




























































Parallel programming has turned into a necessity with the vast amounts of data that organisations juggle with today. OpenMP is an open source application programming interface that offers a range of advanced features to make the task easier.
The processing needs of organisations have increased exponentially over the last few years, leading to the development of parallel computing to the next level. OpenMP is an open source application programming interface that helps in parallel programming. With the amount of data every business enterprise is receiving and needs to process, parallel computing is more like a necessity. OpenMP can help with that as it supports many platforms and multiple programming languages like C, C++ and Fortran. It provides a scalable and portable model that offers programmers more flexibility and easily understandable code.
Before we understand some advanced features of OpenMP, let us look at a simple program to understand how it works.
You can paste the following code in a text editor:
#include<stdio.h>#include<omp.h>int main(){#pragma omp parallelprintf(“Hello\n”);} |
Here we first import the headers required — omp.h and stdio.h. Now, in the main code, write #pragma omp with the parallel keyword. This will run the code below it in parallel on different threads.
Next, save this text editor with a file name .c. Now open a terminal and type the following commands as shown in Figure 1.

gcc -o helloic -fopenmp hello1.c |
This is to compile the code that we have written.
Next, specify to the OS to what extent we want to parallelise our code, i.e., how many threads we want, by using the following command:
export OMP_NUM_THREADS = 2 |
Once this is done, we can run our compiled code using the following command:
./filenamec |
As you can see in Figure 1, it shows that we printed ‘Hello’ twice, once from each thread! That’s cool, right?
If we have two tasks, both the tasks can run on separate threads parallelly using OpenMP. Even if we have a ‘for’ loop, each iteration of the loop runs on separate threads.
Advanced features of OpenMP
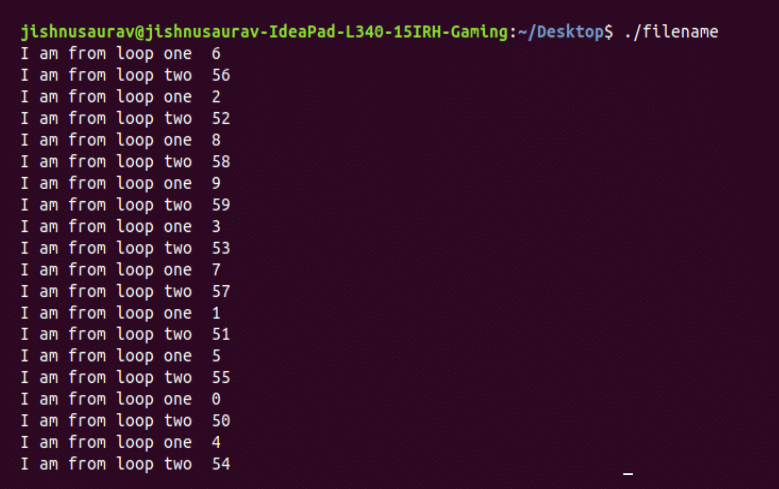
OpenMP has some advanced features for different use cases of parallel programming. The first feature that we are going to discuss here is the ‘nowait’ feature. If we have two commands/‘for’ loops that we want to run parallelly and don’t want that one ‘for’ loop waits for the other to complete, i.e., if we want to run all the iterations of both loops parallelly, this feature is used. You can test this using the following piece of code and the output can be seen in Figure 2.
#include <omp.h>#define _GNU_SOURCE#include<stdio.h>#include <sched.h>int main(){int N; N=10;#pragma omp parallel{#pragma omp for nowaitfor (int i=0; i<N; i++)printf(“I am from loop one %d\n”,i);#pragma omp forfor (int i=0; i<N; i++)printf(“I am from loop two %d\n”,i+50);} } |
As we see in Figure 2, since we have used ‘nowait’, loop 2 does not wait until loop 1 is over.
