





























































Splinter is a Web application testing tool which is built around Python. It automates actions such as visiting specified URLs and interacts with their items. It also removes the drudgery from Web application testing by replacing manual testing with automated testing.
Every one of us makes mistakes—some of these might be trivial and be ignored, while a few that are serious can’t be ignored. Hence, it’s always a good practice to verify and validate what we do in order to eliminate the possibility of error. So is the case with any software application. The development of a software application is complete only when it’s fully verified and validated (its functionality, performance, user interface, etc). Only then is it ready for release. Carrying out all such validations manually is quite time consuming; so, machines perform such repetitive tasks and processes. This is called automation testing. It saves a lot of time while it reduces the risk of any further error caused by human intervention.
There are different automation tools and frameworks available, of which Splinter is one. It lets us automate different manual tasks and processes associated with any Web-based software application. In a Web application, we need to automate the sequence of different actions performed, right from opening the Web browser to checking if it’s loading properly for different actions that involve interactions with the application. Splinter is quite good in automating a sequence of actions. It is an open source tool used for testing different Web applications using Python. The tasks needed to be performed by Splinter are written in Python. It lets us automate various browser actions, such as visiting URLs as well as interacting with their different items. It has got easy-to-use built-in functions for the most frequently performed tasks. A newbie can easily use Splinter and automate any specific process with just a limited knowledge of Python scripting. It acts as an easily usable abstraction layer on top of different available automation tools like Selenium and makes it easy to write automation tests. We can easily automate a plethora of tasks such as opening a browser, clicking on any specific link or accessing any link, just with one or two lines of code using Splinter, while in the case of other open source tools like Selenium, this is a long and complex process.
Splinter even allows us to find different elements of any Web application using its different properties like tag name, text or ID value, xpath, etc. Since Splinter is an open source tool, it’s quite easy to get clarifications on anything that’s not clear. It is supported by a large community. It even has well maintained documentation which makes it easy for any newbie to master this tool. Apart from all this, Splinter supports various inbuilt libraries making the task of automation easier. We can easily manage different actions performed on more than one Web window at the same time as well as navigate through the history of the page, reload the page, etc.
Features of Splinter
1. Splinter has got one of the simplest APIs among open source tools used for automating different tasks on Web applications. This makes it easy to write automated tests for any Web application.
2. It supports different Web drivers for various browsers. These drivers are the Firefox Web driver for Mozilla Firefox, Chrome’s Web driver for Google Chrome, PhantomJs Web driver for PhantomJs, zope.testbrowser for Zopetest and a remote Web driver for different ‘headless’ (with no GUI) testing.
3. Splinter also allows us to find different elements in any Web page by their Xpath, CSS, tag value, name, ID, text or value. In case we need more accurate control of the Web page or we need to do something more, such as interacting with old «frameset» tags, Splinter even exposes the Web driver that allows us to use the low level methods used for interacting with that tag.
4. Splinter supports multiple Web automation back-ends. We can use the same set of test code for doing browser-based testing with Selenium as its back-end, and for ‘headless’ testing with zope.testbrowser as its back-end.
5. It has extensive support for using iframes and interacts with them by just passing the iframe’s name, ID or index value. There is also Chrome support for various alerts and prompts in the Splinter 0.4 version.
6. We can easily execute JavaScript in different drivers which support Splinter. We can even return the result of the script using an inbuilt method called evaluate_script.
7. Splinter has got the ability to work with AJAX and asynchronous JavaScript using various inbuilt methods.
8. When we use Splinter to work with AJAX and asynchronous JavaScript, it’s a common experience to have some elements which are not present in HTML code (since they are created using JavaScript, dynamically). In such cases, we can use various inbuilt methods such as is_element_present or is_text_present for checking the existence of any specific element or text. Splinter will actually load the HTML and the JavaScript in the browser, and the check will be performed before JavaScript is processed.
9. The Splinter project has full documentation for its APIs and this is really important when we have to deal with different third party libraries.
10. We can also easily set up a Splinter development environment. We need to make sure we have some basic development tools in our machine, before setting up an entire environment with just one command.
11. There is also a provision for creating a new Splinter browser in an easy and simple way. We just need to implement a test case for this.
12. Using Splinter, it’s possible to check the HTTP status code that a browser visits. We can use the status_code.is_success method to do the work for us. We can compare the status code directly.
13. Whenever we use the visit method, Splinter actually checks if the given response is a success or not, and if it is not, then Splinter raises an HttpResponseError exception. This helps to confirm if the given response is okay or not.
14. It is possible to manipulate the cookies that are using the cookies’ attributes from any browser instance. The cookie’s attribute is actually an instance of a CookieManager class which manipulates cookies, such as adding and deleting them.
