

























































Digital transformation initiatives and the need for 24/7 customer support have been instrumental in propelling the adoption of AI chatbots. But these bots need authentic and well-developed large language models (LLMs) to work efficiently. LLMs, in turn, are dependent on AI databases that are built on data that is consistent, complete and accurate. There are quite a few open source and free AI databases to choose from.
By leveraging advancements in natural language processing (NLP) and machine learning, artificial intelligence (AI) chatbots have revolutionised the way businesses interact with customers, offering a seamless, automated interface for a multitude of tasks. These sophisticated conversational agents are now pivotal in numerous sectors, ranging from customer service and e-commerce to healthcare and banking, significantly enhancing user engagement and operational efficiency.
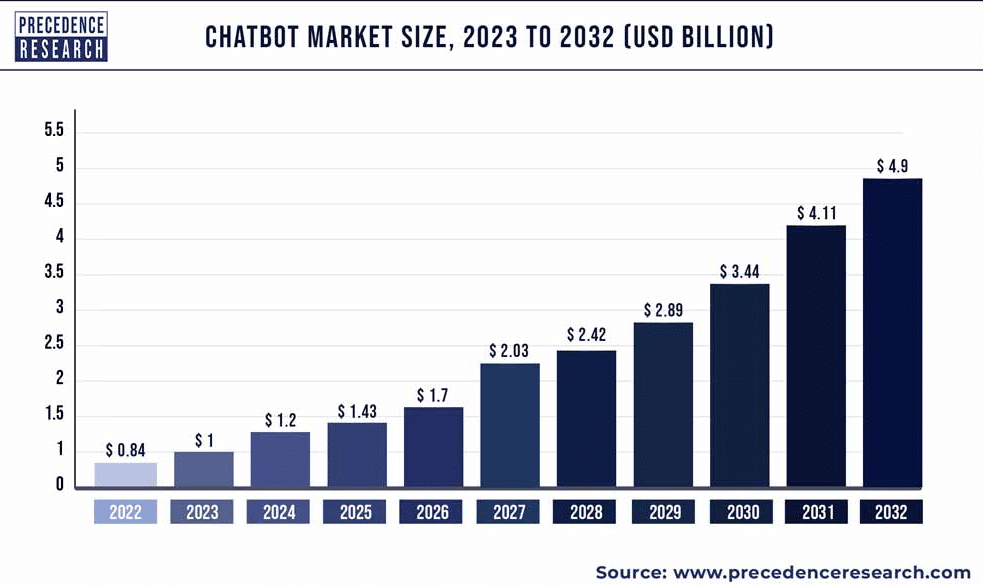
In 2022, the global market for AI chatbots was appraised at approximately US$ 0.84 billion. Forecasts for the coming decade suggest a remarkable expansion. By 2032, the AI chatbot market is anticipated to burgeon to around US$ 4.9 billion. This projection reflects a compound annual growth rate (CAGR) of 19.29% between 2023 and 2032. Such robust growth can be attributed to several factors, including technological advancements in AI and machine learning, increased smartphone penetration, and a growing preference for automated customer interaction solutions.
The sophistication of AI chatbots continues to evolve, with modern iterations capable of understanding and processing complex queries, delivering personalised responses, and learning from interactions to improve future performance. As these intelligent systems become more advanced and pervasive, their impact on global business operations is poised to become increasingly profound, marking a significant shift in the landscape of digital customer service and engagement.
Key AI chatbots for multiple applications
The landscape of artificial intelligence chatbots is richly populated with sophisticated entities designed to cater to a multitude of applications, each bringing unique capabilities to the fore. Among these, ChatGPT, developed by OpenAI, stands out as a preeminent conversational agent. Leveraging the vast language model GPT-4, ChatGPT is endowed with the ability to generate human-like text, comprehend complex queries, and provide detailed, contextually relevant responses. Its applications span from customer support and virtual assistance to content creation and educational tutoring, making it a versatile tool in various professional and personal contexts.
Bing Chat, an extension of Microsoft’s Bing search engine, integrates AI-driven conversational capabilities to enhance the user experience. Utilising advanced natural language processing (NLP) techniques, Bing Chat provides succinct and precise answers to user enquiries, effectively transforming search interactions into dynamic dialogues. This integration not only streamlines information retrieval but also supports more intuitive and efficient user engagement, proving invaluable in customer service, research, and casual information-seeking scenarios.
Microsoft’s Copilot is designed to assist users by automating routine tasks, generating content, and providing intelligent suggestions within applications like Word, Excel, and Outlook. By harnessing AI to enhance productivity, Copilot reduces the cognitive load on users, enabling them to focus on tougher tasks. Its capability to learn and adapt to user preferences enhances its utility.
