


























































Encoding and decoding help transform images, videos, graphics and text into the binary format that computers understand. Python has built-in functions and modules to perform encoding and decoding operations on string data.
Data is the core of any digital application, but how does it communicate with the computers that process it? Computers only understand the binary format, which is a system of zeros and ones, but data can come in various forms, such as images, videos, graphics, or text. How do we convert these data forms into binary format so that computers can understand and manipulate them? This is where encoding and decoding techniques come in handy. Let’s explore how to encode and decode data in Python, one of the most popular and powerful programming languages for data science.
Encoding and decoding are processes of converting string data from one format to another, depending on the context and the goal. For example, you may want to encode string data that contains special characters or symbols into a format that can be transmitted over the internet, such as URL encoding. Or, you may want to decode a string of data that is encrypted or compressed into a format that can be read and understood, such as Base64 decoding. Now this is all confusing, right? Let’s delve deeper to clearly understand when to use which method. But first let’s list different types of encoding and decoding methods, such as ASCII, Unicode, Base64, or URL encoding. Each method has its own rules and standards for how to represent string data in different formats.
Python is a programming language that has built-in functions and modules to perform encoding and decoding operations on string data. For example, you can use the encode() and decode() methods to convert string data between different encodings, such as UTF-8, Latin-1, or ASCII. You can also use the ‘binascii’ module to convert string data between binary and ASCII formats, such as Base64, hexadecimal, or binary. And you can use the ‘urllib’ module to convert string data between URL and plain text formats, such as URL encoding, URL decoding, or URL parsing.
However, encoding and decoding string data in Python can also encounter errors and exceptions, such as UnicodeError, ValueError, or TypeError. These errors and exceptions may occur when the string data is not valid, compatible, or supported by the encoding or decoding method. For example, you may get a UnicodeError if you try to encode a string data that contains characters that are not in the ASCII range. Or, you may get a ValueError if you try to decode a string data that is not a valid Base64 format. And you may get a TypeError if you try to encode or decode a data type that is not a string, such as an integer or a list.
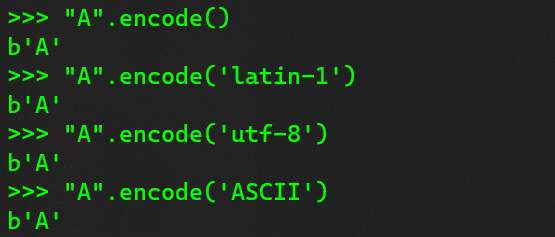
Python uses UTF-8 encoding as the default method for the encode() function. In the example given in Figure 1, we try to encode the string A using different encoding methods in Python. We use the encode() function with the name of the encoding method as the argument. As you can see, there is no difference in the output for the string A, as it is a common character that can be represented by the same byte in all the methods. However, this may not be the case for other characters, such as symbols, emojis, or foreign languages.
To understand encoding method differences, let’s examine how they represent characters using bytes. A byte is a unit of data that consists of 8 bits, each of which can have a value of 0 or 1. Different encoding methods use different combinations of bits to map characters to bytes, depending on the range and the standard of the method. ASCII is one of the oldest and simplest encoding methods, which uses 7 bits to represent 128 characters, such as letters, numbers, punctuation marks, and control codes. ASCII is a signed method, which means that the first bit is reserved for indicating the sign of the byte, either positive or negative. Therefore, ASCII can only use the remaining 7 bits to encode characters, which limits its range to 2^7 = 128 characters. ASCII can’t encode characters beyond this range, such as symbols, emojis, or foreign languages.
UTF-8, an advanced universal encoding method, uses variable-length bytes to represent over a million characters from different languages and scripts. It is an unsigned method, which means that it does not use the first bit for the sign of the byte, but for indicating the length of the byte. Therefore, UTF-8 can use all 8 bits to encode characters, which increases its range to 2^8 = 256 characters for a single byte. However, UTF-8 can also use more than one byte to encode characters that require more bits, such as two bytes for 2^16 = 65,536 characters, three bytes for 2^24 = 16,777,216 characters, or four bytes for 2^32 = 4,294,967,296 characters.
Latin-1, also known as ISO-8859-1, is another encoding method. It uses 8 bits to represent 256 characters, mostly from Western European languages, such as French, German, or Spanish. Latin-1 is also an unsigned method, which means that it can use all 8 bits to encode characters, which gives it the same range as UTF-8 for a single byte. However, Latin-1 does not use variable-length bytes, which means that it cannot encode characters that require more than 8 bits, such as Chinese, Arabic, or Hindi. Latin-1 is also not compatible with UTF-8. This may cause errors or corruption when converting between the two methods.
In Figure 2, we can see some characters differing in their representations in UTF-8 and Latin-1, with the latter having a much greater scope. Hence, not all encodings give the same bytes.

While Latin-1 consists of most of the characters, another encoding form called Base64 allows you to encode images, files and other media into bytes. Base64 decoding works by reversing the encoding process. It converts the encoded text string into groups of 4 characters, each of which corresponds to one of the 64 values in the Base64 alphabet. These values are then converted back to 6 bits, and the resulting bits are concatenated to form the original binary data.
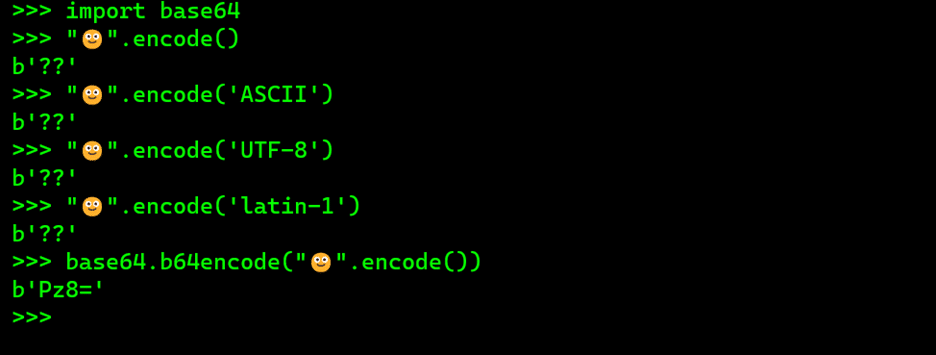
In Python, Base64 is used to convert encoded string into Base64 bytes. This means that characters unable to be represented by encoding methods like ASCII, Latin-1 and UTF-8 get shown as ‘??’ but get a valid meaning once encoded with Base64. In this way, as shown in Figure 3, emojis, images, files and string are converted into the binary for the computer to understand.













