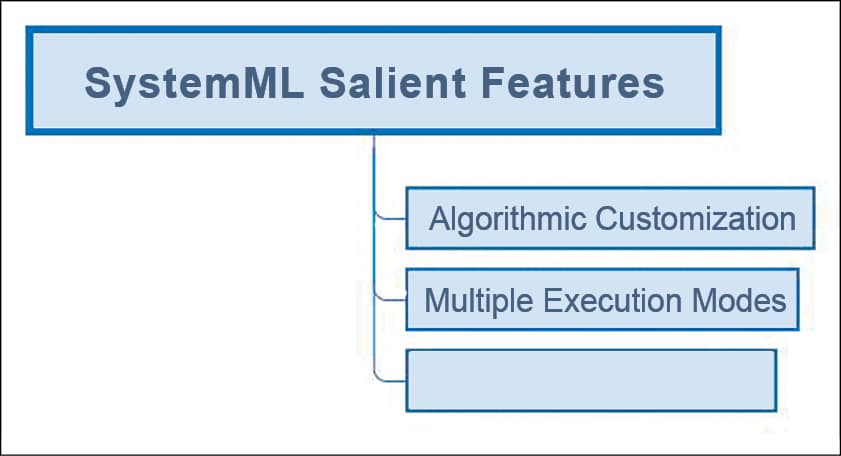
This article explores an important machine learning platform from Apache called SystemML, which focuses on Big Data. The sheer volume and velocity of Big Data poses the challenge of scalability. One of the important advantages of Apache SystemML is its ability to handle these scalability problems. The other distinguishing features of Apache SystemML (Figure 2) are:
- The ability to customise algorithms with the help of R-like and Python-like programming languages.
- The ability to work in multiple execution modes, which incorporate Spark MLContext, Spark Batch, etc.
- The ability to do optimisation automatically, which is based on the characteristics of both the data and cluster.
Apache SystemML has various components, all of which cannot be covered in this article. Here, we provide an introduction to the core features of Apache SystemML.
Installation
The pre-requisite for the installation of Apache SystemML is Apache Spark. The variable SPARK_HOME should be set to the location where Spark is installed.
Installing Apache SystemML for the Python environment can be done with the Pip command as shown below:
pip install systemml |
More information about this can be accessed at http://systemml.apache.org/docs/1.2.0/index.html.
If you want to work with the Jupyter Notebook, the configuration can be done as follows:
PYSPARK_DRIVER_PYTHON=jupyter PYSPARK_DRIVER_PYTHON_OPTS=”notebook” pyspark —master local[*] —conf “spark.driver.memory=12g” —conf spark.driver.maxResultSize=0 —conf spark.default.parallelism=100 |
Instructions for installing SystemML with Scala can be got from the official documentation at http://systemml.apache.org/install-systemml.html.
DML and PyDML
As stated earlier, flexibility is another advantage of SystemML, which it achieves through a high level declarative machine learning language. This language ships in two flavours—one is called DML and has syntax like R. The other is PyDML, which is like Python.
A code snippet of PyDML is shown below: aFloat = 3.0bInt = 2print(‘aFloat = ‘ + aFloat)print(‘bInt = ‘ + bInt)print(‘aFloat + bInt = ‘ + (aFloat + bInt))print(‘bInt ** 3 = ‘ + (bInt ** 3))print(‘aFloat ** 2 = ‘ + (aFloat ** 2))cBool = Trueprint(‘cBool = ‘ + cBool)print(‘(2 < 1) = ‘ + (2 < 1))dStr = ‘Open Source’eStr = dStr + ‘ For You’print(‘dStr = ‘ + dStr)print(‘eStr = ‘ + eStr) |
A sample code snippet of DML is shown below:
aDouble = 3.0bInteger = 2print(‘aDouble = ‘ + aDouble)print(‘bInteger = ‘ + bInteger)print(‘aDouble + bInteger = ‘ + (aDouble + bInteger))print(‘bInteger ^ 3 = ‘ + (bInteger ^ 3))print(‘aDouble ^ 2 = ‘ + (aDouble ^ 2))cBoolean = TRUEprint(‘cBoolean = ‘ + cBoolean)print(‘(2 < 1) = ‘ + (2 < 1))dString = ‘Open Source’eString = dString + ‘ For You’print(‘dString = ‘ + dString)print(‘eString = ‘ + eString) |
A basic matrix operation with PyDML is shown below:
A = full(“1 2 3 4 5 6”, rows=3, cols=2)print(toString(A))B = A + 4B = transpose(B)print(toString(B))C = dot(A, B)print(toString(C))D = full(5, rows=nrow(C), cols=ncol(C))D = (C - D) / 2print(toString(D)) |

A detailed reference to PyDML and DML is available in the official documentation at https://apache.github.io/systemml/dml-language-reference.html.
