




























































Kubernetes provides a robust platform for deploying and managing large language models, enabling the development of reliable, scalable, highly available, portable and secure applications. There are many benefits of deploying large language models on Kubernetes, and a few challenges too.
Large language models (LLMs) are generative AI models that use deep learning techniques for a wide range of applications like chatbots, content generation, and language translation. LLMs perform natural language processing (NLP) tasks like language translation, text classification, sentiment analysis, text generation, and question-answering.
LLMs are trained with a huge number of datasets from various sources. Some of the most successful LLMs have hundreds of billions of parameters, and could fundamentally transform how we handle and interact with data, including master data.
Some well-known language models are: Gemini from Google, OpenAI’s GPT-4, Claude 3 from Anthropic, Bloom developed by a large team of researchers and engineers from academia and the private sector, with support from the French public supercomputer Jean Zay; and XLNet from Google with a whopping 175 billion parameters.
What is Kubernetes?
Kubernetes is an open source platform designed to automate the deployment, scaling, and management of containerised applications. It provides tools for deploying applications, scaling them as needed, managing changes to existing deployments, and monitoring the health of the system. Its key features are:
Container orchestration: Manages the lifecycle of containers, including deployment, scaling, and updates.
Automated rollouts and rollbacks: Ensures smooth updates and quick recovery from failures.
Load balancing: Distributes network traffic to ensure stability and reliability.
Self-healing: Detects and replaces failed containers automatically.
Auto scaling: Provides elasticity and auto scaling. Easily scales applications up or down based on demand.
Resource management: Sets resource quotas to keep resources in check.
The latest version of Kubernetes is v1.31.1, released on September 11, 2024. It incorporates new features to enhance the platform’s dependability, scalability, and user-friendliness.
Industry adoption of LLMs
According to Brainy Insights, the generative AI-based LLMs market is poised for remarkable growth, with estimations pointing towards a staggering valuation of US$ 188.62 billion by 2032. A Forbes report states that one of today’s leading LLMs was trained on 1.4 trillion tokens.
As per Gartner, by 2026, generative design AI will automate 60% of the design effort for new websites and mobile apps. And by 2027, nearly 15% of new applications will be automatically generated by AI without a human in the loop. This is not happening at all today.
According to Accenture’s 2023 Technology Vision report, 97% of global executives agree that foundation models will enable connections across data types, revolutionising where and how AI is used.
Role of Kubernetes in deploying LLMs
Kubernetes is becoming increasingly popular for deploying LLMs due to its ability to handle resource-intensive applications. It allows the allocation of necessary CPU and memory resources for LLMs to run efficiently. Also, many LLMs require GPUs for processing large parameters efficiently. Kubernetes helps to distribute workloads across multiple GPUs to achieve optimal performance.
Kubernetes supports both horizontal and vertical scaling required for LLMs to handle varying workloads to ensure optimal resource utilisation and performance. Horizontal scaling adjusts the number of pods based on demand, while vertical scaling adjusts the resources allocated to each pod.
Kubernetes automates deployment, scaling, and management of LLMs, reducing the complexity of managing models. This includes automated rollouts, rollbacks, and self-healing capabilities, which are crucial for maintaining the reliability of LLMs in production. It supports cloud native architectures that allow seamless integration with cloud services and supports containerised applications for deploying LLMs.
Kubernetes allows portability — LLMs can be easily moved between different environments such as cloud platforms and on-premises data centres with minimum reconfiguration. And it easily integrates with AI/ML tools like LangChain and Hugging Face to deploy multiple LLMs on Kubernetes.
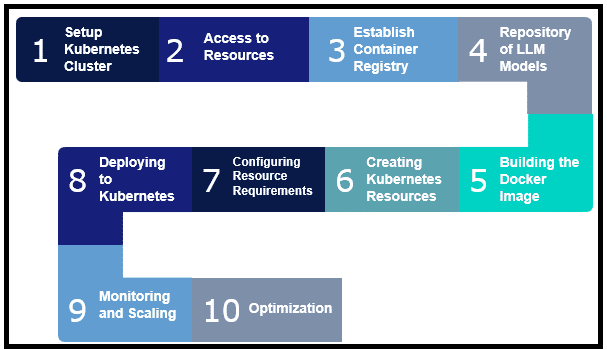
Steps for deploying LLMs on Kubernetes
Several key steps must be followed to ensure efficient and scalable management of LLMs on Kubernetes.
Set up Kubernetes cluster: The first step is to set up the Kubernetes cluster and run it either on-premises or on cloud platforms like Amazon Elastic Kubernetes Services (EKS), Google Kubernetes Engine (GKE) and Azure Kubernetes Services (AKS).
Access to resources: Ensure the Kubernetes cluster has access to GPU resources either through physical GPUs or cloud based GPU instances.
Establish container registry: Set up container registry to store LLM Docker images. Examples of container registry are Docker Hub, Amazon Elastic Container Registry (ECR), Google Container Registry (GCR) and Azure Container Registry (ACR).
