




























































Birds are beautiful and serve the environment in varied ways. A well-developed AI model can detect and classify bird sounds from large volumes of acoustic data to help monitor biodiversity and support global conservation efforts.
Birds contribute to environmental sustainability through various ecological functions. They pollinate plants, disperse seeds, control pests, scavenge, and engineer ecosystems. Birds serve as an indicator species, providing insights into environmental health. They offer cultural and economic benefits, and their droppings enrich soil fertility. Protecting bird populations and habitats is vital for maintaining these ecological roles and promoting a balanced environment.
The ornithology community is collecting many petabytes of acoustic data every year. This data helps to detect and classify bird sounds, as well as monitor the status and trends of biodiversity in ecosystems. It also helps to identify bird populations
and enhance conservation efforts.
Why bird voice recognition
Bird voice recognition is valuable for ornithology and conservation, especially in biodiverse areas. Here are a few benefits.
- Bird identification: Non-invasive and effective for detecting cryptic species.
- Bird population monitoring: Helps estimate population sizes and monitor changes over time.
- Behavioural studies: Provides insights into communication, social structures, and stress indicators.
- Habitat usage: Maps habitat preferences and assesses environmental changes.
- Migrant monitoring: Tracks migratory patterns and indicates climate change impacts.
- Conservation efforts: Aids in biodiversity assessments and early detection of invasive species.
Challenges of bird voice identification
Due to the complexity of bird vocalisations and ambient conditions, bird voice identification has numerous problems. Some of the obstacles are:
- Intra-species variation: Age, sex, health, and geographic location affect a bird’s call within its species.
- Inter-species similarities: Differentiating one species from another when they have remarkably similar calls is a challenge.
- Environmental noise: Wind, water, other animals, and human activity can be heard in natural habitats and can obscure bird cries.
- Recording quality: Quality of the recorded bird cries may be impacted by differences in the tools and methods used for recording.
- Limited data: Data is scarce and imbalanced for many bird species, particularly the uncommon ones.
Methods used for bird voice recognition
Various techniques are used to recognise the cries of different species of birds and analyse them:
- Audio recordings and software tools to identify bird species by their calls
- Spectrogram analysis techniques
- Customised applications that monitor bird populations and conservation efforts
- Avian studies on biodiverse areas combining traditional methods with bird voice recognition
- Automated recording units that are deployed to record bird calls continuously
- Machine learning algorithms to analyse recordings to identify species and call frequencies
- Citizen science programmes that engage the community in data collection
Developing a bird voice recognition model
The creation of a bird voice recognition model involves collecting audio recordings of birds, converting these into Mel spectrograms, training a CNN model to classify the Mel spectrograms, and evaluating and refining the model’s performance.
Figure 1 depicts the process of creating a bird voice model.
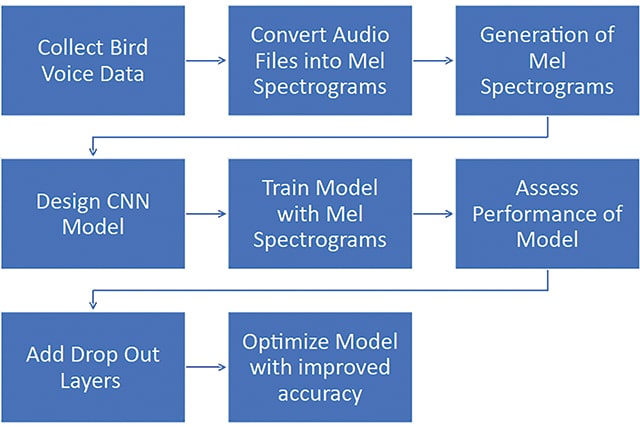
- Collecting bird voice data: In this initial step, recordings of various bird calls from numerous species and locations are gathered. The data selection process might involve focusing on birds found in a particular region
- Generating Mel spectrograms for bird voices: The audio files of bird voices are then converted into Mel spectrograms. The latter is a visual representation of the spectrum of frequencies of a signal that varies with time. The frequencies are scaled according to the Mel scale. This scale is designed for humans to perceive the pitch of sounds, which is useful in the identification of bird voices.
- Designing a CNN model: A convolutional neural network (CNN) is a type of machine learning model that is particularly suited for image recognition tasks. A CNN model that is appropriate for the task of identifying bird voices from the Mel spectrograms must be designed.
- Training the model with Mel spectrograms: The CNN model must be trained using the generated Mel spectrograms. During the training process, the model is input with numerous examples of Mel spectrograms, along with corresponding information about the bird calls. The model learns to recognise patterns in the Mel spectrograms that differentiate the calls of various bird species.
