





























































Machine learning models must be developed with care. When based on centralised data, they are prone to a single point of failure and can attract cyberattacks leading to data breaches. Federated learning, which can be used to build models based on decentralised data, addresses this challenge successfully.
At its core, artificial intelligence (AI) encompasses algorithms designed to interpret, predict, and potentially alter data streams to facilitate decision-making processes that traditionally required human intervention. These complex algorithmic structures are often built upon machine learning models that train on large datasets, enabling the AI to learn from patterns and improve its accuracy over time.
AI is transforming numerous sectors, enabling enhanced efficiency, improved accuracy, and innovative solutions to longstanding challenges. Here are some of its practical real-world applications.
Healthcare
- Patient diagnostics: AI helps to interpret medical imaging faster and often more accurately than human radiologists, aiding in the early detection of conditions like cancer.
- Robotic surgeries: Sophisticated robots assist surgeons in performing delicate operations with higher precision and control, potentially reducing recovery times.
- Personalised medicine: AI analyses individual health profiles to tailor drug regimens and therapies that optimise patient outcomes.
Finance
- Automated trading systems: AI helps analyse market data to execute trades at optimal times, aiming to maximise returns or minimise risks.
- Fraud prevention: By learning from transaction data, AI can identify patterns indicative of fraudulent activities, securing users against potential losses.
- Risk management: It can assess client portfolios and market conditions, helping firms manage risk more effectively.
Automotive and transportation
- Self-driving cars: AI powers the software that allows vehicles to navigate and make decisions without human input, aiming to improve safety and reduce traffic incidents.
- Smart traffic management: It optimises traffic patterns and signal timings, reducing road congestion and improving urban mobility.
- Supply chain optimisation: It can help predict and manage logistical challenges, enhancing efficiency right from warehouse operations to delivery routes.
Retail
- Customer experience: AI algorithms offer personalised shopping experiences by recommending products based on browsing and purchase history.
- Inventory management: AI predicts market demand, helping retailers stock efficiently and reduce excess inventory.
- Chatbots and virtual assistants: These AI-powered tools handle customer enquiries instantaneously, improving service quality and operational efficiency.
Manufacturing
- Predictive maintenance: By monitoring equipment data, AI predicts when machines are likely to fail, scheduling maintenance to avoid costly downtime.
- Quality assurance: AI systems automate the inspection process for manufactured goods, enhancing product quality and consistency.
- Production optimisation: AI streamlines production processes, optimising resource use and output levels.
Education
- Customised learning experiences: AI adapts educational content to fit the learning speeds and styles of individual students, potentially improving educational outcomes.
- Automation of routine tasks: Tasks such as grading and attendance can be managed by AI, allowing educators to focus more on teaching.
- Interactive learning tools: AI-driven simulations and interactive modules enhance student engagement and facilitate active learning.
Media and entertainment
- Content personalisation: Streaming platforms use AI to analyse viewing habits and tailor content recommendations to individual preferences.
- Creative processes: AI assists in generating music, literature, and digital art, pushing the boundaries of traditional creative methods.
- Game design: It enhances the complexity and adaptiveness of gaming environments, creating more immersive experiences for players.
Cybersecurity
- Intrusion detection: AI systems can continuously monitor network activities for suspicious behaviour, enabling rapid response to potential threats.
- Security automation: These systems can automate responses to cyber threats, significantly reducing response times and mitigating impacts.
Agriculture
- Precision farming: Data from drones and sensors can be analysed to guide planting, watering, and fertilisation processes, maximising crop yields.
- Automated equipment: From autonomous tractors to robotic harvesters, AI-driven machinery helps increase farm productivity and reduce labour costs.
Telecommunications
- Network management: AI optimises network operations, improving connectivity and reducing outages.
- Customer service: AI chatbots address customer queries and issues quickly, enhancing user satisfaction.
Security and privacy aspects in AI models
The integration of AI into various facets of digital and physical operations has introduced complex challenges regarding security and privacy. These challenges are multifaceted and require meticulous consideration to mitigate potential threats and vulnerabilities associated with AI models.