The AI chatbot domain is enriched by other notable contenders too. For instance, IBM’s Watson Assistant, renowned for its robust AI and machine learning foundations, is extensively utilised in enterprises for customer service automation and internal operations management. Similarly, Google’s Dialogflow offers developers a comprehensive framework to design and deploy conversational interfaces across numerous platforms, ensuring seamless integration and consistent user experiences.
Chatbots like Replika (which focuses on personal companionship and mental well-being) exemplify the expanding horizons of AI applications. Replika leverages sophisticated algorithms to simulate empathetic and supportive conversations, thereby providing users with personalised and therapeutic interaction.
The proliferation of AI chatbots such as ChatGPT, Bing, Copilot, and others underscores the transformative impact of AI on communications and productivity.
Large language models (LLMs) and AI databases
Large language models (LLMs), characterised by their extensive parameter counts and sophisticated architectures, harness vast datasets to cultivate an understanding of linguistic patterns, semantic nuances, and contextual relevance. The underlying architecture of LLMs facilitates proficiency in generating, comprehending, and manipulating human language.
At the core of LLMs lies the transformer model, which utilises mechanisms to weigh the significance of each word in a sentence relative to others, thereby capturing intricate dependencies and enhancing contextual comprehension. This allows LLMs to excel in a myriad of linguistic tasks, ranging from text generation and translation to sentiment analysis and question-answering systems. The pre-training and fine-tuning paradigm employed in developing LLMs further increases their versatility. Pre-training on diverse and voluminous corpora equips the model with a broad linguistic foundation, which is subsequently refined through fine-tuning on task-specific datasets, thereby optimising performance across various applications.
The ascendancy of LLMs in the AI landscape is not without challenges. The computational resources required for training and deploying these models raise significant concerns regarding scalability, energy consumption, and accessibility. Additionally, the opaqueness of their decision-making processes, often described as a ‘black box’, engenders issues related to interpretability and trustworthiness. Despite these challenges, the potential of LLMs to revolutionise human-computer interaction, drive advancements in automated content creation, and enhance decision-making processes across industries underscores their transformative impact on contemporary AI research and applications.
AI databases constitute the bedrock upon which the edifice of artificial intelligence is constructed, serving as repositories for the vast amounts of data integral to training sophisticated machine learning models. These databases are meticulously curated to encompass a diverse array of data types, including text, images, audio, and structured datasets, thereby providing a rich substrate for AI algorithms to extract patterns, infer correlations, and make predictions.
The architecture of AI databases is designed to address the unique demands of AI workloads, emphasising scalability, speed, and flexibility. Distributed database systems, often leveraging cloud infrastructure, facilitate the handling of petabyte-scale datasets, ensuring rapid data retrieval and real-time processing capabilities. The integration of advanced indexing techniques, such as hash-based indexing and tree structures, optimises query performance, thereby accelerating the data preprocessing and feature extraction stages crucial for machine learning workflows.
A paramount consideration in the development and maintenance of AI databases is data quality. Ensuring the accuracy, completeness, and consistency of data is imperative, as the efficacy of AI models is intrinsically linked to the quality of the training data. Sophisticated data validation protocols, anomaly detection algorithms, and data augmentation techniques are employed to enhance the robustness and reliability of AI databases. Additionally, the ethical implications of data usage, encompassing privacy concerns and bias mitigation, necessitate stringent governance frameworks to uphold data integrity and foster trust in AI systems.
The interplay between AI databases and LLMs exemplifies the symbiotic relationship within the AI ecosystem. While LLMs depend on the vast and diverse datasets housed within AI databases to hone their linguistic capabilities, the insights gleaned from LLMs can, in turn, help refine these databases. This dynamic interaction propels the continuous evolution of both AI databases and LLMs, driving forward the frontier of artificial intelligence research and its practical applications.
Prominent vector databases for AI chatbots
| Database | URL |
| Milvus | https://milvus.io/ |
| Pinecone | https://www.pinecone.io |
| Vespa | https://vespa.ai |
| Qdrant | https://qdrant.tech |
| Weaviate | https://weaviate.io |
| FAISS (Facebook AI Similarity Search) | https://github.com/facebookresearch/faiss |
| Annoy (Approximate Nearest Neighbors Oh Yeah) | https://github.com/spotify/annoy |
| Vald | https://vald.vdaas.org |
Free vector databases for LLMs and AI chatbots
Vector databases play a pivotal role in enhancing the efficiency and performance of LLMs and AI chatbots. These databases serve as repositories for storing and managing high-dimensional vector representations of textual data, facilitating rapid and accurate similarity searches, which are fundamental to various NLP tasks. By encoding textual inputs into dense vector embeddings, vector databases enable LLMs and chatbots to effectively capture semantic similarities and relationships between words, phrases, and documents, thereby empowering them to deliver more contextually relevant responses and recommendations.
