





























































Increasing the clock frequency of a microprocessor to improve the performance was once considered the best option available to industry. But nowadays, due to heat dissipation and energy consumption issues, processor developers have switched to a new model where microprocessors contain multiple processing units called cores. Most modern computing devices have several cores to meet computing requirements. To get high performance out of these cores, developers need to write applications using parallel computing techniques.
This article demonstrates the use of the Pthreads API to achieve high performance by writing multi-threaded applications.

An introduction to the Pthreads API
The Pthreads API is a standard (IEEE Posix 1.3c) application program interface that could potentially be implemented on many different systems. Pthreads is the standard way multi-threaded support is offered. GNU/Linux implements the Pthreads API by keeping all thread functions and data types in the header file pthread.h. Pthread functions are not included in the standard C library. Instead, they are in libpthread so we need to compile and link our program as shown below:
$ cc -o mythread mythread.c -pthread or $ cc -o mythread mythread.c -lpthread |
Developing a multi-threaded application with the Pthreads API
A multi-threaded application has multiple threads executing in a shared address space. A thread is a lightweight process that executes within the same process. All the threads share code and data segments, but each thread will have its own program counter, machine registers and stack. The global and static variables present in the process are common to all threads. Each thread will do a specific task assigned by the process.
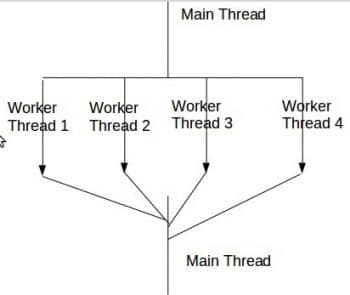
We considered the boss/worker model as shown in Figure 1 for writing the sample application. Here, the idea is to have a single boss thread (main thread) that creates work and several worker threads that process the work. Typically, the boss thread creates a certain number of workers, distributes the work, and then waits for the workers to complete the work. The worker threads form a thread pool as shown in Figure 1. This model works best when the work items/data are independent of each other and when we can schedule each worker thread on a separate core.
To create a thread, we use the pthread_creation function present in the API. We need to call it with four parameters, which are listed below.
Parameter 1: It specifies the address of the variable where we want to store the ID of the newly created thread in the program for future reference.
Parameter 2: It specifies the thread attributes. NULL means default attributes.
Parameter 3: It specifies the address of the function according to which the newly created thread will perform the task.
Parameter 4: It specifies the data which the newly created thread gets from the caller.

