




























































Keeping cloud costs optimal is essential for the financial health of any enterprise. However, organisations encounter quite a few challenges when they migrate from on-premises data centres to the cloud using a lift-and-shift strategy. The Google Cloud Platform (GCP) helps to mitigate these challenges and optimise costs.
Organisations of all sizes have started moving to the cloud. There is no longer a question of ‘if’ an enterprise will move to the cloud; it’s only a matter of ‘when’. However, for most enterprises, the journey from on-premises data centres to the cloud is a Herculean task. One unwritten rule is that cloud migration should be seamless and invisible to end users. Additional challenges are a learning curve for the whole organisation, and migration to be completed within a defined timeline to avoid the dual costs of maintaining both on-premises data centres and the cloud infrastructure. Hence, most organisations follow the lift-and-shift approach (of replicating on-premises infra in the cloud) rather than trying to define all the infrastructure newly in the cloud. They also make some pragmatic choices and take decisions that prioritise ‘progress over perfection’.
Every infrastructure element and service usage in the cloud comes with an associated cost. When an enterprise migrates quickly to the cloud, and just tries to replicate on-premises infrastructure, cloud costs shoot higher than expected. Keeping cloud costs optimal is a recurring goal for most organisations, especially in the age of economic uncertainties and challenges. So, cloud migration is usually followed-up with a plan to optimise cloud costs by adopting the cloud-native approach.
In this article, we will look at various strategies that can be adopted to optimise cloud costs in the Google Cloud Platform (GCP).
Cost analysis
If you can’t measure it, you can’t improve it. — Peter Drucker
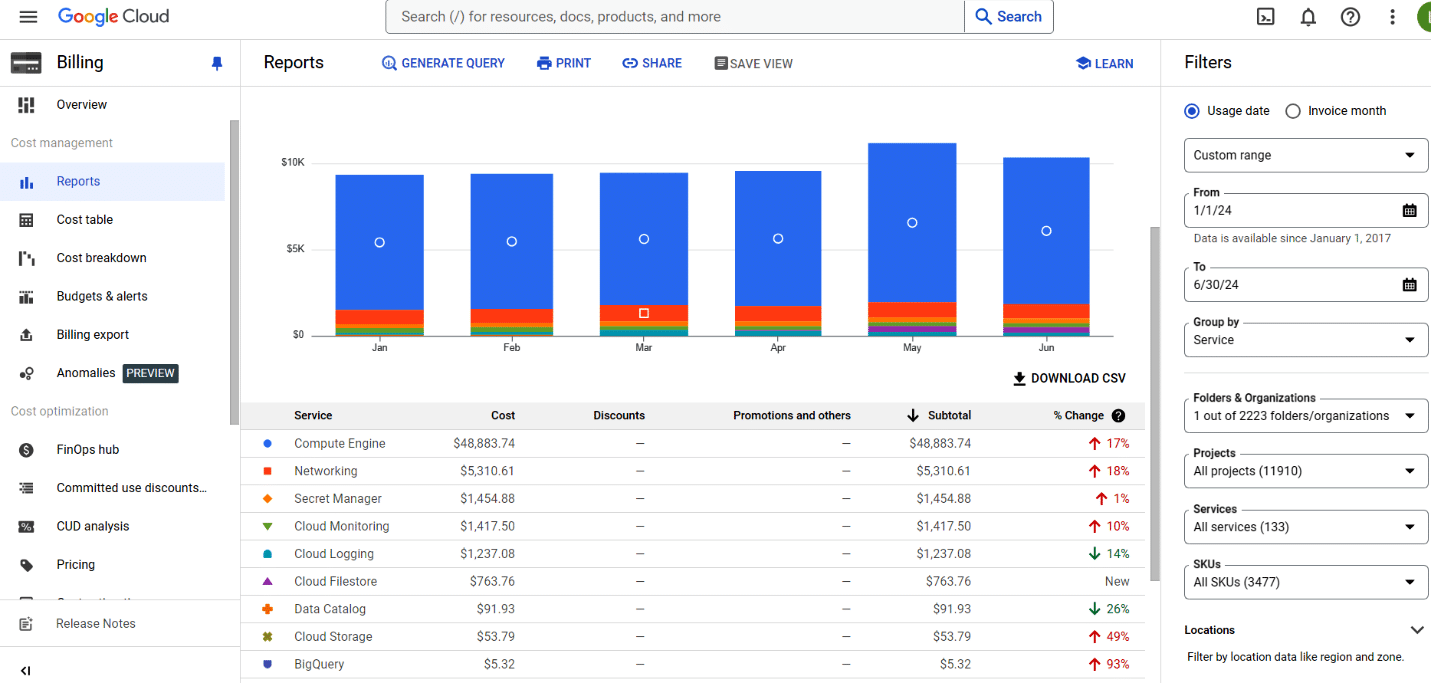
Before we dive into optimisation, it’s essential to analyse the cost drivers. Fortunately, Google Cloud Platform provides a detailed monthly billing report. The ‘Cloud Billing’ feature offers transparent visibility into costs incurred by various cloud services, including compute, storage, network, and more. The ‘Reports’ section in ‘Cloud Billing’ is a good starting point, as it provides various types of reports on the costs incurred by a Google project. It includes ‘Group by’ and ‘Filter’ options to view the costs by service, SKU, etc. By looking at this data, we can quickly identify which service and specific SKU is contributing to the high costs. We can then look at what options are available to optimise costs for that service, picking the top cost contributor to optimise what might give us better ROI in terms of effort versus cost saved.