Repository of LLM models: Prepare a summary of pretrained LLM model files from different sources or train the required models. Containerise LLM applications using Docker or container runtime.
Building the Docker image: Create Dockerfile that specifies the environment and dependencies required for LLM. Use Docker to build the image from the Docker file. Push the built image to a container registry.
Creating Kubernetes resources: Define Kubernetes deployments to manage the pods running LLM. Set up Services to expose LLM pods to other parts of the cluster or external clients. Use ConfigMaps for configuration data and Secrets for sensitive information like API keys.
Configuring resource requirements: This is the critical step in deployment. The following resources need to be configured appropriately, such that the Kubernetes cluster runs efficiently and provides optimised performance.
- Requests: Specify the minimum resources required for LLM application. Kubernetes guarantees these resources.
- Limits: Set the maximum resources an LLM application can use. This prevents a single pod from consuming all the resources.
- Implement horizontal pod autoscaling to automatically scale the number of pods based on CPU or memory usage.
- Implement vertical pod autoscaling to adjust the CPU and memory requests for running pods based on actual usage
- Resource quotas: Set resource quotas to limit the overall resource usage in a namespace, ensuring fair resource allocation.
- Node selectors and affinity: Assign pods to specific nodes based on labels. Define rules for how pods should be placed on nodes, considering factors like co-location and anti-affinity.
- Persistent storage: Use persistent volumes (PV) and persistent volume claims (PVC) to manage storage needs.
Deploying to Kubernetes: Use kubectl to apply the Kubernetes configuration files and deploy LLM. Monitor the deployment process to ensure everything is running smoothly.
- Implement network policies to secure LLM deployment.
- Isolate different parts of the Kubernetes cluster, ensuring that only authorised traffic can flow between pods.
- Encrypt all data transmitted between the LLM and other systems using protocols like TLS.
- Set Kubernetes RBAC (role-based access control), which ensures that only authorised personnel can access specific resources and perform certain actions.
Monitoring and scaling: Use monitoring tools like Prometheus and Grafana to keep track of resource usage and performance metrics. As part of monitoring:
- Adjust the number of pods and resources as needed based on the monitoring data to handle varying workloads.
- Set up backup and recovery processes to protect data and ensure quick recovery in case of failures.
- Regularly review access logs to detect any unusual or unauthorised activity.
Optimisation: Continuously optimise resource allocation and performance to ensure efficient operation of LLMs.
Example of LLM deployment
The following code snippets briefly explain how to deploy the GPT-4 language model on Kubernetes using a pre-built Docker image from Hugging Face.
Create a Docker image containing the GPT-4 model using Hugging Face’s Docker file:
FROM huggingface/huggingface-transformers:latestCOPY requirements.txt /app/RUN pip install -r /app/requirements.txtCOPY . /app/WORKDIR /appCMD [“python”, “app.py”]```[_{{{CITATION{{{_2{How to deploy Hugging Face models with gopal:ai] (https://www.gopal.ai/blog/how-to-deploy-hugging-face-models-with-gopal-ai)cker images. |
Build the Docker image using the Docker image command:
Shdocker build -t my-gpt4-model .```[_{{{CITATION{{{_3{How to deploy Hugging Face models with gopal:ai] (https://www.gopal.ai/blog/how-to-deploy-hugging-face-models-with-gopal-ai) |
Next, push the Docker image to a container registry like Docker Hub or Google Container Registry:
Shdocker tag my-gpt4-model <beharaLLM-registry>/<beharaLLM-image>docker push <beharaLLM-registry>/<beharaLLM-image>```[_{{{CITATION{{{_4{Deploying ViT on Kubernetes with TF Serving - Hugging Face](https://huggingface.co/blog/deploy-tfserving-kubernetes) |
Now, create a Kubernetes deployment YAML file to deploy the Docker image:
YamlapiVersion: apps/v1kind: Deploymentmetadata:name: gpt-4-deploymentspec:replicas: 1selector:matchLabels:app: gpt-4template:metadata:labels:app: gpt-4spec:containers:- name: gpt-4image: <beharaLLM-registry>/<beharaLLM-image>ports:- containerPort: 5000```[_{{{CITATION{{{_5{Deploying Large Language Models on Kubernetes: A ... - behara.AI](https://www.behara.ai/deploying-large-language-models-on-kubernetes/) |
Next, create a Kubernetes service to expose the deployment:
YamlapiVersion: v1kind: Servicemetadata:name: gpt-4-servicespec:selector:app: gpt-4ports:- protocol: TCPport: 80targetPort: 5000type: LoadBalancer```[_{{{CITATION{{{_6{Deploying Large Language Models on Kubernetes: A ... - behara.AI] (https://www.behara.ai/deploying-large-language-models-on-kubernetes/) |
Apply the deployment and service YAML files to the Kubernetes cluster as follows:
Yamlkubectl apply -f deployment.yamlkubectl apply -f service.yaml```[_{{{CITATION{{{_7{Deploying Large Language Models on Kubernetes: A ... - behara.AI](https://www.behara.ai/deploying-large-language-models-on-kubernetes/) |
Industry usage of LLM on Kubernetes
Industries are increasingly leveraging LLMs on Kubernetes for various applications. Here are a few examples.
