

























































Containers offer numerous benefits when deployed for generative AI applications, including portability, scalability, and reliability.
Generative AI is revolutionising various industries by enabling the creation of new content, from text and images to music and code. However, deploying generative AI applications can be complex due to the need for scalable, reliable, and efficient infrastructure. This is where containers, Kubernetes, and Docker come into play. These open source technologies provide a robust framework for deploying and managing generative AI applications, ensuring they run smoothly and efficiently.
Typical enterprise generative AI applications consist of multiple layers (Figure 1).
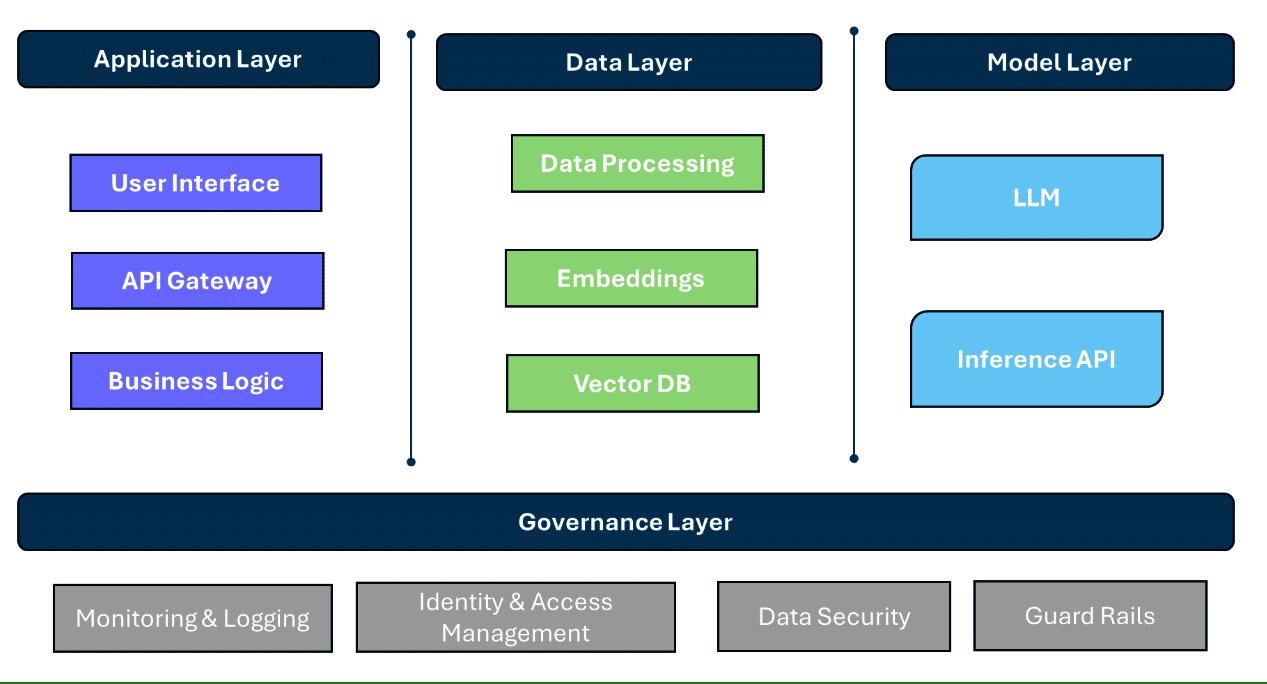
Application layer: This layer encompasses the user-facing components of the generative application. It includes:
- User interface: Web or mobile interfaces through which users interact with the application. For small-scale applications and proof-of-concept use cases, open source frameworks such as Streamlit and Gradio are used widely. For production deployments, web frontends are being used.
- API gateway: This is a web frontend interfaced with a backend API. Python FastAPI is a popular choice.
- Business logic: Application-specific logic integrates model predictions with other functionalities. Open source frameworks such as LangChain and LangFlow are widely used to isolate component interactions. They help to create plug-and-play models, eliminating entire code rewrites.
Data layer: AI/ML applications include data processing pipelines for data preparation such as unnecessary noise/data removal, filtering personally identifiable information (PII), and pre-processing such as tokenization. Popular open source vector databases are FAISS (Facebook AI Similarity Search) and Chroma. Enterprises are leveraging graph databases such as Neo4J for knowledge graphs.
Model layer: This layer takes care of model development, training, deployment and serving. As model training is an expensive task, teams are leveraging commercial models offered by major cloud providers such as Azure, OpenAI, AWS, and Google AI/ML LLM models. Open source frameworks such as Ollama are available for local deployment. HuggingFace offers model deployment services.
Governance layer: This layer includes enterprise essentials such as controlled and secured access, data protection, logging and monitoring. Guardrails and other features help comply with enterprise AI policies.
