




























































This article is a continuation of our series on regular expressions, and discusses regular expressions in Perl.
Perl is a general-purpose, interpreted programming language that is most suitable for text processing. Like any other programming language that is mainly used for text processing, Perl also has its own powerful repertoire of regular expressions. In fact, it is a trendsetter in this regard. The regular expression style used in Perl is so well known that it is often called Perl-style regular expressions. It is even adopted by many other popular programming languages, and some even advertise that their regular expressions are as powerful as Perl regular expressions. As mentioned in the previous article in this series, even Python uses Perl-style regular expressions with the help of a regular expression engine called PCRE (Perl Compatible Regular Expressions).
Perl 5 or Perl 6?
Perl was developed by Larry Wall in 1987. Perl is not an acronym but nowadays the backronym Practical Extraction and Report Language is gaining popularity. Perl 5 and Perl 6 are the two active versions of Perl currently being developed and maintained. The command perl -v executed on the terminal will tell you the version installed in your system. Most of the popular Linux distributions have Perl 5 as the default option. The only major complete implementation of Perl 6 is called the Rakudo compiler. So, if you want Perl 6 installed in your system, use the Rakudo Perl compiler.
In the beginning of this article, I have called Perl an interpreted language and now I say that Perl 6 has a compiler. I am sure two things are clear from this. First, Perl 5 and Perl 6 have some major differences between them. Second, people still mean Perl 5 and not Perl 6 when they say Perl. If this article was about the programming language Perl in general, then I would have explained a lot of differences between Perl 5 and Perl 6. But in this article, I am only interested in regular expressions in Perl and nothing more. Unlike Python 2 and Python 3, where the differences in regular expressions are minimal or negligible, Perl 5 and Perl 6 regular expressions have some major differences.
After some consideration, I have decided to stick with Perl 5 and its regular expressions. I would like to point out the reasons for this choice. First, Perl 5 is still the widely accepted Perl standard. Perl 6 might be the future of Perl but compatibility with Perl 5 is not a goal for Perl 6. In fact, some of the Perl 5 fans even complain that Perl 6 is not even real Perl. The two are so different that the Perl camel is no longer the mascot of Perl 6; instead, it is Camelia the butterfly for Perl 6. Also remember that the Perl Foundation supports the onion symbol as the mascot of Perl 5, not the camel. Figure 1 shows the camel of Perl 5 propagated by the O’Reilly media, the onion symbol supported by the Perl Foundation and the butterfly of Perl 6.

So, if I centre my discussions around Perl 6, many of the Perl 5 developers who are far more in number, may not like the code being discussed. This might be the practical reason for sidestepping Perl 6. But there is a theoretical reason also for not preferring Perl 6. The regular expressions used in Perl 6 are so powerful that they are no longer regular expressions. In theory, regular expressions should be only as powerful as finite automata and regular grammars. To a great extent this is true in the case of Perl 5 regular expressions. As an aside, even Perl 5 regular expressions are slightly more powerful than ‘regular’ regular expressions of theoretical computer science, but Perl 6 regular expressions called Perl 6 rules (which form a superset of Perl 5 regular expressions) can even perform parsing. Those who are familiar with compilers will remember that true regular expressions and regular grammars do not have the ability to perform parsing, also known as syntax analysis. So even though Perl 6 rules are more powerful than Perl 5 regular expressions, they are not strictly regular expressions. Due to these reasons, all the scripts and regular expressions used in this article have been tested with Perl 5 and for the rest of this article, when I say Perl, I mean Perl 5.
Perl script or Perl program?
