





























































Discover all that you can do with MongoDB, the popular cross-platform, document-oriented database.
MongoDB is a NoSQL database that uses documents to store data in an organised way. Its document data model presents a great way to work with semi-structured data. A distributed systems design intelligently puts data in different servers and locations, scaling it up dynamically. And it can run from different OSes, eliminating vendor lock-in.
In a data driven world we need to save loads of data. MongoDB does this through replica sets and sharding. Figure 1 shows the MongoDB architecture. Let us explore each component in this architecture, and see what happens in the background when the application server hits the MongoDB server to fetch or feed data.
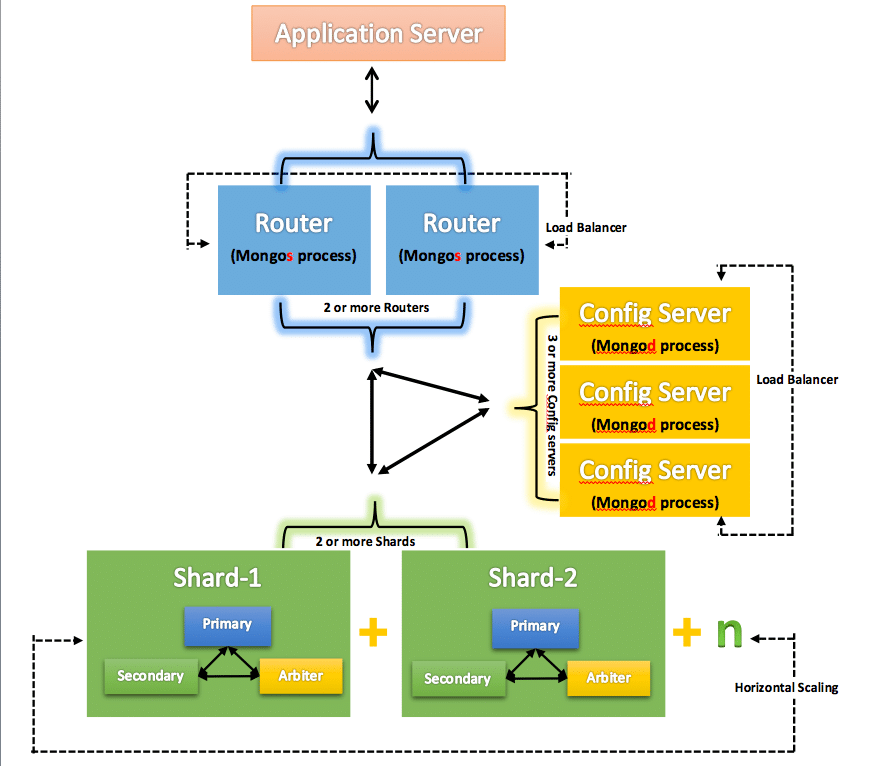
Replica sets
Replica sets in MongoDB provide redundancy and high availability. They comprise a group of mongod processes that maintain the same data set. Replica sets have been designed for high resiliency — if the primary node goes down, a node from the secondary cluster is automatically elected as primary. These sets can hold 50 nodes in total.
The new primary is selected by voting and meeting some conditions such as:
- Most recent updates from the primary data node
- The latest timestamp and heartbeat status
- History of the connectivity status of other secondary nodes
- User-defined priority
Node types: There are three node types: primary, secondary and arbiter.
- Primary node: All the write happens in this node. Only one node acts as the primary node. At times another node may act as primary temporarily, causing the split brain issue. For example, we have six nodes in two data centres, and one node is primary. Due to network issues, connectivity stops between them, causing a network partition. As there is no primary node in one data centre, among the three nodes in it, one is selected as primary. However, having two primary nodes is not recommended. But this is a temporary issue. If the current primary cannot see a majority of voting members, it will step down and become a secondary. Meanwhile only one primary node with { w: “majority” } write concern will be capable of confirming the writes.
- Secondary nodes: All the writes done in the primary node are replicated in all the secondary nodes by applying the oplogs. When the primary node goes down, another one is elected as primary from these secondary nodes.
- Arbiters: Arbiters are mongod instances that are part of a replica set but do not hold data (i.e., do not provide data redundancy). However, they can participate in elections. Arbiters have minimal resource requirements and do not require dedicated hardware.