Healthcare: Hospitals and healthcare providers use LLMs for tasks like medical record analysis, patient support, and diagnostic assistance. Kubernetes helps manage the computational demands of these models, ensuring efficient and scalable deployment.
Customer service: Businesses deploy LLMs to power chatbots and virtual assistants, providing real-time customer support and improving response times. Kubernetes ensures these applications can handle high volumes of requests and scale as needed.
Financial services: Financial institutions use LLMs for fraud detection, risk assessment, and customer service. Kubernetes provides the infrastructure to deploy these models securely and manage resources effectively.
E-commerce: E-commerce companies leverage LLMs for personalised recommendations, customer review analysis, and chatbot support. Kubernetes helps manage the deployment and scaling of these models, ensuring a seamless user experience.
Media and entertainment: Media companies use LLMs for content generation, scriptwriting, and audience analysis. Kubernetes supports the deployment of these models, allowing for efficient resource management and scalability.
Education: Educational institutions deploy LLMs for personalised tutoring, content creation, and administrative support. Kubernetes provides the necessary infrastructure to manage these applications effectively.
Research and development: Research organisations use LLMs for data analysis, natural language processing, and simulation. Kubernetes helps manage the computational resources required for these tasks, ensuring efficient and reliable operation.
Table 1: A comparison between deploying LLM on Kubernetes and in business applications
| LLM on Kubernetes | LLM in business applications | |
| Scalability | High scalability with Kubernetes, allowing easy scaling up or down based on demand. | Scalability depends on the infrastructure and resources available within the business environment. |
| Resource
management |
Efficient resource management with Kubernetes, isolating resources for optimal performance. | Resource management may vary, depending on the business’s IT infrastructure and capacity |
| Deployment
complexity |
Complex set up and configuration required for Kubernetes. | Deployment can be simpler, depending on the
existing infrastructure and tools. |
| Cost efficiency | Can be cost-efficient due to optimised resource usage and reduced manual intervention. | Costs can vary based on the scale of deployment and the need for additional infrastructure. |
| Security | Enhanced security with Kubernetes’
network policies and access control. |
Security measures depend on the business’s cybersecurity practices and protocols. |
| Flexibility | High flexibility with various Kubernetes environments. | Flexibility depends on the business’s specific needs and existing systems. |
| Maintenance | Requires ongoing maintenance and monitoring. | Maintenance depends on the business’s IT support and resources. |
| Use cases | Suitable for large-scale applications
requiring high availability and resilience. |
Suitable for various business applications, including customer support, data analysis, and more. |
Challenges in deploying LLMs on Kubernetes
Resource intensive: LLMs require significant computational resources, including high CPU and GPU usage. Ensuring enough resources to handle these demands with a Kubernetes cluster is a challenge.
Complex configuration: Setting up Kubernetes for LLMs involves complex configurations that cover the definition of resource requests and limits, setting up auto scaling, and managing network policies.
Data management: Handling large datasets required for training and inference can be difficult. Efficient data storage, transfer, and management are crucial to ensure smooth operation.
Security concerns: Securing LLMs involves protecting sensitive data and ensuring compliance with regulations like HIPAA or GDPR. Implementing robust security measures, such as encryption and access controls, is essential.
Monitoring and maintenance: Continuous monitoring and maintenance are required to ensure LLMs run efficiently. This includes tracking performance metrics, handling failures, and updating models.
Bias and ethical considerations: LLMs can reflect biases present in the training data, leading to ethical concerns. Ensuring fairness and mitigating biases is a significant challenge.
Integration with existing systems: Integrating LLMs with existing business applications and workflows can be complex, requiring careful planning and execution.
Cost: Deploying and maintaining LLMs on Kubernetes can be costly due to the high resource requirements and the need for specialised hardware.
Hence, careful planning, robust infrastructure, and continuous management are needed to ensure the successful deployment of LLMs on Kubernetes.
The benefits
Deploying large language models on Kubernetes has significant benefits too:
Kubernetes allows to scale LLM deployment up or down based on demand. This helps to handle varying workloads.
Ensures CPU, memory, and storage are used optimally, reducing waste and improving performance.
Automates deployment of LLMs, reducing the manual effort and eliminating the risk of errors.
Automatically replaces failed pods and distributes workloads across multiple nodes, ensuring LLMs are always accessible.
Supports various environments like on-premises, hybrid, or multi-cloud, offering flexibility in deployment and management.
Lowers operational costs making it a cost-effective solution for managing LLMs.
Provides enhanced security features.
As the complexity of LLMs increases due to future requirements, they need to support autoscaling, GPU scheduling, fine-tuning, monitoring, security, and multi-cloud deployments. All of this can be achieved by leveraging Kubernetes.
| Acknowledgements The author would like to thank Santosh Shinde of BTIS, enterprise architecture division of HCL Technologies Ltd, for giving the required time and support in many ways to write this article as part of architecture practice efforts. |
Disclaimer: The views expressed in this article are that of the authors. HCL and Coforge do not subscribe to the substance, veracity or truthfulness of the said opinion.