15. One can create new drivers using Splinter. For instance, if we need to create a new Splinter browser, we just need to implement a test case (extending test.base.BaseBrowsertests). All this will be present in a Python file, which will act as a driver for any future usage.
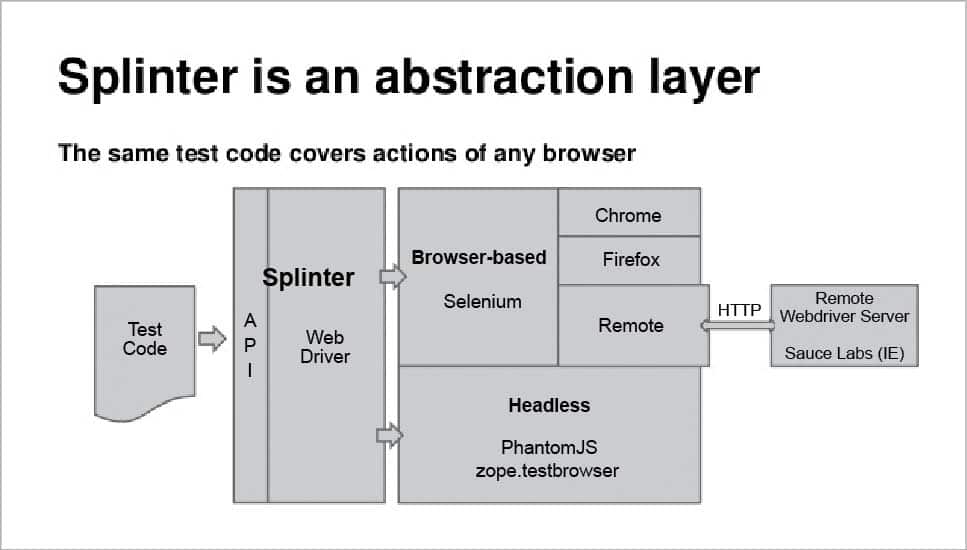
Drivers supported by Splinter
Drivers play a significant role when it comes to any Web application. In Splinter, a Web driver helps us open that specific application whose driver we are using. Different types of drivers are supported by Splinter, based on the way any specific application is accessed and tested. There are browser based drivers, which help to open specific browsers; apart from that we have headless drivers, which help in headless testing and then there are remote drivers, which help to connect to any Web application present on a remote machine. Here is a list of drivers that are supported by Splinter.
Browser based drivers:
- Chrome WebDriver
- Firefox WebDriver
- Remote WebDriver
Headless drivers
- Chrome WebDriver
- Phantomjs WebDriver
- zope.testbrowser
- Django client
- Flask client
Remote driver
- Remote WebDriver
Prerequisites and installation of Splinter
To install Splinter, Python 2.7 or above should be installed on the system. We can download Python from http://www.python.org.Make sure you have already set up your development environment.
Git should be installed on the system. If you want to use Google Chrome as the Web browser, make sure Chrome WebDriver is set up properly.
There are two ways in which we can install Splinter.
To install the stable release:
To install the official and bug-free version, run the following command from a terminal:
$ [sudo] pip install splinter
For installing under-development source-code:
To get Splinter’s latest and best features, just run the following given set of commands from a terminal:
$ git clone git://github.com/cobrateam/splinter.git $ cd splinter $ [sudo] python setup.py install
Writing sample code to automate a process using Splinter
As already stated, even a newbie without much knowledge of programming can automate any specific task using Splinter. Let’s discover how one can easily make Splinter perform any specific task automatically on a Web application. The credit for the ease of coding actually goes to the different inbuilt functions that Splinter possesses. We just need to incorporate all such built-in functions or library files with the help of a few lines of code. Additionally, we need to apply logic while coding to validate different scenarios from different perspectives. Let’s have a look at one of the sample code snippets that has been written for Splinter. Here, we make use of the name and ID values of different elements present on the Web page to identify that specific Web element.
Scenario for sample code: Login to a Facebook account using the user’s email ID and password.
