




























































Find out the advances Kubernetes has made in orchestration and multi-cluster management as well as how AWS Fargate and Google Cloud Run are simplifying the deployment of containers.
Kubernetes orchestrates or runs, connects, scales, and manages massive, multi-container workloads, just like a symphony conductor, by offering a variety of dynamic services.
Applications and dependencies are packaged into portable components via containers, which are frequently arranged as microservices that perform particular functions. It can be difficult and unscalable to manually manage these containers across several nodes and applications. Significant automation is needed for tasks including setting up ports, starting containers, maintaining storage, handling errors, and distributing updates.
This procedure is made simpler by Kubernetes orchestration, which provides standardised behaviours and application management services. Configurations specify how every part—from the application layers to the infrastructure—should function. Kubernetes keeps a close eye on the system, restarts containers automatically when they fail, and makes sure that programs function properly across nodes while adjusting to changing circumstances. This offers dynamic, multi-container applications scalable, automated management.
Kubernetes is one of several container orchestration tools. Simple orchestration is built into container runtimes like Docker Engine, and managed through tools like Docker Compose. Swarm extends this to clusters, enabling multi-container apps, persistent storage, and fast container replacements.
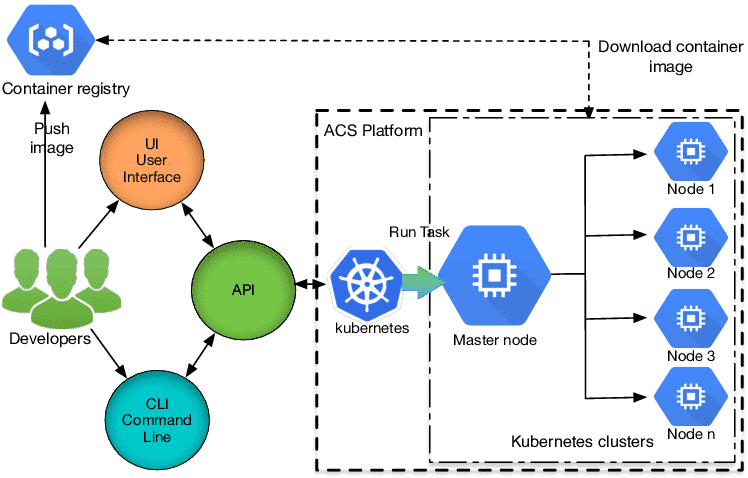
Apache Mesos, predating Kubernetes, also turns container hosts into clusters, abstracting physical resources and providing APIs for apps to manage their own orchestration. Mesos is suited for cluster-oriented apps like Hadoop. Projects like Marathon add additional orchestration layers on top of Mesos, offering a user-friendly environment similar to Kubernetes.
Kubernetes and advanced orchestration: Exploring updates
Kubernetes continues to evolve as a powerful platform for container orchestration, with advancements focusing on better multi-cluster management, improved scheduling techniques, and the rise of serverless containers. Let’s explore these developments.
