





























































There are a myriad of PDF utilities, each with its own idiosyncrasies. This article combines several of them and provides just the right syntax to get you going without any delay.
In the January 2023 edition of OSFY, I wrote an article on how to programmatically create HTML, ODT, DOCX and PDF files. In this article, I focus on PDF so that you can use it as a barebones ready-reference for your oft-required PDF-processing tasks.
Here are some PDF Tricks:
Creating PDFs from scratch
Old MarkDown is passé. CommonMark is the new standard, or rather, it is standardised MarkDown. If you prefer MarkDown, then you have to use its slow Perl script. If you can use CommonMark, then get the executable from my website. I built it from its C source code, and it is blisteringly fast.
# Convert MarkDown to HTML perl markdown.pl jokebook.md > content.htm # or cmark --unsafe --validate-utf8 \ jokebook.md > content.htm # Place the converted HTML in a HTML template echo ‘<!DOCTYPE html><html><title>2020 Jokebook</title></head><body>’ > jokebook.htm cat content.htm >> jokebook.htm echo ‘</body></html>’ >> jokebook.htm # Embed images in the HTML libreoffice \ --convert-to “html:HTML:EmbedImages” \ jokebook.htm # creates jokebook.html with self-contained # (base64-encoded) images # Convert HTML to ODF libreoffice --convert-to “odt” jokebook.html # creates jokebook.odt # Convert ODF to PDF libreoffice --convert-to “pdf” jokebook.odt # creates jokebook.pdf
Converting images to PDF
Sometimes, you have to create PDF pages from images. ImageMagick is the preferred Linux utility to convert images.
# Convert images to PDFs magick front-cover.png -resize 100% front.pdf magick back-cover.png -resize 100% back.pdf
Concatenating several PDFs
PDFtk is a powerful PDF-processing utility that can perform tasks such as merging, splitting, encrypting, decrypting, stamping, and watermarking.
# Concatenate several PDFs pdftk front.pdf inner-pages.pdf back.pdf \ output book.pdf
Encrypting PDFs
PDF documents can be encrypted using two passwords — owner and user.
pdftk book.pdf output book-encrypted.pdf \ encrypt_128bit \ owner_pw RcHrDsTlMn^012 \ user_pw FrSfTWrFnDtn^321
If you set an empty user password, you can let users view the PDF without a password prompt. You can specify additional restrictions using the ‘allow’ option. Possible values are Printing, DegradedPrinting, ModifyContents, Assembly, CopyContents, ScreenReaders, ModifyAnnotations, FillIn and AllFeatures. If you do not specify the allow option, none of these features will be available. Well, the PDF standard specifies that these features should not be available. In reality, the restrictions are not strictly implemented by many PDF viewer applications.
Removing PDF password
Use the input_pw option to specify the password.
pdftk book-encrypted.pdf \ input_pw RcHrDsTlMn^012 \ output book-decrypted.pdf
If you start this command with a space, then the password (RcHrDsTlMn^012) will not be stored in the ‘bash’ shell history. Another trick is to use an interactive dialog.
sPassword=$(zenity --password \ --title “Decrypt PDF” \ --text “Type the password”) pdftk book-encrypted.pdf \ input_pw $sPassword \ output book-decrypted.pdf
If you want a console-only prompt, then disable the input echo.
stty -echo read -p “Type the password: “ sPassword stty echo
Converting PDF pages to images
You can use the pdftoppm utility to convert PDF pages to images in JPEG and PNG format. You can also specify the pixel density and page range.
# Export pages 2 to 12 with 96 dpi pdftoppm -png -r 96 -f 2 -l 12 book.pdf page # creates numbered images with prefix ‘page’
Rasterising a PDF
Sometimes, you cannot give a PDF as is to someone else or put it online. To foil content scrapers (and since ‘AI’ is now an unabashed content scraper), it is best to convert even the text to JPEG images. Why JPEG? Because it is lossy.
pdftoppm -jpeg -r 96 book.pdf page magick page*.jpg book-rasterized.pdf
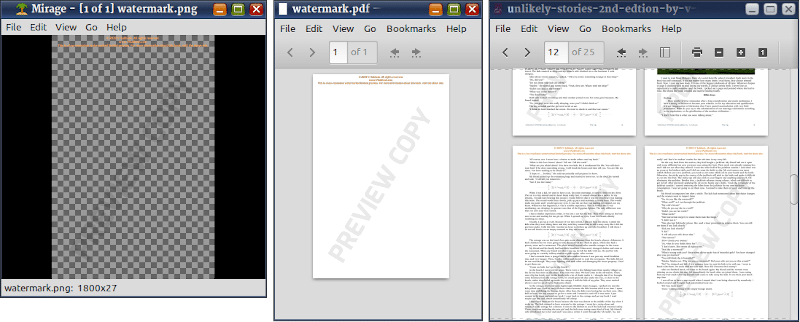
Some content scrapers do have the ability to read text from images, but that task requires extra resources. If you set the DPI to 72, it gets more demanding. For further annoyance, stamp it or watermark it.
magick watermark.png watermark.pdf pdftk book-rasterized.pdf \ stamp watermark.pdf \ output pages-watermarked.pdf
Converting PDF to DjVu
Many PDF books on Archive.org are scanned from library copies of physical books. These PDFs are extremely heavy as the scans are usually dense or big images. Ordinary PDF readers on tablets struggle to read such PDFs. My solution is to convert the PDFs to DjVu. (DjVu viewer applications are optimised for reading from images. They load DjVu pages in a snap.)
pdf2djvu --dpi=220 \ --output=tablet.djvu \ library.pdf
Depending on the page size in the PDF, you will have to adjust DPI with the —dpi option.
Splitting PDFs
There is no ‘pdftk’ option to remove pages. However, you can use its ‘cat’ option and specify pages that need to be left in the output document.
pdftk book.pdf cat 6-end \ output story.pdf # eliminates pages 1 to 5
pdftk does have a burst option to convert each page into a separate PDF.
pdftk book.pdf burst \ output page%02d.pdf
Specify the format mask of the page number in the output PDF name, similar to how you display numbers with the printf function of C standard library.
Other tasks
pdftk can do a lot of other tasks. Just consult its help output. While it can add and extract file attachments to and from a PDF, respectively, do remember that if you send a PDF with a file attachment by email, mail servers will pre-emptively remove your mail from the inbox of the recipient.