#imports the Browser library for Splinter from splinter import Browser # takes the email address from user as input to login to his/her Facebook account user_email = raw_input(“enter users email address “) # takes the password from user as input to login to his/her Facebook account user_pass = raw_input(“enter users password “) # loads the Firefox browser browser= Browser(‘firefox’) # stores the URL for Facebook in url variable url = “https://www.facebook.com/” #navigates to facebook website and load that in the Firefox browser browser.visit(url) #checks if Facebook web page is loaded else prints an error message if browser.is_text_present(‘www.facebook.com’): # fills the user’s email ID and password in the email and password field of the facebook login section #Inbuilt function browser.fill uses the tag name for Email and Password input box i.e. email and pass respectively to identify it browser.fill(‘email’, user_email) browser.fill(‘pass’, user_pass) #selects the login button using its id value present on the Facebook page to click and log in with the given details button = browser.find_by_id(‘u_0_d’) button.click() else: print(“Facebook web application NOT FOUND”)
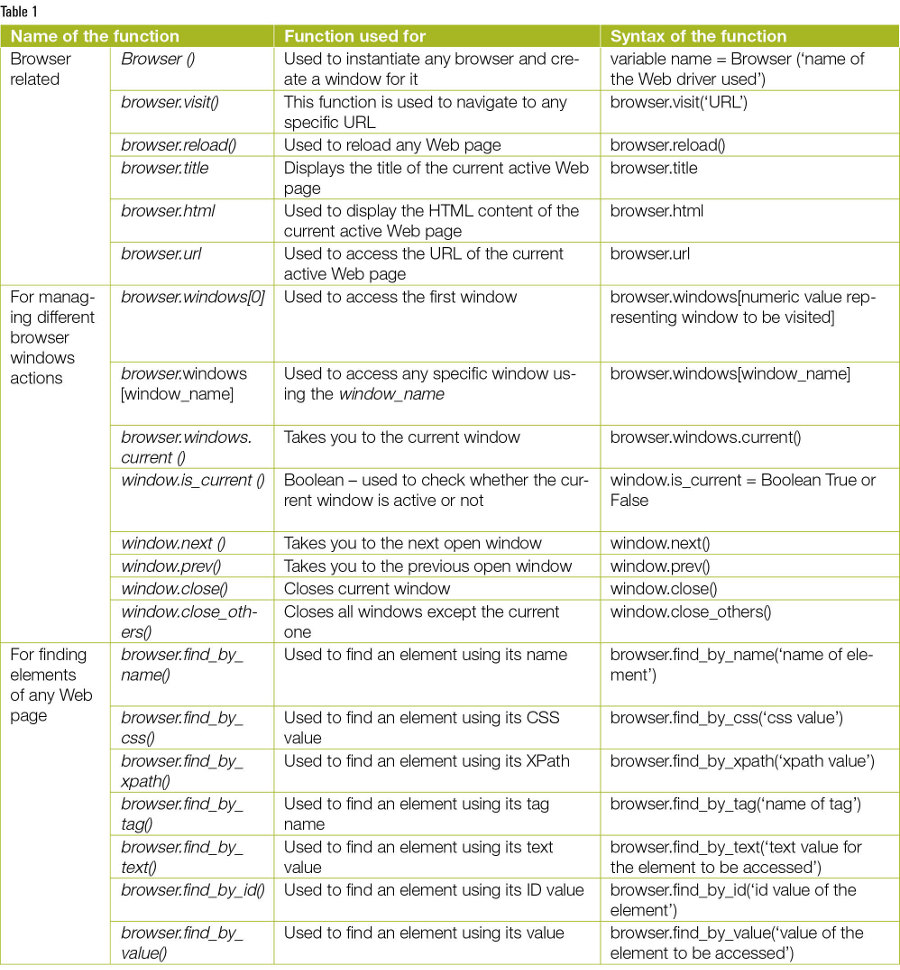
Some important built-in functions used in Splinter
Table 1 lists some of Splinter’s significant built-in functions that can be used while automating any process for a Web application.
 Setting up the Splinter development environment
Setting up the Splinter development environment
When it comes to programming in Splinter, we have already seen that it’s easier than other open source Web application testing tools. But we need to set up a development environment for it, wherein we can easily code or automate a specific process using Splinter. This is not a tough task. We just need to make sure that we have some basic development tools, library files and a few add-on dependencies on our machine, which will ultimately help us code in an easier and better way. We can get the required tools and set up the entire environment using just a few commands.
Lets’ have a look at the different development tools required to set up the environment.
Basic development tools: If you are using the Mac OS, install the Xcode tool. It can be downloaded from the Mac Application Store (on the Mac OS X Lion) or even from the Apple website.
If you are using a Linux computer, install some of the basic development libraries and the headers. On Ubuntu, you can easily install all of these using the apt-get command. Given below is the command used for this purpose.
$ [sudo] apt-get install build-essential python-dev libxml2-dev libxslt1-dev
Pip and virtualenv: First of all, we need to make sure that we have Pip installed in our system, with which we manage all the Splinter development dependencies. It lets us program our task and makes the system perform any activity using the code or command we write. It’s advisable to choose virtualenv for a good development environment.
Once we have all the development libraries installed for the OS we are using, we just need to install all the Splinter development dependencies using the make command. Given below is the command for this.
$ [sudo] make dependencies
We will use sudo while making dependencies only if we are not using virtualenv.