Service mesh
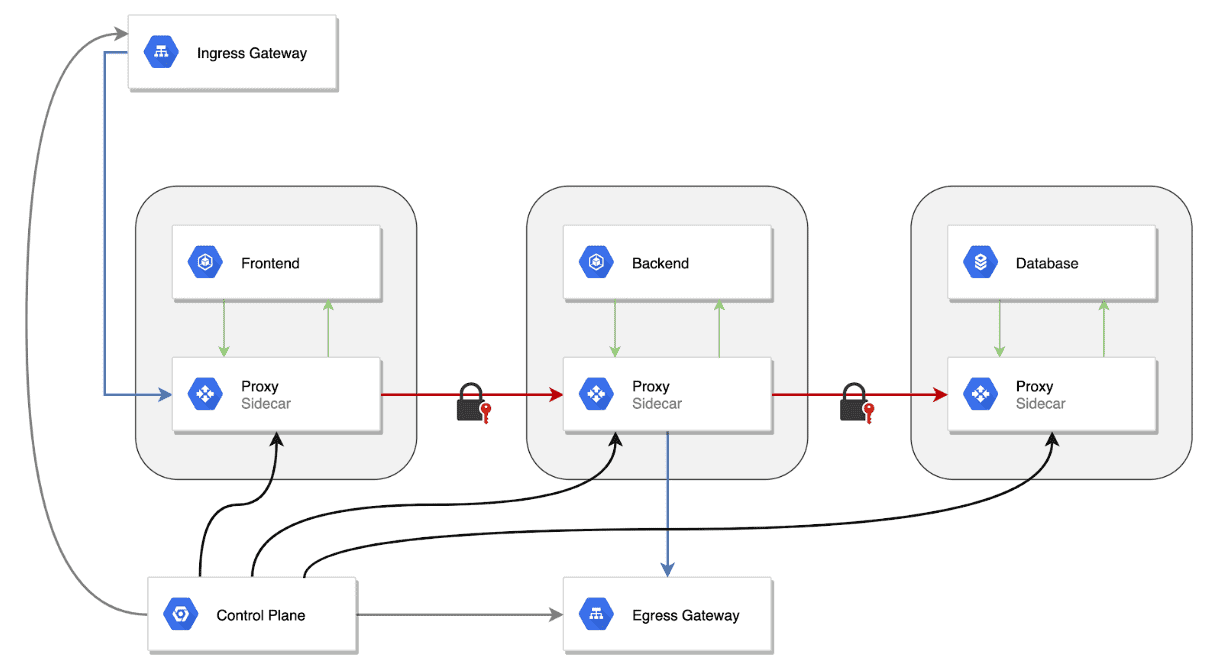
Kubernetes service mesh is a tool that simplifies the management of service-to-service communication within a Kubernetes cluster. It enhances network management, security, and observability by using Layer 7 proxies, which handle tasks such as:
Traffic management: Advanced routing and load balancing between microservices.
Security: Mutual TLS (mTLS) for encrypted communication and access controls.
Observability: Monitoring and tracing for performance insights.
- How it works
The service mesh consists of:
Data plane: Lightweight proxies (sidecars) deployed within each pod, managing traffic and collecting telemetry data.
Control plane: Centralised management for configuring proxies, issuing TLS certificates, and enforcing policies.
This setup abstracts network management from application code, allowing for secure, reliable, and efficient service communication.
- Key features
Traffic management: Supports advanced routing and deployment strategies.
Security: Automates encryption and access control.
Observability: Provides detailed monitoring and tracing.
- Popular tools
Istio: Provides extensive features like Layer 7 load balancing and mTLS. Integrates well with observability tools.
Linkerd: Known for simplicity and performance, it offers essential features like mTLS and basic traffic management.
An example is VMware NSX Advanced Load Balancer, which integrates with Tanzu Service Mesh (TSM) for enhanced security and observability across Kubernetes clusters, connecting modern applications with traditional components.
Multi-cluster management
As Kubernetes enables running containerised apps anywhere, multi-cloud and multi-cluster configurations (MCMCK) are becoming essential. However, managing Kubernetes across various environments is challenging. Let’s explore MCMCK and strategies for mastering it through purpose-built management solutions.
MCMCK refers to Kubernetes deployments spanning multiple public clouds, private data centres, and edge locations. Enterprises adopt multi-cloud to avoid vendor lock-in, optimise costs, ensure disaster recovery, and meet data sovereignty requirements.
Challenges of managing multi-cluster Kubernetes: Managing multiple Kubernetes clusters across diverse environments leads to issues like cluster sprawl, lack of centralised control, networking complexities, and data movement challenges. Dedicated MCMCK platforms help overcome these hurdles by offering unified control, app deployment across clusters, data replication, and seamless communication.
Key use cases for MCMCK: MCMCK enables cost optimisation by deploying apps to the most suitable cloud, avoids vendor lock-in, ensures high availability through cross-cloud replication, and scales infrastructure globally for increased reach and performance.
Leading MCMCK management solutions include:
- Google Anthos: Offers managed Kubernetes across on-prem, Google Cloud, AWS, and Azure with centralised control.
- Red Hat OpenShift: Provides enterprise Kubernetes with multi-cluster management, enhanced security, and GitOps.
- Platform9: Delivers managed Kubernetes as a SaaS solution, offering global cluster management with no infrastructure overhead.