Optimisation strategies
Once the service(s) contributing to the higher costs are identified, the next step is to look at the options available to optimise costs. The right option will depend on the application and its use case of the service. Also, a typical enterprise deploys multiple environments – development (dev), test, staging, production (prod), etc. Optimisation strategies vary by environment as resource uptime and responsiveness requirements differ across environments. Let us look at some of the widely used GCP services, the factors that influence associated costs, and the options available to optimise costs in different scenarios.
Compute
Compute costs are dependent on the resources (CPU, memory, storage) allocated and the machine type, which plays a significant role. So, choosing the optimal machine type depending on the environment and the application use case becomes crucial.
-
Non-production environments
Machine types: Production environments may need specialised machine types (like compute-optimised) or the latest types (like C4/N4 series) that have the newest processors, providing the best performance. However, these come at a higher cost and are not necessary for other environments. In contrast, non-production environments can utilise more affordable machine types (like E2 series) that provide reasonable performance at a significantly lower cost.
Spot VMs (virtual machines): For applications that are fault-tolerant, we can also consider the option of spot VMs. This option provides preemptible instances which can be up to 91% cheaper compared to regular instances.
Scheduled downtime: If spot VMs are not suitable, another option is to explore the possibility of having a scheduled shutdown of the VMs during unused or non-business hours (e.g., six hours every night or on weekends). Adopt this plan only if the scheduled downtime is applicable and doesn’t impact the teams using this environment.
VM time to live: GCP also provides an option to specify the maximum runtime of a VM, during VM creation. The VM automatically terminates once the specified time limit is reached. This feature is particularly helpful for temporary workload deployments, as the VMs get automatically deleted after a certain time, preventing unnecessary costs due to idle machines.
-
Production environments
Production environment deployments are usually the most cost-intensive as each application requires a significant number of instances to support the large traffic volumes. So, any optimisation effected here will have a significant impact on savings.
Right-sizing: When the lift-and-shift approach is followed, the VM configurations (CPU, memory per instance, number of instances, etc) are replicated from on-premises. However, this is mostly sub-optimal and has a good scope for improvement. If we monitor the resource usage post migration, we will find the instances are mostly underutilised. So, the first step is to right-size your VM instance. Run performance tests and identify the right VM configuration and machine type for the required traffic load. Application characteristics play a crucial role in determining optimal machine type and configuration. Applications that serve API requests to end customers may need high CPU power whereas batch processing applications may need higher memory. Select the appropriate machine type and compute configuration based on your application’s needs.
Instance count: GCP has machine types that offer the latest and fastest processors (like N4) as well as specialised ones (like compute-optimised) that might suit certain applications. Pick the right machine type, arrive at the optimal VM configuration, and identify the load supported per instance. Then derive the number of instances needed to support the production traffic. With this approach, you will see a reduced config per VM and a need for a smaller number of overall instances.
Autoscaling: One more practice is to migrate with a plan of fixed number of instances. For most enterprise applications, the load is not constant and follows patterns. Peak load is seen in business hours and there’s very less load in non-business hours. So, provisioning a fixed number of instances based on peak load will lead to wastage of resources during non-peak hours. To optimise this, we can make use of the autoscaling feature of GCP Managed Instance Groups (MIGs) so that instances can be increased and decreased based on the load. Since costs are based on the compute runtime usage, this will save costs considerably as less instances will be running in non-peak hours.