Before starting a discussion about Perl regular expressions, I would like to explain a complete Perl script is. And, maybe even before doing that, I would like to clarify why I will call it a Perl script and not a Perl program. Well, computer science is not like physics or chemistry, which are both based on strong theoretical foundations. Computer science is far more practical and does not need any theory of gravity or relativity, or Charle’s Law or Boyle’s law to change the world. But an unfortunate side effect of this is that some of the topics in computer science are highly subjective and, hence, resolving certain issues often depends on individual perspectives and choices. For example, the piece of code I call a Perl script might be called a Perl program by you. But I am following the popular convention, whereby code written in a compiled language is called a program and what’s written in an interpreted or a scripting language is called a script. So, we have C, C++ and Java programs and Python, Perl and PHP scripts. With that matter resolved, let us move on to the next problem.
A complete Perl script
Let me present and explain a complete Perl script called first.pl:
print “Hello World” |
This script prints the message ‘Hello World’ on the screen. And yes, this is indeed a complete Perl script. This may not be a surprise to you if you are familiar with a language like Python, but if you are a practitioner of languages like C, C++ or Java, this might be a bit surprising. In languages like Perl, you only need to describe the things the program should do. In Perl, the script begins when the code begins and you don’t need to specify the beginning of a script with some special syntax. Similarly, Perl assumes that the script is over when the code ends and you don’t have to add any special commands to denote the end of a script. These and many other features make Perl scripts extremely short. This is one of the reasons why it is very popular nowadays, even when there are a bunch of other programming languages to choose from.
Perl is often used as a rapid prototyping language and in fact, the things that can be achieved with the help of Perl one-liners (single line Perl scripts) are so amazing that C, C++ and Java aficionados may not even believe them. The script first.pl can be executed by invoking the Perl interpreter as perl first.pl. Remember, the name of the language is Perl with an upper case P and the name of the interpreter is perl with a lower case p.
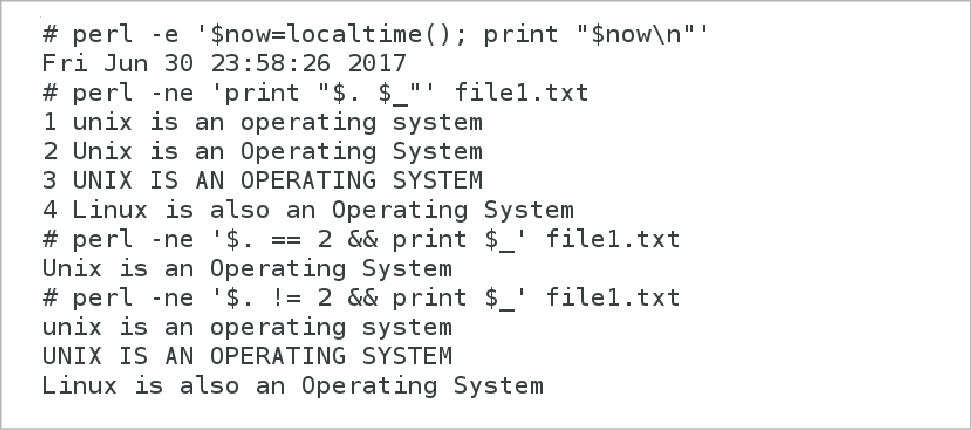
Perl one-liners can be directly executed on the terminal with the switches -e or -E enabled, such as perl -e ‘print “Hello World”’. The switches -e and -E tell the interpreter of Perl that one or more lines of Perl code are provided instead of the name of a Perl script. The current date and time can be printed using Perl as follows:
perl -e ‘$now=localtime(); print “$now\n”’ |
Here, we are using the function localtime( ). To test some of the Perl one-liners, we will use the same text file file1.txt used in the previous article in this series.
unix is an operating systemUnix is an Operating SystemUNIX IS AN OPERATING SYSTEMLinux is also an Operating System |
What is the output of the following Perl one-liner?
perl -ne ‘print “$. $_”’ file1.txt. |
Every line in the text file file1.txt is displayed on the screen along with line numbers, and the text file file1.txt remains unchanged. The special variable $. holds the line number of the current line and the special variable $_ contains the entire line currently being processed by Perl. So, here the line number is appended with the content of each line. What is the output of the following one-liner?