For the benefit of Python users, SystemML has several language-level APIs, which enable you to use it without needing to know DML or PyDML.
import systemml as smlimport numpy as npm1 = sml.matrix(np.ones((3,3)) + 2)m2 = sml.matrix(np.ones((3,3)) + 3)m2 = m1 * (m2 + m1)m4 = 1.0 - m2m4.sum(axis=1).toNumPy() |
Calling SystemML algorithms
SystemML has a sub-package called mllearn, which enables Python users to call SystemML algorithms. This is done with Scikit-learn or the MLPipeline API.
A sample code snippet for linear regression is shown below:
import numpy as npfrom sklearn import datasetsfrom systemml.mllearn import LinearRegression#1 Load the diabetes datasetdiabetes = datasets.load_diabetes()# 2 Use only one featurediabetes_X = diabetes.data[:, np.newaxis, 2]#3 Split the data into training/testing setsX_train = diabetes_X[:-20]X_test = diabetes_X[-20:]#4 Split the targets into training/testing setsy_train = diabetes.target[:-20]y_test = diabetes.target[-20:]#5 Create linear regression objectregr = LinearRegression(spark, fit_intercept=True, C=float(“inf”), solver=’direct-solve’)#6 Train the model using the training setsregr.fit(X_train, y_train)y_predicted = regr.predict(X_test)print(‘Residual sum of squares: %.2f’ % np.mean((y_predicted - y_test) ** 2)) |
The output of the above code is shown below:
Residual sum of squares: 6991.17 |
A sample code snippet with the MLPipeline interface and the logistic regression is shown below:
# MLPipeline wayfrom pyspark.ml import Pipelinefrom systemml.mllearn import LogisticRegressionfrom pyspark.ml.feature import HashingTF, Tokenizertraining = spark.createDataFrame([(0, “a b c d e spark”, 1.0),(1, “b d”, 2.0),(2, “spark f g h”, 1.0),(3, “hadoop mapreduce”, 2.0),(4, “b spark who”, 1.0),(5, “g d a y”, 2.0),(6, “spark fly”, 1.0),(7, “was mapreduce”, 2.0),(8, “e spark program”, 1.0),(9, “a e c l”, 2.0),(10, “spark compile”, 1.0),(11, “hadoop software”, 2.0)], [“id”, “text”, “label”])tokenizer = Tokenizer(inputCol=”text”, outputCol=”words”)hashingTF = HashingTF(inputCol=”words”, outputCol=”features”, numFeatures=20)lr = LogisticRegression(sqlCtx)pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])model = pipeline.fit(training)test = spark.createDataFrame([(12, “spark i j k”),(13, “l m n”),(14, “mapreduce spark”),(15, “apache hadoop”)], [“id”, “text”])prediction = model.transform(test)prediction.show() |
Deep learning with SystemML
Deep learning has evolved into a specialised class of machine learning algorithms, which makes handling of features simple and efficient. SystemML also has support for deep learning. There are three methods with which deep learning can be carried out in SystemML (Figure 3):
- With the help of the DML-bodied NN library. This enables the utilisation of DML to implement neural networks.
- Caffe2DML API: This API enables the model to be represented in Caffe’s proto format.
- Keras2DML API: This API enables the model to be represented in Keras.
A code snippet with Kears2DML, to implement ResNet50, is shown below:
import osos.environ[‘CUDA_DEVICE_ORDER’] = ‘PCI_BUS_ID’os.environ[‘CUDA_VISIBLE_DEVICES’] = ‘’# Set channel first layerfrom keras import backend as KK.set_image_data_format(‘channels_first’)from systemml.mllearn import Keras2DMLimport systemml as smlimport keras, urllibfrom PIL import Imagefrom keras.applications.resnet50 import preprocess_input, decode_predictions, ResNet50keras_model = ResNet50(weights=’imagenet’,include_top=True,pooling=’None’,input_shape=(3,224,224))keras_model.compile(optimizer=’sgd’, loss= ‘categorical_crossentropy’)sysml_model = Keras2DML(spark,keras_model,input_shape=(3,224,224), weights=’weights_dir’, labels=’https://raw.githubusercontent.com/apache/systemml/master/scripts/nn/examples/caffe2dml/models/imagenet/labels.txt’)sysml_model.summary()urllib.urlretrieve(‘https://upload.wikimedia.org/wikipedia/commons/f/f4/Cougar_sitting.jpg’, ‘test.jpg’)img_shape = (3, 224, 224)input_image = sml.convertImageToNumPyArr(Image.open(‘test.jpg’), img_shape=img_shape)sysml_model.predict(input_image) |
As the SystemML is still evolving, the road map for future features includes enhanced deep learning support, support for distributed GPUs, etc.
To summarise, SystemML aims to position itself as SQL for machine learning. It enables developers to implement and optimise machine learning code with ease and effectiveness. Scalability and performance are its major advantages. The ability to run on top of Spark makes automatic scaling possible. With the planned expansion of deep learning features, SystemML will become stronger in future releases. If you are a machine learning enthusiast, then SystemML is a platform that you should try.