Consistency levels
- readConcern: The readConcern option allows control of the consistency and isolation properties of the data read from replica sets and replica set shards. The levels are:
- local: The query returns data from the instance with no guarantee that the data has been written to a majority of the replica set members.
- available: This is identical to the ‘local’ in unshared collections. But in a sharded cluster we have orphaned documents. These documents also exist in chunks on other shards because of failed migrations or incomplete migration cleanup due to abnormal shutdown. In ‘local’, the reads require communication with primary shard (if read is on secondary) or the config servers to service the read. Whereas the ‘available’ option does not contact the shard’s primary or the config servers for updated metadata and may return orphan documents.
- majority: This query only returns data that was written to most voting nodes and will not be rolled back.
- linearizable: The query returns data that reflects all successful majority acknowledged writes that completed prior to the start of the read operation. It may wait for concurrently executing writes to propagate to a majority of replica set members before returning results.
- snapshot: Each write is synchronised across the host based on the time. The snapshot option reads from the latest synchronised time from all the nodes.
- Write concern: Write concern describes the level of acknowledgment requested from MongoDB for write operations to a standalone mongod or to replica sets or to sharded clusters. The levels are:
- majority: Requests acknowledgement that write operations have propagated to the primary based on the calculated majority number for the secondary voting members. As an example, if we have a P-S-S replica set, the write should be propagated to primary and one secondary. Similarly, if we have a P-S-A replica set, the write should have been propagated to primary and secondary as well.
- <number>: Requests acknowledgment that the write operation has propagated to the specified number of mongod instances. No acknowledgment for the write operation with ‘w’ is set to 0.
- <custom write concern name>: Requests acknowledgment that the write operations have propagated to tagged members that satisfy the custom write concern defined in settings.getLastErrorModes.
Sharding
This is a method for distributing data across multiple machines. As all the data cannot be saved in a single disk, we need to have horizontal scaling. Sharding is the process of enabling horizontal scaling seamlessly beyond the hardware limits of the single server. Shards are used to store data in distributed systems using the shard key. The shard key determines how data is distributed across a sharded cluster. As we can modify the shard key, MongoDB will automatically rebalance data across shards as needed without manual intervention. As seen in Figure 1, it’s advisable to have a separate replica set for each shard, providing high availability and data consistency.
Chunks are subsets of shared data. MongoDB separates sharded data into chunks that are distributed across the shards in the shared cluster. Each chunk has an inclusive lower and exclusive upper range based on the shard key. A balancer specific for each cluster handles the chunk distribution. Sharding options are:
Ranged sharding: Documents are partitioned across shards according to the shard key value.
Hashed sharding: Documents are distributed according to an MD5 hash of the shard key value, providing even distribution.
Zoned sharding: Allows developers to define specific rules governing data placement in a sharded cluster.
|
Note: Sharding requires careful planning, since the shard key directly impacts the overall performance of the underlying cluster, as it is used to identify all the documents within the collections. |
Config server
Config servers store the cluster’s metadata. This data contains a mapping of the cluster’s dataset to the shards. The metadata includes the list of chunks on every shard and the ranges that define the chunks. The query router (mongos process) uses and caches this metadata to redirect target operations to specific shards. Config servers need to be placed in the replica set to enable consistency and resiliency, which can be up to 50 instances.
To be deployed as a replica set, the config servers must run the WiredTiger storage engine. If the config server replica set loses its primary and cannot elect it, the cluster’s metadata becomes read only. You can still read and write data from the shards, but no chunk migration or chunk splits will occur until the replica set can elect a primary. In a sharded cluster, mongod and mongos instances monitor the replica sets in the sharded cluster (e.g., shard replica set, config server replica set).
Daemon mongod
mongod is the primary daemon process in Linux for the MongoDB system. It handles data requests, manages data access, and performs background management operations. The data is usually stored in /data/db. Also, we cannot have two mongoDB instances running on the same port 27017.
Daemon mongos
The mongos instances provide the interface between the client applications and the sharded cluster. From the config server the mongos instances cache the metadata and use it to route read and write operations to the correct shards. Also called as query router, mongos updates the cache when there are metadata changes for the cluster, such as chunk splits or addition of a shard. A sharded cluster can contain more than one query router to divide the client request load.
MongoDB storage engine
The storage engine is the component of the database that is responsible for managing how data is stored, both in memory and on disk. MongoDB supports multiple storage engines, as different engines perform better for specific workloads. The engine can be selected based on the need of the application. There are three engines.
WiredTiger: The WiredTiger storage engine is the default storage engine starting in MongoDB version 3.2. It provides a document-level concurrency model, allowing multiple users to write on the same collection in different documents at the same time.
