

























































Data management is a complex process, made tougher due to the humongous amount of data being generated each day. Databases were developed to make sense of this data but these need to evolve continuously with the increasing demands being made on them. Following a few best practices will also help to manage data well.
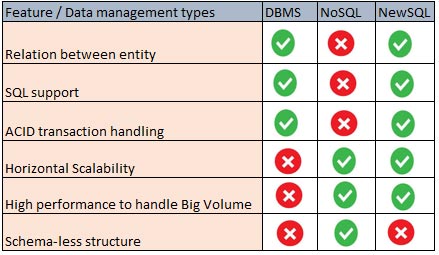
Databases came into the limelight during the initial growth of application programming. As data grew in volume, a second generation of database architecture evolved called NoSQL databases. These offered strong support in architecting a data warehouse or data lake-based application design.
First generation database systems (e.g., Oracle, MySQL) have a lot of flexibility in terms of developer access for querying and accessing/interpreting the data as compared to second generation (NoSQL) database systems like Hadoop and MongoDB. On the other hand, second generation database systems are designed to address the limitations of RDBMS in terms of handling volume and multi-branched structural data. To cater to online transaction processing (OLTP) of first generation databases and the structural accessibility for large volume data handled by second generation database systems, hybrid database systems called NewSQL have emerged as third generation database systems.
NewSQL database systems try to address the shortcomings of second generation database systems by combining some of the advantages of first generation systems like relation between entity models, ACID transaction handling capability, etc. Popular NewSQL database systems are VoltDB, ClusterixDB, CockroachDB and NeoDB.
Polyglot databases in cloud platforms
A data store is an integral component of any application development as it is the persistent store for handling all the data required for processing logic. Database solutions are moving towards polyglot databases, which combine multiple types of databases for an enterprise architecture. Polyglot databases are typically used in microservices architecture as they use multi-types of database systems in an integrated solution.
Such an integrated architecture is needed to ensure high performance for any type of data processing across different services. Typically used in cloud adoption, this kind of implementation is supported by DBaaS (database as a service). Data-driven thinking helps build enterprise architecture with a flexible data design.
DBaaS is a cloud based database management system (e.g., Aurora DB). It is highly scalable and offers enhanced security in cloud architecture. Suitable for large enterprise design, it offers shared infrastructure with the availability of monitoring and performance tuning tools.
Columnar databases
A database system is a matrix representation of rows (records) and columns (fields) of data accessed through queries. In a traditional RDBMS, a standard SQL query scans through each record, filters it based on the query condition, and populates the data in the required result set. This works well for small and medium applications. But when it comes to large solutions like data warehouse applications, where the number of columns and rows are far more, there are huge performance drops due to physical I/O during query operations when scanning through records and filters for required results.
NoSQL databases, which are schema less and don’t store in rows and columns but in key-value, document, graph or column-oriented data models, address this situation better with semi-structured or unstructured database models.
A columnar database is completely different from a traditional data structure as it stores data in columns and not in rows, and helps in querying for data with less disk access. This helps reduce the physical I/O and optimises the workload.
This database is suitable for large data processing systems like data warehouses, business intelligence systems or retail store operations. As it is self-indexed, managing data indexing for faster data access is easy.
Some examples of columnar databases that are very popular are MariaDB, ClickHouse, Apache Parquet, MonetDB and Apache HBase.
CAP theorem in cloud data architecture
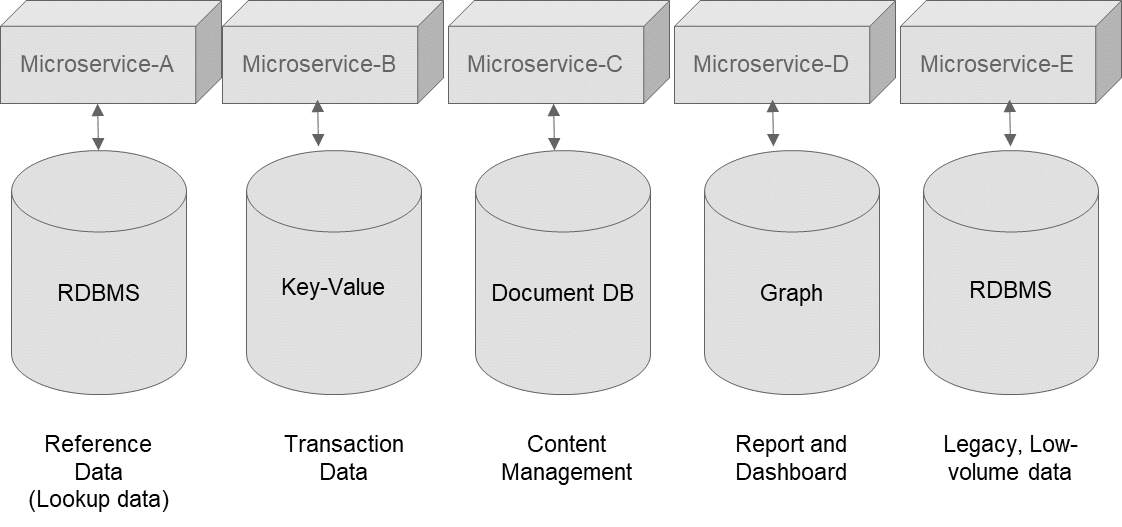
Any cloud architecture is built on certain key expectations, which include high-availability, cost-efficiency, security compliance and agility in design. The CAP theorem was conceived by Brewer (and hence is also called the Brewer theorem) in 1998 and then formally in 2000 to address the non-functional and architectural boundaries of distributed computing solutions. These were the early days of cloud computing.