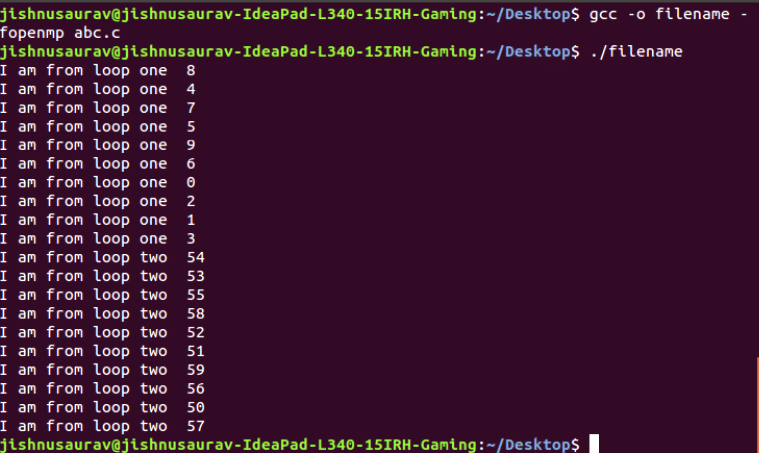
The next interesting feature that OpenMP has is ‘barrier’. Using this feature, we can ask OpenMP to wait for the first loop to complete running parallelly before moving to the next loop. In this the iterations of the first and second loops run parallelly but the loops themselves don’t run parallelly. This is especially useful in situations when we want the output from the first loop to be used in the second. You can test this feature using the following code and the output is shown in Figure 3.
#include <omp.h>#define _GNU_SOURCE#include<stdio.h>#include <sched.h>int main(){int N;N=10;#pragma omp parallel {#pragma omp forfor (int i=0; i<N; i++)printf(“I am from loop one %d\n”,i);#pragma omp barrier#pragma omp forfor (int i=0; i<N; i++)printf(“I am from loop two %d\n”,i+50);} } |
Since we have used ‘barrier’, the second loop waits till the first loop execution is complete.
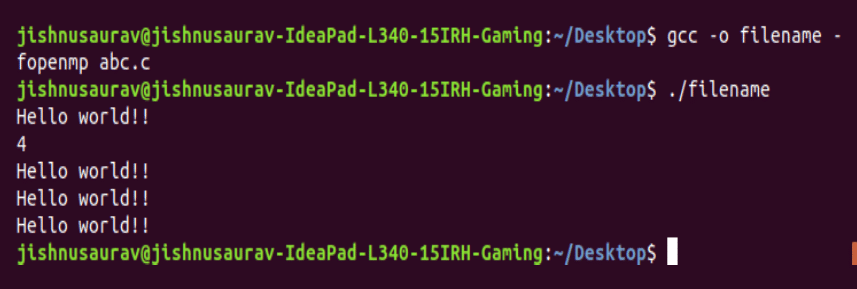
The next feature is the ‘master’. We will see how we can assign a task to the master thread. The master thread is basically the thread that is calling the parallel pieces of code. We can assign specific tasks to this thread — mostly verification tasks. In the following example, we give a generic task to all the threads — the parallel tasks. To the master we will give the task to print the total number of threads that are there. This can be done using the following piece of code and the output can be seen in Figure 4.
#include <omp.h>#define _GNU_SOURCE#include<stdio.h>#include <sched.h>int main(){#pragma omp parallel{printf(“Hello world!!\n”);#pragma omp masterprintf(“%d\n”, omp_get_num_threads());}} |
Here we made the threads print ‘Hello world!!’ and the master thread prints the total threads that are there.
The next feature that we are going to look at is ‘critical’. This feature is useful when we are working with shared variables. Basically, if we need to update a variable more than once in the code and if we run those lines of code parallelly, then there is a chance that the variable gets updated in the wrong sequence. Therefore, the end output may be wrong. Using this ‘critical’ feature, we can ask the second updation command to run only after the first one is complete. Let us look at the code to add x and 1 and update the value of x to x+1. We will look at the outputs using and not using ‘critical’ to understand the difference.
You can run the following code to see the output without using ‘critical’:
#include <omp.h>#define _GNU_SOURCE#include<stdio.h>#include <sched.h>int main(){#pragma omp parallel {printf(“Hello world!!\n”);#pragma omp singleprintf(“%d\n”, omp_get_num_threads());}} |
Here, updates are being carried out simultaneously as we are not using ‘critical’. Hence, the value of x is the same more than once as more than one thread may be updating it at the same time. Had we used ‘critical’, the updations would have been executed one after another.