Encrypted storage engine: The data is encrypted at rest by using this engine. A decryption key is needed to read the data. This engine is available in the MongoDB Enterprise edition.
In-memory storage engine: All the data, including the configurations, are stored in the memory. This engine provides quicker and low latency by avoiding I/O from disks.
However, data is not persistent.
The MongoDB data storage hierarchy is:
- Clusters
- Database – <Collection of Collections>
- Collections – <Similar to RDBMS Table>
- Document – <JSON single record> <Single Row>
- Key and value pair
- Document – <JSON single record> <Single Row>
- Collections – <Similar to RDBMS Table>
- Database – <Collection of Collections>
Document
A document is a way to organise and store data as a set of field-value pairs. A field is a unique identifier for a datapoint, while value is data related to a given identifier. The documents are viewed in the JSON (JavaScript Standard Object Notation) format.
A JSON object is defined in the following format:
- Starts and ends with curly braces {}
- Separates each key and value with a colon :
- Separates each key:value set with a comma ,
- Keys must be written within double quotes “”
- It is represented based on the data type of value
- Value can be a number, string, objects (sub-document)
However, JSON has a few limitations. As it’s text based, it consumes more space. It supports limited data types and only the UTF-8 format.
Hence, documents are stored in the BSON format. BSON stands for Binary JSON, and addresses the limitations of JSON by storing the data in the binary format. Optimised for better speed, limited space usage and high performance, it supports multiple data types. BSON is faster to parse and lighter to store than JSON. Its drawback is that only machines can read it.
Collections
Documents are stored in collections. There can be many collections per database and many documents per collection.
- Collection:
- Should not connect \0, . and $
- Should not start with a system
- SubCollection:
- Syntactic sugar
- Holds sub-collections
Database
Since MongoDB is a NoSQL database, the data is not saved in rows or columns but in documents as described earlier. Here is the folder structure.
- admin
- Authentication and authorisation
- local
- Database stores data specific to a single server
- Stores the data used in the replication process
- Local itself is never replicated
- config
- Stores information about each shard
Atlas, a MongoDB cloud
Atlas is one of the MongoDB clouds, and creates three replicas.
Replica set: A few connected machines store the same data to ensure that if something happens to one of the machines the data remains intact.
Instance: This a single machine locally or in the cloud, running a certain software. In our case, it is the MongoDB database.
Cluster: A group of servers that store your data.
The MongoDB client is a tool, library, or driver that allows applications to connect to and interact with a MongoDB database. It provides the functionality needed to perform database operations, like connecting to a MongoDB instance, querying documents, updating records, deleting data, and managing collections and databases
Written in JavaScript, Mongo Shell accepts all the JavaScript functions. Here are some example commands:
> help > db.listingsAndReviews.updateOne.help db.collection.updateOne(filter, update, options):
It updates a single document within the collection based on the filter.
> db.listingsAndReviews.updateOne
[Function: updateOne] AsyncFunction {
apiVersions: [ 1, Infinity ],
serverVersions: [ ‘3.2.0’, ‘999.999.999’ ],
returnsPromise: true,
topologies: [ ‘ReplSet’, ‘Sharded’, ‘LoadBalanced’, ‘Standalone’ ],
returnType: { type: ‘unknown’, attributes: {} },
deprecated: false,
platforms: [ 0, 1, 2 ],
isDirectShellCommand: false,
acceptsRawInput: false,
shellCommandCompleter: undefined,
help: [Function (anonymous)] Help
}
You can run script with the shell as follows:
option 1> mongo script1.js script2.js option 2> load(“script1.js”) example> show dbs db.getMongo().getDBs()
MongoDB Compass is an interactive tool for querying, optimising, and analysing the MongoDB data. You can drag and drop it to build pipelines and more.
MongoDB is widely used across various web applications as the primary data store. One of the most popular web development stacks, the MEAN stack, employs MongoDB as the data store (MEAN stands for MongoDB, ExpressJS, AngularJS, and NodeJS). Other languages, such as Python, Java and Ruby, also have client libraries to work with MongoDB.
Importing and exporting data
The commands given below help to get and set the data from or to the MongoDB database.
JSON:
- Import
mongodump --uri “mongodb+srv://<your username>:<your password>@<your cluster>.mongodb.net/sample_supplies” --uri (uniform resource identifier, srv establishes secure connection) srv : connection string - a specific format used to establish a connection between your application and a MongoDB instance.