- Assessing the initial performance of the trained model: Next, the performance of the trained model must be assessed to determine how well it can correctly classify bird voices from the new Mel spectrograms it has not been exposed to during training.
- Improving model accuracy: The addition of a dropout layer will help in improving model accuracy.
- Optimised model with improved accuracy: The final step is an optimised model, which has significantly improved accuracy when it comes to classifying bird voices.
You can use the following steps to generate a functioning Mel spectrogram:
- Load audio file using librosa.
- Generate the Mel spectrogram from the audio data.
- Transform the Mel spectrogram into a decibel (log) scale.
- Normalise the spectrogram values to a range of [0, 1].
- Plot the normalised Mel spectrogram and save it as an image file in the specified directory.
Tentative code snippets are:
def savepicture(audio_path,dirval,file):y, sr = librosa.load(audio_path, sr=None)# Compute Mel spectrogramS = librosa.feature.melspectrogram(y=y, sr=sr)# Convert to decibels (log scale)S_db = librosa.power_to_db(S, ref=np.max)# Normalize to range [0, 1]S_normalized = (S_db - np.min(S_db)) / (np.max(S_db) - np.min(S_db))# Plot Mel spectrogramplt.figure(figsize=(10, 4))plt.axis(“off”)librosa.display.specshow(S_normalized, sr=sr, x_axis=’time’, y_axis=’mel’)plt.savefig(“/mnt/d/kaggle/birdchef-images/” + dirval + “/” +file.replace(“ogg”,”png”),bbox_inches=’tight’, pad_inches=0) plt.close() |
These save the sound as an image.
The layer architecture of the model
Figure 2 depicts the model layer architecture developed using Python and the open source libraries listed below.
- Librosa: Used for feature extraction of the Mel spectrogram.
- Matplotlib: Used to create visualisations of Mel frequencies, which are extracted from audio signals using the librosa library. It allows customisable and interpretable plots. This plotted data is saved as images.
- TensorFlow and Keras: Used for training the image data using a CNN.
- NumPy: Used for predictions.
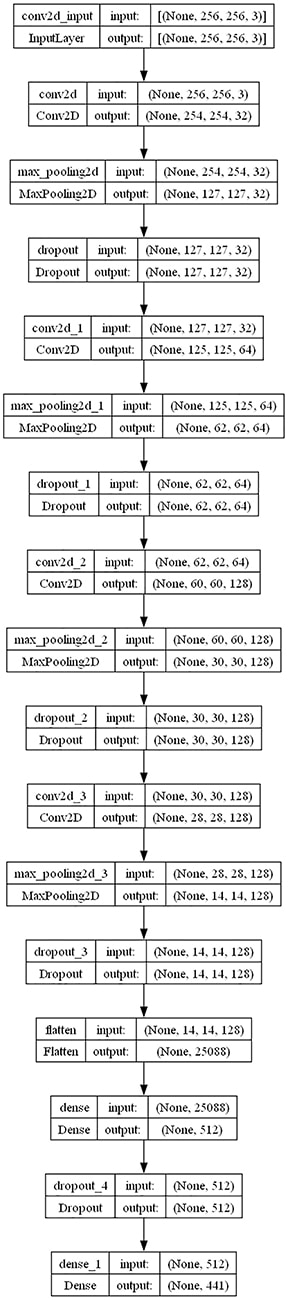
The different layers of the model are convolution layer, pooling layer, dropout layer and connected layers.
The important features of the image are extracted in the convolution layer. The convolution operation involves applying a filter to the image, which produces a feature map. The filter is a small matrix of weights that is learned by the model during training. The feature map shows how well the filter matches different parts of the image.
The pooling layer is used to reduce the dimensionality of the data. Pooling involves down-sampling the feature maps by taking the maximum or average value of a sub-region.
The dropout layer is used to prevent the model from overfitting to the training data. Dropout works by randomly dropping out a certain percentage of units from the neural network during training.
Connected layers are used to classify the image into one of several categories. This layer takes the output of the pooling layer and flattens it into a vector. The vector is then multiplied by a weight matrix and added to a bias vector. This produces a score and probabilities for each category. The category with the highest probability is the predicted class of the image.
A bird voice recognition model is a valuable tool for ornithology and conservation, especially in biodiverse areas. It helps in bird identification, bird population monitoring, habitat usage and migrant monitoring. Bird voice recognition enhances the understanding of avian biodiversity and ecological changes, and supports informed conservation. Protecting bird populations and habitats is vital for promoting a balanced environment.
Disclaimer The views expressed in this article are that of the authors. HCL and Tech Mahindra do not subscribe to the substance, veracity or truthfulness of the said opinion.