perl -ne ‘$. == 2 && print $_’ file1.txt |
Here, only line No. 2 of the text file file1.txt is printed on the screen. Then what about:
perl -ne ‘$. != 2 && print $_’ file1.txt |
In this case, every line of the text file file1.txt except line No. 2 is printed on the screen. The trick lies with the switch -n of Perl. The switch -n will create the effect of a loop, so that the Perl script following this switch will be executed on every line of the text file being processed, thereby creating the effect of an AWK script. By the way, AWK is another text processing language still used (though Perl is much more popular) but mostly abandoned by professional programmers. Figure 2 shows the output of the Perl one-liners discussed here.
The knowledge of regular expressions will greatly increase the power of Perl one-liners. It is time for us to run a Perl script with a regular expression and for that, too, we will use the text file file1.txt. To process this text file, we have a Perl script called regex1.pl. This and all the other Perl scripts and text files used in this article can be downloaded from opensourceforu.com/ article_source_code/August17perl.zip. The extension of a Perl script is .pl and hence the name regex1.pl. Now it is time to inspect and understand the code of regex1.pl.
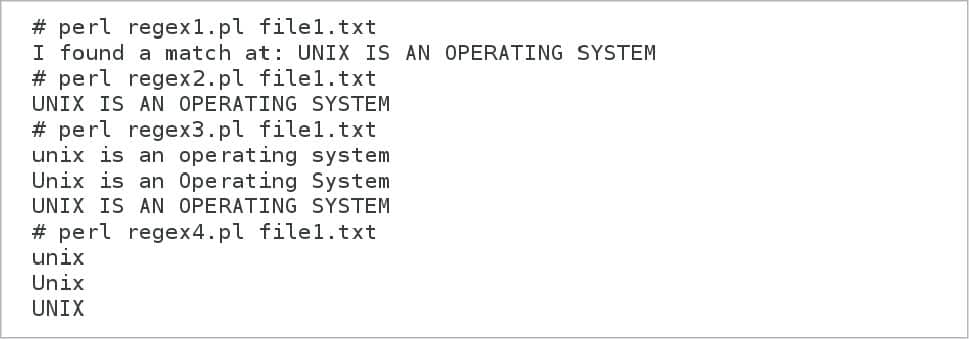
$infile=$ARGV[0];open (DATA,”<$infile”) || die “File $infile Not Found”;while(<DATA>) {if(/UNIX/) {print “I found a match at: $_”;}} |
The first line of code in the script reads the name of the text file to be processed from the command line. The second line of code opens the file specified by the command line argument if it exists, and closes the program if the file does not exist. The third line reads the whole text file, line by line, and the fourth line has an if statement, where a regular expression is tested to true or false. If the regular expression finds a match, the fifth line of code prints the message: ‘I found a match at:’ followed by the contents of the matched line on the screen.
Now, the only thing that matters is the way a regular expression is represented in a Perl script. If you observe carefully, you will see that the regular expression is placed inside a pair of forward slashes—two forward slashes acting as a delimiter for the regular expression. Since we are familiar with the Python regular expressions mentioned in the previous article, it should be clear that the regular expression match operator /UNIX/ will result in a literal match for the string UNIX only. Please note that if abcd is a regular expression, then /abcd/ is the corresponding regular expression match operator. Also, remember that the convention followed in the articles in this series is that all the regular expressions and commands are italicised to highlight them from normal text.
The line of code print “I found a match at: $_” replaced with the line of code print “$_” will result in printing just the lines matched by a regular expression. This code can be found in the Perl script regex2.pl. This is just one way of specifying a regular expression in Perl; the regular expressions are placed inside forward slashes, like /abcd/. Some operators like m//, s///, etc, are also used for processing text files with Perl regular expressions, and they will be discussed later in this article.