- Export
mongoexport --uri=”mongodb+srv://<your username>:<your password>@<your cluster>.mongodb.net/sample_supplies” --collection=sales --out=sales.json
BSON:
- Import
mongoimport --uri=”mongodb+srv://<your username>:<your password>@<your cluster>.mongodb.net/sample_supplies” --drop sales.json
- Export
mongorestore --uri “mongodb+srv://<your username>:<your password>@<your cluster>.mongodb.net/sample_supplies” --drop dump
Queries in MongoDB
In MongoDB, queries are commands or instructions used to retrieve data from a MongoDB database. MongoDB queries allow you to specify criteria to filter, sort, project, and aggregate documents within collections, which is critical when working with data.
- findOne -> Will return one document (row) from the collection
- insertOne -> One document will be inserted
- updateOne -> One document will be updated
- deleteOne -> One document will be deleted
- find -> Returned records are not ordered
db.zips.find({“state”: “NY”})
# resuts of it iterates through the cursor.
# cursresultsor: pointer of the result set of query
# pointer: a direct address of the memory location
db.zips.find({“state”: “NY”}).count()
db.zips.find({“state”: “NY”, “city”: “ALBANY”})
db.zips.find({“state”: “NY”, “city”: “ALBANY”}).pretty()
updateOne and updateMany: These take a filter document as their first parameter. The second parameter is a modifier document that describes the changes to make.
replaceOne: These take a filter document as their first parameter, and the second parameter will replace the document matching the filter.
drop: When all collections are dropped from a database, the database no longer appears in the list of databases when you run it.
The preferred methods to avoid race conditions are:
- findOneAndDelete
- findOneAndUpdate
- findOneAndReplace
Aggregation operations process multiple documents and return computed results.
Cursor methods
A cursor is a pointer to the result, from which we can access the data iteratively. For example, when the find() method is used to find the documents present in the given collection, it returns a pointer that points to the documents of the collection. This pointer is known as a cursor. Queries return a database cursor, which lazily returns the batches of documents as needed.
There are a lot of meta operations one can perform on a cursor, including skipping a certain number of results, limiting the number of results returned, and sorting the results.
Indexes
Indexes support the efficient execution of queries in MongoDB. Without indexes, MongoDB must scan every document in a collection to select those documents that match the query statement. If an appropriate index exists for a query, MongoDB can use the index to limit the number of documents it must inspect.
The index is a special data structure, B-Tree, which stores the value of a specific field or a set of fields. The ordering of the index entries supports efficient equality matches and range-based query operations. Using B-Tree indexes significantly reduces the number of comparisons to find the document. The index types are:
Single field: By default, the _id field is indexed. Additionally, any field from the document can be indexed. This increases the performance of the query for the select operations done on the indexed field, such as sort by the field or search by it.
Compound index: This supports queries on multiple fields. The order of the indexed fields has a strong impact on the effectiveness of a particular index for a given query.
Multikey index: Multikey index is used to index for the content stored in an array. It creates separate index entries for each value in the array.
Geospatial index: This is the index on the geospatial data. It comprises two special indexes — 2d indexes that use planar geometry when returning results and 2dsphere indexes that use spherical geometry to return results.
Text index: Text index supports queries on the string content in a collection. We can have more than one string field for creating this index. The weight of an indexed field denotes the significance of the field relative to the other indexed fields in terms of the text search score. For example, in the code given below three fields are used to create the index, each with its own weights:
db.blog.createIndex(
{
content: “text”,
keywords: “text”,
about: “text”
},
{
weights: {
content: 10,
keywords: 5
},
name: “TextIndex”
}
)
For each indexed field in the document, MongoDB multiplies the number of matches by the weight and sums the results. Using this sum, MongoDB calculates the score for the document.
Why you should use MongoDB
MongoDB offers flexibility in the data model and has quicker releases. It is easy to install and offers data scalability. A distributed system and cloud computing deliver data resiliency. MongoDB supports various data types with ease, such as time series, geospatial, polymorphic data, etc. It can help create rich, data-driven applications, and has balanced high performance reads (indexes) and writes. As data grows, sharding helps by horizontally scaling and saving data across multiple instances. It’s cost-effective since it has an open source version.
The challenges
As MongoDB is distributed in nature, transactions are a challenge. However, starting from MongoDB 4.2, distributed transactions can be used across multiple operations, collections, databases, and documents. Joins are not customary; there is a stage called $lookup for joins that comes with high memory cost. Document data size is limited to 16MB, and a limited number of levels are available in nesting.
However, as MongoDB is still evolving, enough work is being done to address all these limitations.