The role of containers in AI deployment
Many of these layers are isolated modules. GenAI application plugs them together to form a cohesive solution. We can leverage containerisation technology to effectively deploy and manage GenAI solutions.
Containers are compact, portable units that bundle an application along with its dependencies, ensuring uniformity across diverse environments. Docker is a well-known containerisation platform that eases the process of creating, deploying, and managing containers. While Docker is adept at handling individual containers, Kubernetes is an orchestration tool designed to manage containerised applications at a larger scale.
For generative AI applications, containers offer several benefits.
Isolation: Containers isolate the application from the host system, preventing conflicts between dependencies and ensuring a consistent runtime environment.
Portability and consistency: Containers can run on any system that supports containerisation, making it easy to move applications between development, testing, and production environments. They provide a consistent environment across different stages of the development lifecycle. By containerising AI/ML applications, developers can ensure that the code runs identically in development, testing, and production environments. This portability simplifies collaboration among teams and reduces the “it works on my machine” syndrome.
Scalability and resource management: GenAI and machine learning workloads can be highly variable, requiring extensive computational resources for training models. Containers excel in scaling up or down to meet the demands of the application, ensuring optimal performance. This dynamic scaling is particularly beneficial for handling large datasets and complex models typical in AI/ML applications.
Automated deployment and updates: Continuous integration and continuous deployment (CI/CD) pipelines are integral to modern AI/ML workflows. Kubernetes supports automated deployments and rollbacks, enabling teams to iterate quickly and deploy new models without downtime. This automation enhances the reliability and robustness of AI/ML services.
Resource optimisation: Kubernetes efficiently manages computational resources, allocating CPU, memory, and GPU resources as needed. For AI/ML applications that often require significant GPU resources, Kubernetes can schedule and optimise the use of available GPUs, ensuring that expensive hardware is utilised effectively.
Load balancing: Kubernetes automatically distributes network traffic across containers, ensuring high availability and reliability.
Self-healing: Kubernetes can automatically restart failed containers, replace unresponsive nodes, and reschedule containers to maintain the desired state of the application.
Data management: AI/ML applications are data-intensive, and managing data storage and access is crucial. Kubernetes supports various storage solutions, from local storage to cloud-based options, allowing seamless integration with data lakes and databases. Persistent storage in Kubernetes ensures that data remains available across pod restarts and crashes.
Security and compliance: Kubernetes offers robust security features, including role-based access control (RBAC), network policies, and secrets management. These features help teams enforce security best practices and comply with regulations, which is particularly important in industries like healthcare and finance where AI/ML applications handle sensitive data.
Common container patterns for AI/ML deployment
Microservices architecture: Many AI/ML applications are composed of various components, such as data preprocessing, model training, and inference services. Kubernetes supports a microservices architecture by enabling each component to run in its own container and communicate with others via APIs. This approach boosts scalability and maintainability.
Job scheduling: Training AI/ML models can be time consuming and resource-intensive. Kubernetes jobs and cron jobs allow teams to schedule and manage these training tasks efficiently. Teams can define jobs that run once or on a schedule, ensuring that training processes can be automated and monitored.
Model serving: Once trained, AI/ML models need to be served for inference. Kubernetes supports scalable model serving through tools like TensorFlow Serving, KFServing, and Seldon Core. These tools integrate seamlessly with Kubernetes, providing high-performance and scalable inference services.
Data pipelines: Kubernetes enables the orchestration of end-to-end data pipelines, from data ingestion to preprocessing, training, and deployment. Tools like Kubeflow and Apache Airflow, which run on Kubernetes, provide robust platforms for managing these complex workflows.
Deploying generative AI applications with Docker and Kubernetes
To deploy a generative AI application using Docker and Kubernetes, follow these steps.
Containerise the application: Use Docker to create a container image of your generative AI application. This involves writing a Dockerfile that specifies the application’s dependencies and configuration.
Push the image to a registry: Push the Docker image to a container registry, such as Docker Hub or a private registry, making it accessible to Kubernetes.
Create Kubernetes manifests: Write Kubernetes manifests (YAML files) that define the desired state of your application, including deployments, services, and configurations.
Deploy to Kubernetes: Use kubectl commands to deploy the application to a Kubernetes cluster. Kubernetes will handle the orchestration, ensuring the application runs as specified.
Monitor and scale: Use Kubernetes’ monitoring and scaling features to ensure the application performs optimally. Adjust the number of replicas and resources as needed to meet demand.
By leveraging the right tools and frameworks, developers can create scalable, efficient, and secure generative applications that deliver significant value across various domains. Developers can use containers, Docker and Kubernetes to streamline the deployment process, reduce operational complexity, and ensure their applications run efficiently in any environment.
Disclaimer: The views expressed in this article are that of the author and Wipro does not subscribe to the substance, veracity or truthfulness of the said opinion.