As per Brewer, the bounding principles for any distributed service are consistency, availability and partition tolerance (CAP). Any architecture can comply with two of these three principles but not with all three at the same time.
Open data platforms
When open source first became a buzzword in the IT world, it was a revolutionary idea that reduced IT costs and changed the development ecosystem into a highly collaborative one. The current game-changing thought is ‘open data’. The idea is to develop an open data marketplace without compromising security and data privacy.
Hortonworks, IBM and Pivotal have been working on the Open Data Platform (ODP) for a few years and have released their own ODP architecture like ODPi and IBM Open Platform with Apache Hadoop (IOP), which are available on IBM Power Systems and Pivotal HD.
One important advantage of the ODP is that it offers new solutions for Big Data architecture with better time to market results. Today, e-governance, the financial industry, retail marketing and many other industries use open data platforms for targeted marketing and trend analysis.
Data lineage
It is important to trace the complete life cycle of data to understand the data source, how it travelled in different feed formats, how it got modified and who owns data in its various forms.
The data life cycle is termed data lineage and is useful for data debugging and understanding various metrics related to data architecture. Traditionally, to understand data duplicacy, errors in data and data governance, data provenance was used as a tool for tracking data.
Data lineage helps in decision making for data analytics activities, data analysis and debugging in data architecture. It is managed through metadata to store and retrieve data origin and transformation details. Data lineage tools like Collibra, Talend Data Fabric, Apache Nifi and Apache Atlas show data in its transformation and origin through metadata extraction, as well as the data flow of resilient distributed datasets (RDDs) using graphs and other visualisation maps.
Five W’s are important for metadata handling — what is the meaning of the data, who is using the data, when was it captured (first and subsequent changes), when is it being used (first and recent use), and where is the data stored/transformed. This helps to debug data errors or data duplication (de-duplication) and data validation during Big Data processing.
DataOps for a data lake solution in the AWS platform
Building a resilient data platform in the cloud is a tedious task as it must fit into the DevOps architecture to automate infrastructure provisioning, data export, platform setup, data movement and processing, and data validation and testing in order to reduce the repetitive manual effort of data engineering.
A data lake combines a data warehouse and database setup in AWS, developing a DataOps solution to accelerate data processing activities. DataOps aims at developing a customised DevOps and AIOps solution for data platforms, which combines the activities of data management, data migration, data preparation (pre-migration), data validation (post migration), data analytics, platform setup and data governance.
Autonomous database: The next-generation cloud database
A DBA or database administrator handles database tuning, security activities, backups, disaster recovery, server/platform updates, health checks and all the other management and monitoring activities of databases. When a cloud platform is used for application and database development, these activities become critical for improving security, performance and cost efficiency. Oracle has developed a cloud database it calls an ‘autonomous database’ which automates many of the DBA’s tasks by using machine learning services for self-healing, self-repairing, self-securing and self-driving of database platforms.
Top trends in database management
Multi-cloud and hybrid data management: Organisations are increasingly adopting a multi-cloud strategy to leverage the best-in-breed services from various providers. This necessitates robust data management solutions that can handle data across heterogeneous cloud environments. Hybrid cloud deployments, integrating on-premises infrastructure with the cloud, further complicate data management.
Data democratisation and self-service analytics: Traditionally, data resided within silos controlled by IT departments. Data democratisation aims to break down these barriers, empowering business users with access to data and self-service analytics tools. Cloud platforms will see a rise in user-friendly data catalogues, data visualisation tools, and low-code/no-code analytics platforms, enabling non-technical users to explore and derive insights from data.
AI and machine learning (ML) for data management automation: Automating data management tasks through AI and ML will be a significant trend. Techniques like data profiling, data cleansing, and anomaly detection powered by AI can significantly reduce manual effort and improve data quality. Additionally, ML-powered data governance tools can automate data classification, access control enforcement, and data lineage tracking.
Focus on data security and privacy: As data regulations like GDPR and CCPA become more stringent, data security and privacy will remain paramount. Cloud platforms will continue to invest in robust security features like encryption at rest and in transit, multi-factor authentication, and data residency options.
