





























































In this month’s column, we discuss a new text mining task called machine reading comprehension.
Over the past couple of months, we have been discussing the problem of detecting duplicate questions in community question answering (CQA) forums using the Quora question pair data set. In this month’s column, let’s discuss a closely related problem, namely, machine reading comprehension. This is an important language-related task in artificial intelligence (AI).
Artificial intelligence has seen rapid progress over the last few years, with a number of state-of-art advances in vision, speech and language. Computing intelligence has evolved from simple number crunching tasks to perceptual computing tasks, whereby machines can take sensory inputs from the surrounding environment such as vision, speech, etc. The next step in the evolution of computing intelligence is cognitive intelligence computing, where machines can read language/text, understand meanings, reason based on the information they have read, and make decisions even in complex scenarios, on par with human intelligence. This requires that machines have the ability to read text, understand it, extract meaning from it and reason, based on its understanding.
There are a number of language related tasks pertaining to AI. These include information extraction, information search, dialogue, and of course question answering (QA). It is possible to frame all the other tasks as QA. For instance, information search can be framed as asking questions/queries, with the machines retrieving the relevant answer in an interactive fashion from the Web/external knowledge bases. Dialogue can be framed as conversational QA, of which a popular example is Apple’s Siri. Question answering is an AI complete problem, in the sense that finding a good solution to QA will enable solutions to other language related AI tasks.
QA became a popular AI task when IBM demonstrated it in the AI Grand Challenge. In the popular TV game show ‘Jeopardy’, the machine intelligence of IBM Watson was pitted against human contestants Ken Jennings and Brad Ritter. IBM Watson used many of the natural language processing techniques such as ‘similar question retrieval’, summarisation, key passage identification and answer sentence extraction to beat the humans. This was possibly the first well-known demonstration of machines performing the QA task and fuelled the public’s imagination.
Machine QA has a number of flavours. Given a question, the machine can look through external knowledge bases and try to find an answer. For this problem, it needs to convert the natural language question into a logical form, which can be used to query the external knowledge base. A particular NLP technique known as semantic parsing is used to convert a natural language query into a logical form, specific to the schema of the external knowledge base. The logical query can be used to retrieve results from the external knowledge base. While this can be used for structured external knowledge bases, there are a number of unstructured text documents that contain the information required to answer the questions. For instance, many of the factual questions can be answered using Wikipedia, which contains a number of articles on different topics. Hence, answering questions related to each of these topics requires reading the Wikipedia text. The machines can then answer questions that are based on the text read. This has given rise to a specific form of AI QA task known as machine reading comprehension (MRC).
Here is an MRC task: Given a passage P, and a question Q related to that passage, the QA system needs to provide answer A to the given question. There can be more than one question, as is typically the case in reading comprehension tasks. There can be two variants to this task. The simplest variant is the answer extraction task, where the exact answer A to question Q is present in the passage P. This is known as the answer extraction task. A more complicated variant is the answer generation task. In this case, the exact answer is not present directly in the passage P. Instead, the program has to synthesise/generate the answer A based on the information contained in the passage P. This is known as the answer generation task.
Here is an example of the answer extraction task:
| Passage P | Question Q | Answer A |
| Alyssa reached the beach after a long trip. She’s from Charlotte. She travelled from Atlanta. She’s now in Miami. She went to Miami to visit some friends. But she wanted some time to herself at the beach, so she went there first. After swimming in the ocean and lazing on the beach, she went to her friend Ellen’s house. Ellen greeted Alyssa and both had some lemonade to drink. Alyssa called her friends Kristin and Rachel to meet at Ellen’s house. | What city is Alyssa in? | Miami |
Now that we have understood the MRC problem, and the data sets that are available, let us quickly think about how we can approach this problem. Reading comprehension is a task done easily by most humans. We generally do a quick parse of the passage P first, then go over the question Q once, and again scan the passage P to find the relevant sentences to answer Q. We can design a simple baseline neural QA system to solve the MRC task based on a similar approach.SQuAD contains more than 200,000 questions with passages retrieved from Wikipedia articles. SquAD’s data set is a machine comprehension data set for the answer extraction task. You can explore SQuAD at https://rajpurkar.github.io/SQuAD-explorer/. The SQuAD leaderboard also shows the links to several of the techniques that have been applied to it. A popular data set for the answer generation variant of the MRC task is the MS-MARCO data set.
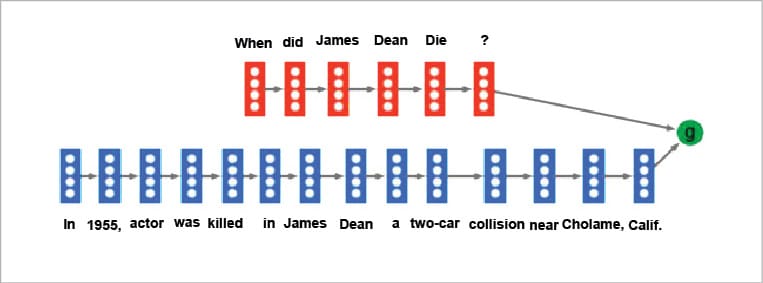
As we did in the duplicate question detection task, we first create a fixed length representation of question Q by passing it through a recurrent neural network such as LSTM. We also build a fixed length representation of passage P by passing it through another LSTM. We can then combine the two fixed length representations through an encoder. The combined representation is then used to predict the answer location in the passage. This simple approach is shown in Figure 1.
While this approach is conceptually simple and easy to understand, it has a number of drawbacks. By first encoding the question and the passage into fixed length representations, we compress the information contained in the text. This results in loss of information in matching the question to the relevant sentences which contain the answer in the passage P. One way of solving this problem is to adopt a two-stage approach. The first stage is to analyse the passage with the question Q to identify the key supporting fact in the passage P which can help answer the question. In the second stage, we build a representation of the passage where the key supporting fact is given the highest weightage among all the sentences contained in it. The representation of the encoded passage is then combined with the question and passed through the decoder, to predict the answer words present in the passage. This technique is known as ‘memory networks’ and we will discuss it in detail in next month’s column.
If you have any favourite programming questions/software topics that you would like to discuss on this forum, please send them to me, along with your solutions and feedback, at sandyasm_AT_yahoo_DOT_com. Wishing all our readers happy coding until next month!