- Rancher: Provides open source multi-cluster management, offering automated provisioning, security, and app deployment.
Key FOSS tools include:
- KubeFed: Federates clusters, enabling cross-cluster resource management.
- Submariner: Enables secure communication between clusters.
- ArgoCD: GitOps-based tool supporting automated multi-cluster deployments.
Mastering MCMCK empowers organisations to optimise costs, enhance high availability, and achieve global scalability. By leveraging purpose-built tools like Google Anthos, OpenShift, and open source solutions, enterprises can effectively manage Kubernetes across multi-cloud environments and unlock the full potential of their infrastructure.
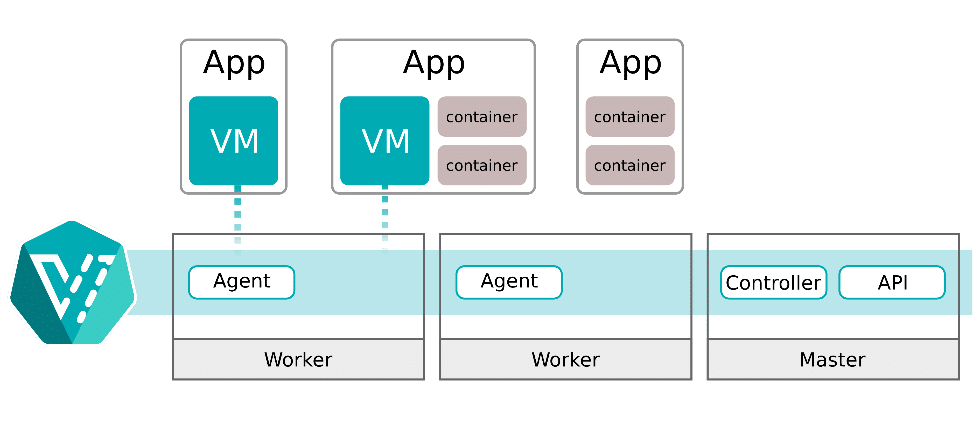
Advanced scheduling techniques
Advanced Kubernetes scheduling has significantly evolved, particularly with the rise of serverless computing. Kubernetes v1.30 offers enhanced capabilities for managing and scaling containerised workloads, making it an ideal platform for complex, production-grade applications.
The Kube scheduler, part of Kubernetes’ control plane, is responsible for placing newly created or unscheduled pods on suitable nodes. It filters available nodes based on specific criteria and scores them to select the most suitable node for the pod. The scheduler then notifies the API server of the decision through a binding process. Users can also develop custom schedulers tailored to unique workload requirements.
Kubernetes now supports advanced scheduling features to optimise resource allocation for modern, demanding workloads:
Node and pod affinity/anti-affinity: Node affinity places workloads based on specific node characteristics, while pod affinity/anti-affinity manages pod placement relative to each other, improving communication or fault tolerance.
Volcano scheduler: Optimised for HPC, machine learning, and batch processing, Volcano efficiently allocates resources for large-scale computational tasks, improving parallel processing and job dependencies.
KubeVirt: This enables hybrid scheduling of both VMs and containers, simplifying management of diverse workloads on a single Kubernetes platform.
These features enhance Kubernetes’ ability to manage both traditional and modern resource-intensive workloads efficiently.
Serverless containers
Kubernetes-native serverless solutions allow developers to deploy containers without worrying about the underlying infrastructure. FOSS solutions like Knative, OpenFaaS, and Kubeless enable serverless workloads on Kubernetes.
Knative: A popular choice for serverless workloads, it auto-scales applications based on demand, including scaling down to zero during idle periods. It integrates natively with Kubernetes and provides event-driven capabilities.
OpenFaaS: Focuses on simplicity and ease of use, allowing developers to deploy both microservices and functions in a serverless manner on Kubernetes.
Kubeless: Lightweight and tightly integrated with Kubernetes, it allows serverless function deployment with full control over Kubernetes resources.
These solutions provide a flexible, cost-efficient serverless architecture by utilising Kubernetes clusters, scaling applications automatically, and eliminating the need for manual infrastructure management.
Serverless platforms: AWS Fargate and Google Cloud Run
Although Kubernetes is popular for managing containers, serverless platforms like AWS Fargate and Google Cloud Run have simplified container deployment by abstracting the infrastructure layer.