Real-time data management and stream processing: The increasing importance of real-time analytics necessitates efficient real-time data management. Cloud platforms are evolving to handle high-velocity data streams from sources like IoT devices and sensor networks. Stream processing frameworks like Apache Kafka and Apache Flink will play a vital role in ingesting, processing, and analysing real-time data streams for near real-time decision-making.
Serverless data management: Serverless computing offers a pay-per-use model for data management tasks, eliminating the need for infrastructure provisioning and management. Serverless data pipelines built with tools like AWS Lambda or Google Cloud Functions will enable cost-effective data processing without managing servers.
Integration with DataOps practices: DataOps methodologies promote collaboration between data teams and developers for faster data delivery. Cloud platforms will see increased integration with DataOps tools for version control, continuous integration/continuous delivery (CI/CD), and automated testing of data pipelines.
Data management in cloud platforms: The challenges
The major challenge is security, which includes data breaches and cyber threats. The centralisation of data in the cloud makes it a prime target for cyberattacks. Data breaches can lead to significant financial losses and reputational damage. Encryption and data protection mechanisms are critical. Another challenge is proper governance of data, ensuring data integrity and quality. Framing the right policies for data life cycle management is essential.
Compliance and regulatory issues
Adherence to GDPR, HIPAA, and other regulations: Different regions have varying regulatory requirements, and businesses must ensure their data management practices comply with all relevant laws.
Challenges in maintaining compliance across different regions: Multinational organisations face the challenge of adhering to multiple regulatory frameworks, which can be complex and resource-intensive.
Cost management
Balancing cost efficiency with performance: Optimising the cost-performance ratio involves selecting appropriate service tiers and scaling resources efficiently.
Unexpected costs and budget overruns: Hidden costs, such as data transfer fees and underutilised resources, can lead to budget overruns if not properly managed.
Data integration and interoperability
- Integrating data from multiple sources: Combining data from different sources into a cohesive system can be challenging, especially when dealing with disparate formats and systems.
- Ensuring compatibility between different cloud services: Ensuring seamless interoperability between services from different cloud providers requires careful planning and the use of standardised protocols and APIs.
Scalability and performance
- Managing data growth and ensuring performance at scale: As data volumes grow, maintaining performance becomes increasingly complex. Effective indexing, partitioning, and load balancing are essential.
- Technical solutions for scalability: Techniques such as sharding (dividing a database into smaller, more manageable pieces) and load balancing (distributing workloads evenly across resources) are critical for maintaining performance.
Data backup and disaster recovery
- Implementing robust backup solutions: Regular backups are essential to protect against data loss. Cloud platforms offer various backup services, but organisations must ensure they are configured correctly.
- Strategies for effective disaster recovery: A comprehensive disaster recovery plan, including regular testing and updating, ensures that data can be quickly restored in case of an outage or failure.
Best practices in data management
Managing data effectively in the cloud is crucial for security, compliance, and getting the most out of your information. Here are some top best practices to consider.
Security
Encryption throughout the journey: Implement encryption for your data at rest (stored in the cloud) and in transit (moving between locations). This makes data unreadable without a decryption key, safeguarding it from unauthorised access. Utilise cloud provider encryption solutions and understand how to manage your encryption keys effectively.
Data governance framework: Establish a robust data governance framework that dictates how data is handled in the cloud. This includes classifying data based on sensitivity (e.g., financial data requiring stricter controls), setting access controls (who can view or modify data), and outlining data retention policies (how long data is stored).
Identity and access management (IAM): Implement a granular IAM system to control access to your cloud data. This ensures only authorised users have access to specific datasets based on their roles and permissions. Regularly review and update access controls to minimise the risk of unauthorised access.
Data optimisation and life cycle management
Data life cycle management: Implement policies to automate tasks associated with your data throughout its life cycle. This could include automatic archiving of inactive data to cheaper storage tiers, deletion of obsolete data based on retention policies, and migration of data between cloud environments for disaster recovery or cost optimisation purposes.
Data cataloguing and classification: Create a comprehensive data catalogue to track your data assets across the cloud and on-premises systems. This catalogue should include metadata (data about your data) such as data type, location, sensitivity, and ownership. A well-maintained data catalogue helps you understand what information you have, where it resides, and who is responsible for it.
Tiered storage: Utilise a tiered storage strategy to optimise storage costs. Cloud providers offer various storage options with different price points based on access frequency. Store frequently accessed data in high-performance tiers and less frequently accessed data in lower-cost tiers.
Data backup and disaster recovery: Establish a data backup and disaster recovery plan to ensure your data is recoverable in case of outages or disruptions. Regularly test your backup and recovery procedures to ensure they function as intended.
User training and education: Train your users on cloud data security best practices. This includes educating them on data classification, password hygiene, and how to identify and report suspicious activity.
Compliance: Be aware of any relevant industry regulations or compliance requirements that apply to your data. Cloud providers offer tools and services to help you meet compliance standards, but it’s your responsibility to understand your obligations.










