

























































In tests, PlaNet agent outperforms model-free methods like A3C and D4PG on image-based tasks

Google in collaboration with DeepMind has introduced the Deep Planning Network (PlaNet) agent, which learns a world model from image inputs and leverages it for planning.
PlaNet can solve a variety of image-based control tasks, competing with advanced model-free agents in terms of final performance while being 5,000 per cent more data efficient on average – Danijar Hafner, a student researcher at Google AI, writes in a blog post.
The source code has been released on GitHub.
How PlaNet Works
Danijar Hafner, who is also co-author of the academic paper describing PlaNet’s architecture, explains – “PlaNet learns a dynamics model given image inputs and efficiently plans with it to gather new experience.”
In contrast to previous methods that plan over images, the researcher says, they rely on a compact sequence of hidden or latent states, called a latent dynamics model.
He elaborates, “Instead of directly predicting from one image to the next image, we predict the latent state forward. The image and reward at each step are then generated from the corresponding latent state. By compressing the images in this way, the agent can automatically learn more abstract representations, such as positions and velocities of objects, making it easier to predict forward without having to generate images along the way.”
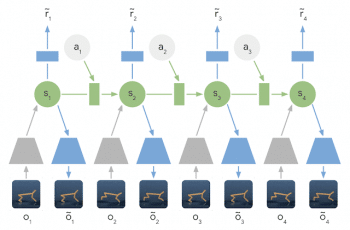
Latent Dynamics Model: The information of the input images is integrated into the hidden states (green) using the encoder network (grey trapezoids). The hidden state is then projected forward in time to predict future images (blue trapezoids) and rewards (blue rectangle).
In contrast to their previous work on world models, PlaNet works without a policy network — it chooses actions purely by planning, and so it benefits from model improvements on the spot, Hafner claims.
For example, he says, “the agent can imagine how the position of a ball and its distance to the goal will change for certain actions, without having to visualize the scenario. This allows us to compare 10,000 imagined action sequences with a large batch size every time the agent chooses an action. We then execute the first action of the best sequence found and replan at the next step.”
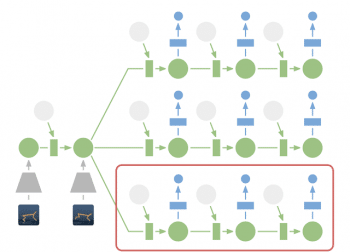
Planning in Latent Space: For planning, Google AI team encodes past images (gray trapezoid) into the current hidden state (green). From there, they efficiently predict future rewards for multiple action sequences and then execute the first action of the best sequence found (red box)
PlaNet agent outperforms model-free methods
Google says that in tests PlaNet agent outperformed model-free methods like A3C and D4PG on image-based tasks.
“PlaNet clearly outperforms A3C on all tasks and reaches final performance close to D4PG while, using 5000% less interaction with the environment on average,” the tech giant writes in the blog.
Additionally, when PlaNet was placed randomly into different environments without knowing the task, it managed to learn all six tasks without modification in as little as 2,000 attempts.
The researchers believe that scaling up the processing power could produce an even more robust model.