Serial (sequential) application performance monitoring
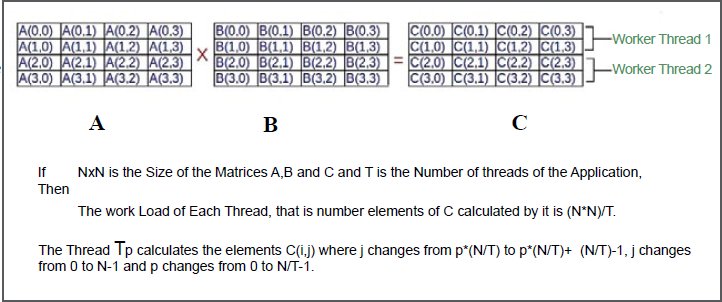
We consider the multiplication of two NxN matrices as the benchmark application. Matrix multiplication can be done in serial fashion as shown below:
// serial program to multiply two nxn matrices -matrix_mul_serial.c#include <stdio.h>#include <stdlib.h>// global space#define n 5120int a[n][n],b[n][n],c[n][n];int main(){int i,j,k;for(i=0;i<n;i++) // Data Initializationfor(j=0;j<n;j++){[i][j]=1;b[i][j]=1;}for(i=0;i<n;i++) // Multiplicationfor(j=0;j<n;j++)for(k=0;k<n;k++)c[i][j]=c[i][j]+a[i][k]*b[k][j];/* printf(\n The resultant matrix is \n);for(i=0;i<n;i++){for(j=0;j<n;j++)printf( %d,c[i][j]);printf(\n);}*/} |
The execution is as follows:
$ cc -o matrix_ser_5120 matrix_mul_serial.c$time ./matrix_ser_5120 |
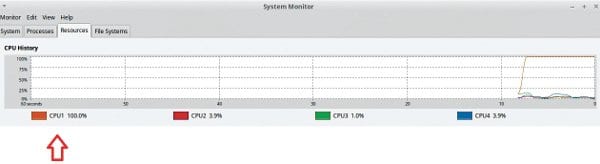
We are executing the applications on a system with Intel CoreTM i5-3450 CPU @3.10 GHz x 4, 4GB RAM running a Linux Mint 17.2 Rafaela 32-bit operating system. We can use the htop command and system monitor to demonstrate the resource utilisation of the application, as shown in Figures 3 and 4. It is very clear that, of the four cores available, the application is running on Core/CPU 1 as it is a serial application with one thread of control. The other cores are under-utilised because of this. With only 27.4 per cent of CPU utilisation, the application failed to take the advantage of its four cores, so the performance of the application is very poor.
Multi-threaded (parallel) application performance monitoring
Matrix multiplication of two NxN matrices can be done in parallel, in many ways. We considered doing it in parallel as shown in Figure 2. If N is 4, then we can create two threads to calculate the C matrix, where Thread 1 computes the elements of the first two rows and Thread 2 computes the elements of the next two rows in parallel. If we create four threads, then each thread computes elements of one row of C in parallel. The design idea is to distribute the work equally among the threads, when N is an exact multiple of the number of threads.
// parallel program to multiply two nxn matrices- matrix_mul_pthreads.c#include <stdio.h>#include <stdlib.h>#define n 5120 // global space#define nthreads 2int a[n][n],b[n][n],c[n][n];void *threadfun(void *arg) // Each Thread Will do this.{int *p=(int *)arg;int i,j,k;for(i=*p;i<(*p+(n/nthreads));i++)for(j=0;j<n;j++)for(k=0;k<n;k++)c[i][j]=c[i][j]+a[i][k]*b[k][j];}int main(){int i,j,k,r,rownos[nthreads];pthread_t tid[nthreads];for(i=0;i<n;i++) // Data Initialization.for(j=0;j<n;j++){a[i][j]=1;b[i][j]=1;}// thread creations using pthreads API.for(i=0;i<nthreads;i++){rownos[i]=i*(n/nthreads);pthread_create(&tid[i],NULL,threadfun,&rownos[i]);}// making main thread to wait until all other threads complete using pthreads API.for(i=0;i<nthreads;i++)pthread_join(tid[i],NULL);/*printf(\n The result of multiplication is :\n);for(i=0;i<n;i++){for(j=0;j<n;j++)printf( %d,c[i][j]);printf(\n);}*/} |
The execution is as follows:
$ cc -o matrix_pthrd_5120_2 matrix_mul_pthreads.c -pthread$time ./matrix_pthrd_5120_2 |
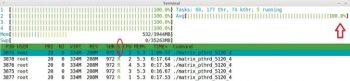
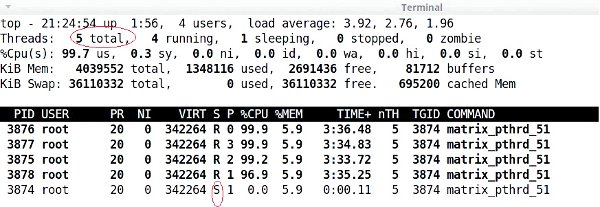
This will create a multi-threaded application with two worker threads and one boss thread. The performance can be monitored by htop as shown in Figure 5. The two worker threads are running in parallel, simultaneously, on Cores 2 and 4, while the main thread (boss) is in a waiting state as shown in Figure 5. The total CPU utilisation is 55.4 per cent. The application performance is better than the serial application. If you replace the statement #define nthreads 2 in the above program with #define nthreads 4 and recompile it, then it generates a multi-threaded application with four worker threads and one boss thread as shown in Figures 6 and 7. The four worker threads are running simultaneously on Cores 1, 2, 3, and 4 respectively, in parallel. It is very clear the CPU utilisation has improved to more than 99 per cent. So the applications performance is very good.
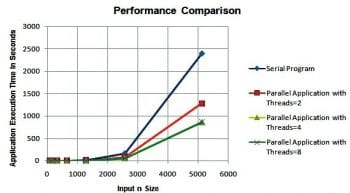
We have executed the serial application and multi-threaded applications by taking n = 80, 160, 320, 640, 1280, 2560, 5120 and nthreads = 2, 4, 8 in the case of multi-threaded applications. A comparison of the results is shown in Figure 8. In terms of execution time, the multi-threaded application clearly outperforms the serial applications performance. So, with the Pthreads API we can develop parallel applications to get a higher performance from the multi-core microprocessor.
References
[1] Advanced Linux Programming, a book by Mitchell, Jeffrey Oldham and Alex Samuel
[2] https://computing.llnl.gov/tutorials/pthreads/