One prominent vector database is Pinecone, which provides a scalable and efficient platform for vector indexing and similarity search, enabling real-time retrieval of nearest neighbours based on vector representations. By leveraging advanced indexing techniques such as approximate nearest neighbour (ANN) search algorithms, Pinecone optimises the retrieval process, ensuring fast and accurate similarity matches even in high-dimensional vector spaces. It offers seamless integration with popular machine learning frameworks and cloud platforms, facilitating easy deployment and scalability of AI applications.
Another notable vector database is Vespa, developed by Verizon Media. Vespa is an open source, scalable Big Data serving platform that supports efficient storage and retrieval of large-scale vector embeddings. With built-in support for vector indexing and similarity search functionalities, Vespa enables LLMs and chatbots to efficiently query and retrieve relevant information from vast collections of textual data. Features such as real-time updates, ranking models, and distributed processing capabilities make it well-suited for building high-performance AI applications with stringent latency and throughput requirements.
Milvus is yet another vector database that has gained traction in the LLM and AI chatbot community. An open source vector similarity search engine developed by Zilliz, it is designed to handle massive-scale vector indexing and retrieval tasks efficiently. Leveraging cutting-edge indexing algorithms and data structures optimised for vector data, Milvus offers fast and accurate similarity search capabilities, enabling LLMs and chatbots to process large volumes of textual data with minimal latency. It supports flexible deployment options, including standalone, distributed, and cloud-based deployments.

Other open source libraries and frameworks such as FAISS (Facebook AI Similarity Search) and Annoy (Approximate Nearest Neighbors Oh Yeah) provide essential tools and algorithms for vector indexing and similarity search tasks. FAISS, developed by Facebook AI Research, offers highly optimised implementations of state-of-the-art algorithms for efficient similarity search in large-scale vector spaces. Similarly, Annoy, developed by Spotify, provides a lightweight and efficient library for approximate nearest neighbour search, making it suitable for resource-constrained environments and rapid prototyping of AI applications.
The following databases provide diverse and rich sources of text data, essential for developing and enhancing large language models and AI chatbots.
|
Free datasets for LLMs and AI chatbots
The realm of artificial intelligence, particularly in the development and deployment of large language models (LLMs) and AI chatbots, has witnessed an unprecedented surge in interest and innovation. Central to this burgeoning field is the availability of expansive, high-quality datasets which underpin the training and refinement of these sophisticated models. In the open source community, several free databases have emerged as pivotal resources, each offering unique attributes that cater to the diverse requirements of AI researchers and developers.
One of the most prominent free databases is the Common Crawl corpus, a repository that offers petabytes of web-crawled data amassed from billions of web pages. This dataset is invaluable for LLMs due to its vastness and diversity, encompassing a myriad of languages and topics. The Common Crawl’s extensive repository enables models to learn nuanced linguistic patterns and broad contextual understanding, essential for generating human-like text and engaging in coherent conversations. The corpus is updated regularly, ensuring that the data reflects the evolving nature of internet content, thereby enhancing the temporal relevance and accuracy of the models trained on it.
Another critical resource is the Wikipedia dataset, which, being more curated and structured than Common Crawl, provides a rich source of factual and encyclopaedic knowledge. The text from Wikipedia is meticulously written and edited, making it an excellent training ground for AI models that require a high degree of reliability and accuracy in their responses. The structured nature of Wikipedia data, with its comprehensive categorisation and extensive cross-referencing, aids in the development of LLMs capable of understanding complex relationships and hierarchies within information.
The Project Gutenberg collection also stands out as an essential free database, offering a vast array of literary works that span several centuries and genres. This repository is particularly beneficial for training models in understanding various literary styles, historical contexts, and diverse narrative forms. By incorporating the rich, stylistically varied texts from Project Gutenberg, LLMs can achieve a more profound grasp of language subtleties, idiomatic expressions, and cultural references, which are pivotal for generating text that resonates with human readers at emotional and intellectual levels.
In addition to these text-based resources, image-text datasets like the Visual Genome database are crucial for developing multimodal AI systems. Visual Genome provides a detailed, structured dataset of images annotated with descriptive language, facilitating the training of models that can integrate visual and textual information. This capability is essential for applications such as image captioning, visual question answering, and other tasks that require a seamless interplay between visual perception and language understanding.
The OpenSubtitles database, consisting of a vast collection of movie and TV subtitles, offers a unique dataset for training conversational agents. The dialogue-rich content in this database is instrumental in teaching AI models the nuances of human conversation, including colloquialisms, emotional expressions, and contextual adaptations. By leveraging such dialogue-heavy datasets, developers can enhance the conversational abilities of AI chatbots, making them more adept at engaging in dynamic, contextually appropriate interactions with users.
The availability of these diverse free databases is instrumental in the advancement of large language models and AI chatbots. Each dataset, with its unique characteristics and strengths, contributes to the multifaceted training process required to create sophisticated, reliable, and versatile AI systems. As the field of artificial intelligence continues to evolve, the role of these open source datasets will undoubtedly remain pivotal, driving innovation and enabling the development of more advanced and capable AI technologies.