The inherent intricacies of AI algorithms, especially those driven by deep learning, necessitate vast amounts of data to train. This data often includes sensitive information, raising significant privacy concerns. Ensuring the confidentiality and integrity of this data is paramount, as breaches can lead to severe privacy violations. Techniques such as differential privacy, which involves adding noise to the data to obscure individual data points while still allowing for overall patterns to be learned, and federated learning, where the model is trained across multiple decentralised devices or servers holding local data samples, are being explored to address these privacy concerns. These methodologies strive to balance the utility of data with the necessity of protecting individual privacy.
AI systems are susceptible to various forms of attacks. Adversarial attacks, in which small, intentionally designed perturbations are introduced to input data to deceive AI models into making erroneous predictions, pose a significant threat. These vulnerabilities could be exploited in critical systems, such as autonomous vehicles and security surveillance, to provoke unintended behaviour, potentially leading to catastrophic outcomes.
The opacity of AI decision-making processes, often referred to as the ‘black box’ problem, complicates efforts to ensure accountability and fairness. The lack of transparency can obscure biases embedded within the AI models, potentially amplifying existing societal biases. Addressing this issue requires sophisticated techniques for model explainability and interpretability. Advanced algorithms that can elucidate the decision-making process of AI systems are crucial for validating the fairness of these decisions and ensuring they comply with ethical standards.
Centralised vs decentralised data in AI models
The centralised data systems in AI involve the aggregation of data within a singular, often monolithic repository. This model is traditionally favoured for its efficiency in data management and processing, facilitating the rapid training of AI models by providing copious amounts of data in a unified location. However, from a security perspective, centralised systems present a significant vulnerability: the risk of a single point of failure.
A successful cyberattack on a centralised system can lead to extensive data breaches, compromising a vast array of sensitive information simultaneously. The concentration of data not only attracts malevolent actors but also exacerbates the potential damage inflicted by security breaches. Centralised systems pose inherent risks due to the consolidation of data, which might enable unauthorised surveillance and data mining practices.
Conversely, decentralised data systems distribute data across multiple nodes or locations, which inherently enhances data security by mitigating the risks associated with a single point of failure. In such systems, cyberattacks can be considerably less detrimental, as the dispersed nature of data storage requires an attacker to compromise multiple points to reconstruct comprehensive datasets. This architectural dispersion not only complicates unauthorised data access but also enhances data resilience and redundancy, thereby bolstering overall system robustness against data loss or manipulation.
From a privacy standpoint, decentralised systems offer superior control and autonomy to individual data contributors. By enabling data to reside closer to its source, these systems empower users to exert greater control over their personal information, potentially enabling more stringent privacy settings and personalised data-sharing preferences. The implementation of technologies such as blockchain in decentralised networks can further secure data transactions and ensure transparency, while maintaining user anonymity and privacy.
Federated learning for security of AI models
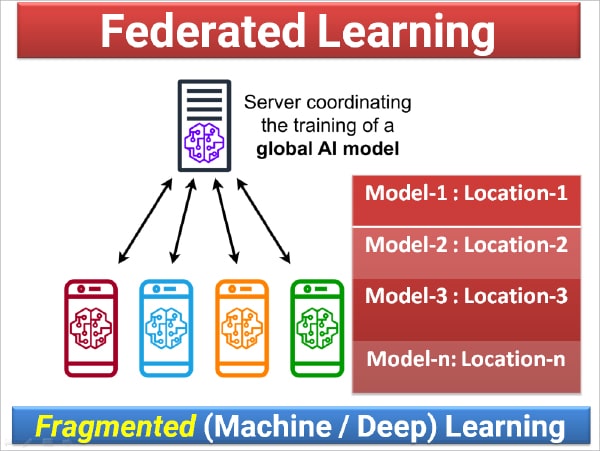
Federated learning represents a paradigm shift in the development and deployment of AI models, premised on the decentralisation of data processing. This innovative approach is instrumental in enhancing the security and privacy of AI models in a hyper-connected digital ecosystem. The necessity of federated learning emerges primarily from the growing concerns around data privacy, security breaches, and the centralised nature of traditional data processing systems.
Using federated learning, data is fragmented in chunks and distributed to multiple locations or organisations where multiple machine learning models are created in Pickle (PKL) or any other format. These multiple PKL files are collected from different locations ensuring that the entire dataset is not given to one location or single organisation.
Federated learning introduces an additional layer of security by leveraging techniques such as differential privacy and secure multi-party computation. Differential privacy ensures that the shared updates do not allow for the reconstruction of the underlying data, effectively anonymising individual contributions to a degree that prevents potential misuse. These methodologies ensure that the collaborative training process across multiple decentralised nodes does not compromise the confidentiality of the data.