For the given text file, only one line results in a match for the regular expression /UNIX/. Hence a single statement, “I found a match at: UNIX IS AN OPERATING SYSTEM” , is printed on screen. So, it is clear that a case-sensitive match is being carried out here in this case. How does one carry out a case-insensitive match in Perl? The line of code if(/UNIX/) replaced with the line of code if(/UNIX/i) will result in a case-insensitive match as well as a match for the words ‘unix’, ‘Unix’ and ‘UNIX’. This code can be found in the Perl script regex3.pl. In this code, the pattern object /UNIX/ is modified with the pattern modifier i for a case-insensitive match. There are other pattern modifiers also used in Perl regular expressions. The pattern modifier s is used to change the behaviour of the metacharacter dot (.). Usually, the newline character \n will not be matched by the dot operator but if the pattern modifier s is used, then even the newline character will be matched. The pattern modifier m will modify how metacharacters ^ and $ are treated in case of a string with an embedded newline character.
Now, the next logical question is how to print the matched string alone and not the entire line of text, where a regular expression match is obtained. For this, we need to make a few modifications in the Perl script regex3.pl. This modified script, called regex4.pl, is shown below.
$infile=$ARGV[0];open (DATA,”<$infile”) || die “File $infile Not Found”;while(<DATA>) {if(/(UNIX)/i) {print “$1\n”;}} |
Changes are made in the fourth and fifth lines of the script regex3.pl. In the fourth line of code if(/UNIX/i) has been made if(/(UNIX)/i). Here, parentheses are used for capturing matched strings in Perl. In the fifth line of code, we are printing $1. Now, what is $1? The special variable $1 holds the instance of a regular expression match. Figure 3 shows the output while processing file1.txt using the Perl scripts regex1.pl, regex2.pI, regex3.pl and regex4.pl.
Metacharacters in Perl
The following characters: . (dot), ^ (caret), $ (dollar), * (asterisk), + (plus), ? (question mark), { (opening curly bracket), } (closing curly bracket), [ (opening square bracket), ] (closing square bracket), \ (backslash), | (pipe), ( (opening parenthesis) and ) (closing parenthesis) are special symbols used in Perl regular expressions. These are the same set of metacharacters used in Python regular expressions. The meanings of these metacharacters are the same in both Python and Perl, and a somewhat detailed discussion can be found in the previous article in this series. So if the meanings of the metacharacters are the same, what is the difference between the regular expressions (abc){2,} and abc{2,}? The regular expression syntax {2,} mandates at least two occurrences of the preceding regular expression. If so, why are the two different? The regular expression (abc){2,} matches the strings in the set {abcabc, abcabcabc, abcabcabc, …} whereas abc{2,} matches the strings in the set {abcc, abccc, abcccc, …}. This is due to the effect of the grouping operator opening and closing parentheses in the regular expression (abc){2,}. To test the effect of these regular expressions, let us use a text file called file2.txt with the following content.
abcabccabcccabccccabcabcabcabcabcabcabcabcabcabc |
Try the commands:
perl -ne ‘if(/abc{2,}/){print “$_”}’ file2.txt |
and…
perl -ne ‘if(/(abc){2,}/){print “$_”}’ file2.txt. |
The output of these two commands is shown in Figure 4.
Differences between Perl and Python metacharacters
Though the metacharacters in Perl and Python are almost the same, there are far more metasymbols in Perl. An example of a metasymbol is \d, which denotes a decimal digit. Metasymbols like \v, \V, \h, \H, etc, are used to control the behaviour of whitespace characters. It is not possible to describe all the metasymbols in this article, but keep in mind that many of them won’t ever be used in the programming lifetime of even expert programmers. Perl regular expressions are not only powerful but the interaction between Perl variables and regular expressions is very easy. For example, a regular expression can be stored inside a variable like $s1=”^a.*”. To test this feature of Perl regular expressions, let us consider the text file file3.txt with the following content.