-
Other options for consideration
Discounts: GCP offers another great option of committed use discounts (CUDs). With CUDs, we can obtain great discounts in pricing over multiple cloud resources if we give spend commitments – for example, a commitment to use and pay for a certain amount for one or three years. The discounts are usually higher for a three-year commitment. For example, certain machine types get a 28% discount with a one-year commitment and a deep discount of 46% for a three-year commitment.
Cloud native approaches: In on-premises data centres, the VMs that run batch processing workloads are up and running all the time even though the batch processing jobs run only for a small duration of time. When these are lifted-and-shifted to the cloud and the cloud VMs are run the whole day, it results in a wastage of resources. The application and the VM instance keep running and are charged for even when there are no batch processing jobs being executed. Such workloads need to be redesigned so that the charge is only for the duration of the job. GKE CronJob, serverless mechanisms like Cloud Functions, Cloud Run, etc, can be used to limit costs to only the execution time.
Cloud logging
Applications migrating to GCP integrate with a cloud logging service to make good use of features like log explorer, logs-based metrics, etc, that help with troubleshooting. The costs of cloud logging are mainly based on the volume of data ingested. And if an organisation’s applications have not been logging the right volume of data on-premises, the logging costs after migration may come as an unpleasant surprise. Let us look at a few ways to save costs while making use of the features of cloud logging.
Environment-based decision: Cloud logging capabilities are much needed in production environments, but are not as necessary in others, such as development. So, look at the logging costs incurred in non-production environments. If they’re high, consider disabling cloud logging integration.
Right set of log files: Not every log that the application generates needs to be sent to cloud logging. Analyse and decide which logs are needed for analysis and troubleshooting purposes and filter out the unwanted ones while configuring the Ops Agent for integration.
Application logger configuration: Review the logger configuration of your application to ensure that the logs are at the right configuration level. As a best practice, production deployments should have the default logging at the info or warn level and not at the debug level, which should be enabled only temporarily for troubleshooting.
High-volume entries: Inspect the application logs in ‘Logs Explorer’ for unwanted, high-volume entries. Utilise the ‘Hide similar log entries’ feature to identify patterns and determine if they’re necessary.
Retention time: Logging, by default, comes with a 30-day retention period, with higher retention incurring additional costs. Thirty days is usually sufficient for most of the logs needed for application troubleshooting. Higher retention is needed only for special logs (e.g., logs stored for audit purposes). In such cases, ensure that such logs are routed separately to a different logging bucket and the higher retention period is applied only for that bucket.
These are some of the ways in which we can ensure that the right set of logs is sent to cloud logging and the corresponding costs are at optimal levels.
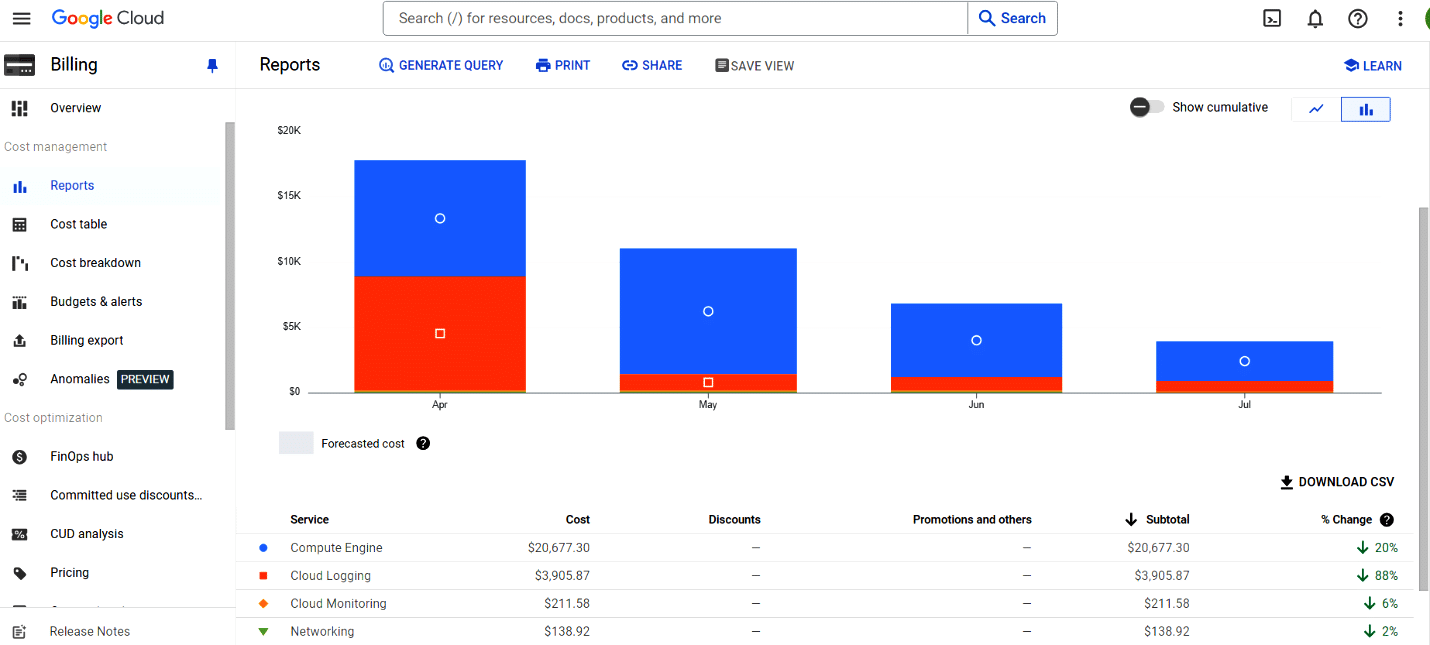
Figure 2 gives a four-month cost report for an application where some of the cost optimisation strategies mentioned above were applied. In the ‘% change’ column, we can see the realised savings of approximately 20% in compute engine costs and around 88% in cloud logging costs (when compared to the previous four months).