Federated learning inherently supports a more robust model by aggregating a diverse array of data sources, each contributing unique insights that are reflective of varied user environments and behaviours. This diversity not only enriches the training process, resulting in more generalised and robust AI models, but also dilutes the risk of model poisoning or adversarial attacks, where malicious actors attempt to skew model performance by tampering with training data.
By decentralising the training process and ensuring that no single entity can monopolise data interpretation and subsequent AI application, federated learning promotes a balanced power distribution in the field of artificial intelligence. This not only helps prevent data monopolies but also fosters a more competitive and diverse technological ecosystem, ultimately leading to more innovative and fair AI solutions.
Implementation of federated learning in Python
Let’s suppose there is a dataset of one million records related to patients and we need to train a machine learning or deep learning model on it. Using federated learning, the entire dataset is divided into multiple chunks like data_part1.csv, data_part2.csv, data_part3.csv, and so on. In each chunk of data, there are different records or data files. Each of these data chunks or data parts is given to a different organisation to build an AI model, so that a single organisation cannot access or leak the entire dataset.
In the following code snippet, a model is trained on data_part1.csv. The other data chunks or fragmented data will be given to other organisations in the same format to ensure privacy of the entire dataset.
import pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifierimport joblib# Load the datasetdata = pd.read_csv(“data_part1.csv”)# Split the dataset into features and targetX = data.drop(columns=[‘PatientID’, ‘Disease’])y = data[‘Disease’]# Split data into train and test setsX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Create and train the Random Forest classifierrf_classifier = RandomForestClassifier(n_estimators=40, random_state=42)rf_classifier.fit(X_train, y_train)# Evaluate the modelaccuracy = rf_classifier.score(X_test, y_test)print(“Accuracy:”, accuracy)# Save the model to a .pkl filejoblib.dump(rf_classifier, ‘random_forest_model_part1.pkl’) |
Using majority voting for merging multiple trained models
During the merging process, these models are aggregated such that they contribute equally to the final decision. The majority voting system functions by evaluating the predictions from each model on a given input; the final output prediction is determined by the most common result (majority vote) among all models. This democratic approach not only mitigates biases that might occur due to anomalies in individual datasets but also harnesses the diverse data characteristics learned across various environments, potentially leading to a more robust and generalised model. This method proves particularly effective in scenarios where no single model can be trusted to independently make accurate predictions, thereby enhancing the reliability and overall performance of the federated learning system.
In the following code snippet, multiple PKL files are used for getting results from multiple models. This is an example of the majority voting approach.
import pandas as pdimport joblib# Load the test datatest_data = pd.DataFrame({‘Age’: [55],‘Diabetic’: [1],‘BloodPressureLevel’: [140] # Example blood pressure level})# Load the trained Random Forest modelsmodel_part1 = joblib.load(‘random_forest_model_part1.pkl’)model_part2 = joblib.load(‘random_forest_model_part2.pkl’)# Predict disease using the first modelprediction_part1 = model_part1.predict(test_data)# Predict disease using the second modelprediction_part2 = model_part2.predict(test_data)# Combine predictions using majority votingprediction_combined = 1 if (prediction_part1.sum() + prediction_part2.sum()) >= 1 else 0print(“Combined Prediction:”, prediction_combined) |
Federated learning offers a promising avenue for collaborative, privacy-preserving data analysis and model training across multiple decentralised entities. This technique not only allays concerns related to privacy and data sovereignty but also significantly reduces the bandwidth required for transmitting large datasets.
The research in federated learning is primarily focusing on improving algorithm efficiency, data security, and system scalability. Key research areas include the development of robust algorithms that can efficiently handle non-IID (independently and identically distributed) data across various nodes. Such algorithms strive to overcome the skewed data distribution that is characteristic of many real-world scenarios, where data collected by different nodes may vary significantly in size, type, and quality.
Federated learning presents a robust framework for handling data across dispersed networks while adhering to privacy and security requirements. As industries and institutions increasingly prioritise data confidentiality alongside the need for powerful analytical tools, federated learning is poised to become more pivotal. This progressive field promises to enhance the efficacy and efficiency of machine learning models across various applications and pioneer new frontiers in the ethical utilisation of Big Data.