Now let’s apply the ‘critical’ feature, using the following code:
#include <omp.h>#define _GNU_SOURCE#include<stdio.h>#include <sched.h>int main(){int x;x = 0;#pragma omp parallel shared(x) {#pragma omp criticalx = x + 1;printf(“%d\n”,x); }} |
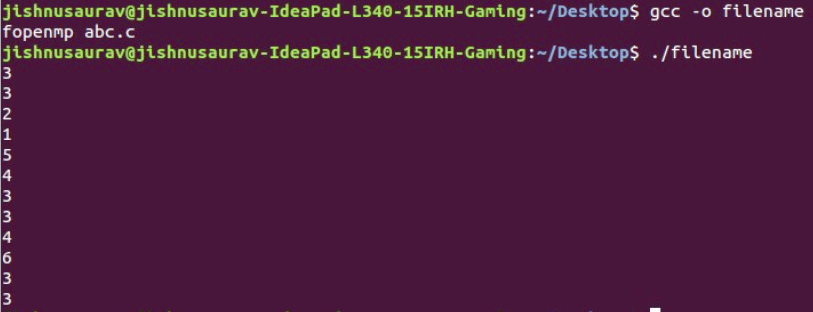
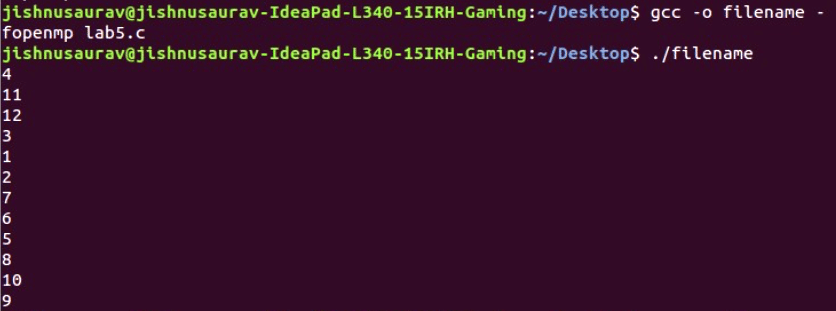
Here we are using ‘critical’, so all the updates of x are being done one after the other. As you can see in Figure 6, each of the values of x is unique.
Another advanced feature of OpenMP is ‘single’. Using this feature, we can assign tasks to the first running thread. You can do this using the following piece of code, as shown in Figure 7.
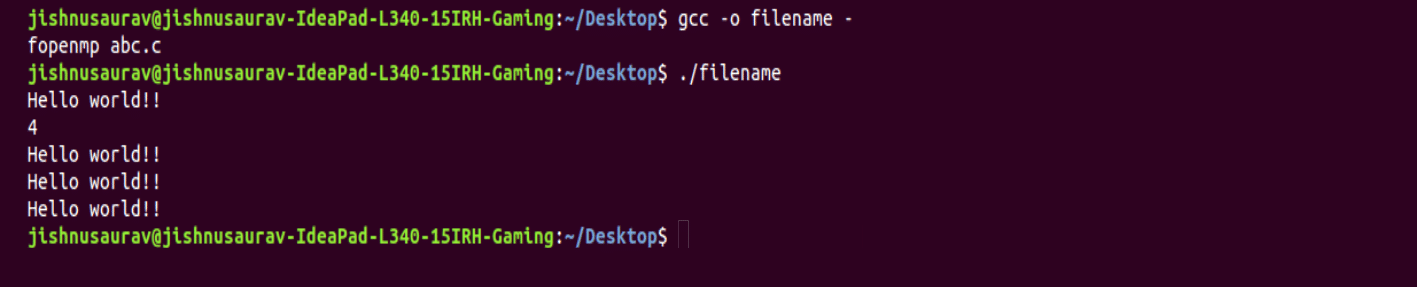
#include <omp.h>#define _GNU_SOURCE#include<stdio.h>#include <sched.h>int main(){#pragma omp parallel {printf(“Hello world!!\n”);#pragma omp singleprintf(“%d\n”, omp_get_num_threads());}} |
We have discussed the important features of OpenMP here. You can take this as the base of your parallel programming journey to explore more in this space. Parallel programming gets more and more interesting as you delve deeper and understand it better.