Cloud storage
Cost-effective storage: Cloud storage costs per GB per month are relatively low, making it a cost-effective solution for regular applications that use such storage for data transfer or sharing. However, for data-intensive applications that retain TBs of data, costs can add up quickly.
Storage classes: To optimise costs, we can look at the different storage classes provided by cloud storage. ‘Coldline’ and ‘Archive’ storage classes offer significantly lower prices than the default ‘Standard’ storage. If there is data with infrequent access needs, it can be stored using low-cost storage options like Coldline or Archive.
Automation: We can automate such cost saving actions using the ‘Object Lifecycle Management’ feature of cloud storage. We can create rules on the ‘Cloud Storage’ bucket – e.g., to downgrade storage class of objects older than 90 days to Coldline storage, delete objects older than 60 days, etc.
GCP Secret Manager
The GCP ‘Secret Manager’ service is used to securely store sensitive data. The costs associated with this service depend on the number of secrets stored and the number of access requests. In scenarios where the costs are high due to a huge volume of access requests, applications can consider caching such secrets in-memory, ensuring robust safeguards are in place to prevent any in-memory leaks. Such a caching approach will reduce the volume of access calls and the associated costs.
Multi-regional resiliency
GCP provides a very high uptime and great SLA metrics for their cloud services when deployed with a regional availability (single region with multiple zones) configuration. While this configuration suffices for most services, critical enterprise applications may require higher uptime. This prompts enterprises to look at multi-regional deployment plans for their applications. However, such plans incur added costs like additional infrastructure, cross-regional data replication and transfer, etc. Therefore, enterprises must make informed decisions and plan for only mission-critical applications and services for multi-regional deployments. Even with a multi-regional plan, based on the recovery time objective (RTO) metrics, they must decide on whether applications will go with hot-hot or hot-warm configurations across the regions. Hot-hot configurations incur higher costs due to additional infrastructure running in the resiliency region.
Monitoring the results
When applying the optimisation strategies, it is important to monitor the results to ensure we are achieving what we want. GCP’s ‘Cloud Monitoring Reports’ provide a detailed break-up of costs for each service, where results are available with daily granularity even up to the last day. This allows us to track the effectiveness of the changes made for optimisation.
Once optimal costs are achieved, alerts must be set up based on current and projected near-term costs to detect significant increases beyond expectations. This allows for informed decision-making and planning for the next iteration of analysis and optimisation as needed.
Cloud computing provides significant flexibility to enterprises by eliminating infrastructure bottlenecks and providing managed services for faster development and delivery. This helps organisations to be nimble, innovative and react fast to market and customer needs. However, there is no such thing as a free lunch. Every cloud service comes with its associated costs. Therefore, organisations and every individual within it must be mindful of the costs associated with every step that’s taken, making informed decisions to control and optimise cloud expenses. This keeps the organisation’s finances in the green, while also allowing the teams to leverage the full capabilities of the cloud.