AWS Fargate: Fargate works with Amazon ECS and EKS, allowing developers to run containers without managing the underlying servers. It automatically provisions and scales compute resources, making it easier to handle varying workloads without worrying about servers.
- No need to manage EC2 instances.
- Built-in scaling and billing based on resource usage (vCPU and memory).
- Simplifies operational complexity for large container deployments.
Google Cloud Run: This is a fully managed serverless platform for stateless containers, supporting autoscaling based on HTTP traffic. Cloud Run simplifies deployment by running any containerised application without managing the infrastructure.
- Integrates with Google Kubernetes Engine (GKE) for hybrid cloud setups.
- Offers a ‘pay-per-use’ model, ensuring cost-effectiveness for scaling applications based on demand.
- Developers focus purely on code, as Cloud Run handles the infrastructure behind the scenes.
Both platforms abstract server management, making container deployments easier, more efficient, and cost-effective.
How AWS Fargate and Google Cloud Run simplify serverless architecture
Serverless platforms like AWS Fargate and Google Cloud Run play a pivotal role in simplifying container deployment by abstracting much of the underlying infrastructure management, allowing developers to focus more on their applications than on the operational overhead. Here’s how they do so.
- Eliminating infrastructure management
AWS Fargate: Fargate allows developers to run containers without having to provision or manage the underlying servers. It abstracts the complexities of scaling, patching, securing, and maintaining the infrastructure. Users only need to define the container image and the required resources, and Fargate handles everything from launching to auto-scaling the application.
Google Cloud Run: Similar to Fargate, Cloud Run is a fully managed platform that automatically scales stateless containers based on HTTP requests. There’s no need to manage VMs or Kubernetes clusters, as Cloud Run handles the computer infrastructure.
- Auto-scaling based on demand
AWS Fargate: Fargate automatically scales containers up and down based on workload demands. This ensures that users pay only for the compute resources when the containerised applications are actually running, leading to cost efficiency.
Google Cloud Run: Cloud Run dynamically scales the container instances to handle requests, scaling down to zero when no requests are made, ensuring that resources are utilised efficiently without manual intervention.
- Flexible deployment options
AWS Fargate: Fargate can be integrated with both Amazon Elastic Container Service (ECS) and Amazon Elastic Kubernetes Service (EKS), allowing users the flexibility to deploy containers using the orchestration platform of their choice without worrying about the infrastructure.
Google Cloud Run: Cloud Run supports deploying containers directly from Docker images, making it a highly accessible platform for developers who may not want the complexity of Kubernetes but still require fast, scalable container deployment.
- Pay-as-you-go model
AWS Fargate: Users are billed based on the resources consumed by the containers, such as CPU and memory usage, during the time the containers are running. There’s no need to over-provision resources in anticipation of traffic spikes.
Google Cloud Run: Google Cloud Run’s pricing model is also usage-based, billing only for the time containers are actively processing requests. This aligns cost with actual usage, making it economical for sporadic or variable workloads.
- Security and compliance
AWS Fargate: Fargate offers built-in security by isolating applications by design, running each task in its own microVM, ensuring a strong security boundary between running containers. It also integrates with other AWS security services such as IAM, security groups, and encryption, allowing for comprehensive security management.
Google Cloud Run: Cloud Run offers automatic HTTPS by default and integrates with Google’s Cloud IAM for fine-grained access control. The fully managed service includes security updates and patches, so the containers are automatically kept secure without manual intervention.
- Development velocity and simplification
AWS Fargate: Fargate allows developers to avoid managing EC2 instances, enabling faster development cycles. By reducing operational overhead, developers can deploy applications quickly and iterate rapidly.
Google Cloud Run: With Cloud Run, developers can deploy code directly from GitHub repositories or Google’s Container Registry, reducing friction in the continuous integration/continuous deployment (CI/CD) process.
Both AWS Fargate and Google Cloud Run are ideal for developers and organisations looking to simplify container deployment while benefiting from serverless infrastructure. They automate infrastructure management, auto-scale based on demand, offer flexible deployment options, and operate on a cost-effective pay-as-you-go model. These platforms are particularly suitable for microservices architectures, stateless applications, and services with fluctuating workloads, reducing their operational complexity.