aaaabbbbccccaabbaaccbbaabbccccaaccbb |
Now, execute the command:
perl -ne ‘$s1=”^a.*”; if(/$s1/) { print $_ }’ file3.txt. |
The strings aaaa, aabb and aacc are selected because the regular expression matches the lines of text that start with an a. Similarly, try the command:
perl -ne ‘$s2=”.*c\$”; if(/$s2/) { print $_ }’ file3.txt. |
This will select the strings cccc, aacc and bbcc because the regular expression matches lines of text that end with a c. But what is even more promising is that you can combine these variables to form complex regular expressions. What will be the output of the following command?
perl -ne ‘$s1=”^a.*”; $s2=”.*c\$”; if(/$s1$s2/) { print $_ }’ file3.txt |
Only the string aacc is selected because by combining the two variables having regular expressions we will get a match only if a line of text starts with an a and ends with a c. Figure 5 shows the output of these commands.

It is now time to discuss operator m// and s/// in Perl regular expressions. Now that we have worked with a number of regular expressions, it is very easy to understand the operator m//. It is the match operator of Perl and, by default, the regular expression match objects /PATTERN/ and m/PATTERN/ are the same. Here, PATTERN is a regular expression pattern. If you have any doubt, make a similar modification in the script regex1.pl where the line of code if(/UNIX/) is replaced with if(m/UNIX/) as regex5.pl, and on testing them, you will see that the results are the same. But if you are new to Perl regular expressions it is better you use the operator m// rather than the operator // to avoid confusion.
The other two operators of interest are the binding operators =~ and !~ which are used to bind a string with the regular expression to be matched. Here again, you don’t need to perform an explicit binding if you are processing the current line being read by Perl denoted by $_. So there is no difference between the lines of code if($_ =~ m/UNIX/) and if(m/UNIX/). You can test the scripts regex1.pl and the modified script regex6.pl to see that the two give the same output. So it should be clear that the lines of code if($_ =~ m/UNIX/), if(m/UNIX/), if($_ =~ /UNIX/) and if(/UNIX/) are all the same.
The real use of binding operators occurs when you want to match a regular expression with a string other than the current line being read by Perl. For example, the command:
1 | perl -e ‘$str= “Hello World”; if($str =~ /Hello/) {print “Match found\n”}’ |
… using the binding operator, results in a match and prints the message: ‘Match found’. Similarly, the command:
perl -e ‘$str= “Hello World”; if($str !~ /abc/) {print “No match found\n”}’ |
…results in no match being found, and the message ‘No match found’ is printed.
Regular expressions in programming languages often surpass the theoretical limits of actual regular expressions. The operator s/// used for substituting a matched string with another string is one such example. The general syntax is s/PATTERN/REPLACEMENT/ where PATTERN is a regular expression pattern to be matched and REPLACEMENT is the string to be swapped with the matched pattern. For example, consider the Perl one-liner:
echo “abc pqr abc” | perl -e ‘$str = <> ; $str =~ s/abc/xyz/; print “$str”’ |
This will output the message xyz pqr abc on the screen. Now let us analyse the command. The output of the echo command is read to the Perl script through STDIN <> and assigned to the variable $str. Then the regular expression substitute object s/abc/pqr/ substitutes the first occurrence of the word abc with pqr in the variable $str, and finally the content of the variable $str is printed on the screen. Modifiers like i and m are used with both the operators m// and s///, whereas certain other modifiers are applicable only to the operator s///. An example of such a modifier is g, which results in a global replacement of matched strings, where all the matched strings are replaced with the replacement pattern rather than the first occurrence.
For example:
echo “abc pqr abc” | perl -e ‘$str = <> ; $str =~ s/abc/xyz/g; print $str’ |
…will print the message xyz pqr xyz on the screen. Another example is the modifier r, which returns the modified string and the original string is left unchanged.
In the example:
echo “abc pqr abc” | perl -e ‘$str = <> ; $str =~ s/abc/xyz/r; print “$str”’ |
…will print abc pqr abc because the original string in the variable $str is unchanged, whereas the command:
echo “abc pqr abc” | perl -e ‘$str = <> ; print $str =~ s/abc/xyz/r’ |
…will print the string xyz pqr abc on the screen because that is the value returned by the operator s///. It is also possible to combine multiple modifiers like g and r. With that in mind, what will be the output of the following command?
echo “abc pqr abc” | perl -e ‘$str = <> ; print $str =~ s/abc/xyz/gr’ |
Is there any difference between the combinations rg and gr? Try out these commands and you will get the answers. tr/// is a similar operator in Perl, which is used for transliterating one set of characters to another set. This operator doesn’t use regular expressions and, hence, we are not going to discuss the tr/// operator.
Now it is time for us to develop a few practical regular expressions. Assume you have a text file full of integers and real numbers. Your task is to identify all the integers. Reading data from a text file and identifying its format is very difficult in languages like C where the use of regular expressions is still not widely supported. But you can do it with a single line of code in Perl. To test our Perl one-liner, let us consider a text file file4.txt with the following data.
-1112.23+222.333-4.400005550001+6.688877 |
Now, execute the following command to analyse the text file:
perl -ne ‘if(/(^[+-]?\d+$)/) {print “$1 : Integer\n”}’ file4.txt. |
All the integers are correctly identified by this regular expression. But a side effect of the definition of this regular expression is that even numbers like 0000, 0001, etc, will be identified as integers. The regex ^[+-]? uses the metacharacter caret ^ to force a match at the beginning and the metacharacter ? makes the occurrence of a regular expression optional. So the occurrence of a + or – symbol at the beginning is optional. The metasymbol \d, which denotes a decimal digit, is used along with the metacharacter + to denote one or more repetitions of decimal digits as \d+. The dollar symbol $ makes sure that the string should end with a decimal digit. Now let us execute the following Perl one-liner on the same text file:
perl -ne ‘if(/(^[+-]?\d+\.\d+$)/) {print “$1 : Real Number\n”}’ file4.txt. |
This regular expression identifies all the real numbers. The trick is identifying the decimal point at the middle with the regular expression \. The regular expression also makes sure that at least one decimal digit occurs before and after the decimal point. Due to this reason, a real number like .333 will not be detected by this regular expression. Figure 6 shows the output of these regular expressions.

Now it is time for us to encounter the ever-confusing curly bracket metacharacter in regular expressions once again. Curly brackets are used as quantifiers in regular expressions. Consider the regular expression a{3} which requires exactly three a’s for a match. Now execute the Perl one-liner:
perl -e ‘$str = “aaa”; $str =~ /a{3}/ && print “$str\n”’ |
…and the string aaa is printed as expected. What about the command:
perl -e ‘$str = “aaaaaa”; $str =~ /a{3}/ && print “$str\n”’ |
Again, as expected, we are surprised to see the string aaaaaa printed on the screen. In the previous article in this series I have explained the theoretical reasons for this pitfall. I hope the explanation made it clear that regular expressions in theory do not have the ability to count; instead, they just match patterns. By using regular expressions alone it is not possible to count accurately; but, there are certain techniques that can be used to perform certain counting tasks. For example, the regular expression \d{3} will identify all strings containing three or more decimal digits, like 333, 4444, 55555, .333, +222, etc, whereas the regular expression ^\d{3}$ will match only those strings with exactly three decimal digits, like 555, 888, etc.
So with that, we reach the end of our discussion. I believe a whole book is necessary to discuss the intricacies of the Perl programming language, and several books are necessary to cover Perl regular expressions. I truly believe that this is not an overstatement. In fact, you need to practice a lot to become masters of Perl regular expressions but you definitely will be rewarded for your hard work. You will uncover knowledge from pieces of text you thought were absolute junk, using tiny regular expressions and Perl. In the next part in this series we will discuss the regular expression syntax of yet another programming language—maybe a language whose regular expression syntax is slightly different from Python and Perl.











