




























































Web scripting helps to retrieve and analyse data from a website efficiently. In this comprehensive guide to web scraping with Python web scripting, you will learn about how to use the requests and BeautifulSoup libraries to do so.
With the rise of web-based services, it has become mandatory for us to orient ourselves to as many of them as possible — from social networking sites to daily utilities and financial services. As these web services have become rich and reliable sources of information, businesses are using them for their analytical exercises. Web scripting is playing a critical role in web scraping. This is an essential programming technology to analyse a web page and is used to obtain information from the websites. Retrieving data from a reliable website is a common exercise for many establishments. Copying, pasting, or downloading are not practical solutions for such a job. Moreover, sometimes it becomes mandatory to process that information at regular intervals for data analysis. Web scripting is required in these circumstances, to process and analyse that data efficiently.
One industry that extensively uses scrapped data is social media marketing. Companies in this space scrape and extract data from numerous websites to understand user sentiments, current trends/affairs, news, and feedback. This information helps to create effective marketing campaigns and business strategies.
In this article, we will explore how to perform web scraping using the requests library and the BeautifulSoup library of Python.
Python as a web scraper
A Python web scraper is a software or script to download the contents of multiple web pages and extract data from them. The functioning of a web scraper is shown in Figure 2.
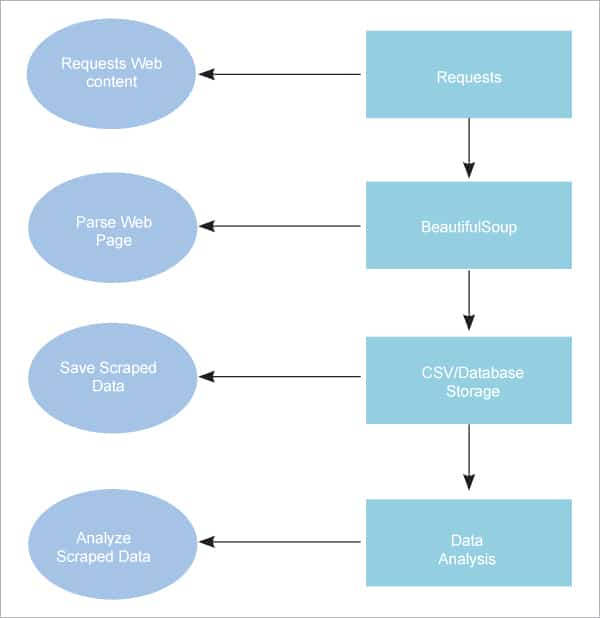
Step 1: Downloading contents from web pages
In this step, a web scraper reads the requested page from a URL.
Step 2: Extracting data
Then the web scraper parses and extracts structured data from the requested contents.
Step 3: Storing the data
Subsequently, the web scraper stores the extracted data in CSV, JSON, or a database.
Step 4: Analysing the data
From these well-established formats, the web scraper initiates analysis of the stored data.
Web scraping of Python can be initiated with two simple library modules — requests and BeautifulSoup. In this article, we will demonstrate their functions as well as Python web scripting, with a few illustrations to help you understand the basics of web scraping.
request module
Making HTTP requests and receiving responses are done with the help of the requests library. The management of the request and response is handled by built-in functionality in Python requests. Since this module is not shipped with core Python it is necessary to install it with pip separately.
pip install requests |
Making a GET request
The Python requests module comes with some built-in ways to send GET, POST, PUT, PATCH, or HEAD requests to a given URI. An HTTP request may send data to a server or get it from a specified URI. It functions as a client-server request-response protocol. Information is retrieved from the specified server using the GET method and the given URI. The user data is encoded and added to the page request before being sent via the GET method.
import requests# Making a GET request in Pythonr = requests.get(‘https://www.tutorialspoint.com/python-for-beginners-python-3/index.asp’)# check the status code for the response received# success code - 200print(r.status_code)#print headerprint(r.headers) |
The output is:
200{‘Content-Encoding’: ‘gzip’, ‘Accept-Ranges’: ‘bytes’, ‘Access-Control-Allow-Credentials’: ‘true’, ‘Access-Control-Allow-Headers’: ‘X-Requested-With, Content-Type, Origin, Cache-Control, Pragma, Authorization, Accept, Accept-Encoding’, ‘Access-Control-Allow-Methods’: ‘GET, POST, PUT, PATCH, DELETE, OPTIONS’, ‘Access-Control-Allow-Origin’: ‘*, *;’, ‘Access-Control-Max-Age’: ‘1000’, ‘Age’: ‘515359’, ‘Cache-Control’: ‘max-age=2592000’, ‘Content-Type’: ‘text/html; charset=UTF-8’, ‘Date’: ‘Thu, 25 May 2023 08:05:00 GMT’, ‘Expires’: ‘Sat, 24 Jun 2023 08:05:00 GMT’,Modified’: ‘Fri, 19 May 2023 08:55:43 GMT’, ‘Server’: ‘ECAcc (blr/D141)’, ‘Vary’: ‘Accept-Encoding’, ‘X-Cache’: ‘HIT’, ‘X-Frame-Options’: ‘SAMEORIGIN, SAMEORIGIN’, ‘X-Version’: ‘OCT-10 V1’, ‘X-XSS-Protection’: ‘1; mode=block’, ‘Content-Length’: ‘14119’} |
The response ‘r’ is a powerful object with a plethora of methods and features that aid in normalising data or offer the finest code. For instance, one may assess whether or not the request was correctly processed using the status code provided by r.status_code and r.header.
BeautifulSoup library
The BeautifulSoup module is used to extract information from the HTML and XML files. It offers a parse tree together with tools for exploring, searching, and updating it. It generates a parse tree from the page’s source code, which is used to organise data more logically and hierarchically.
The purpose of this module is to perform rapid reversing tasks like screen scraping. It is effective due to three aspects.
1. It provides some simple and minimal codes for analysing a text and extracting the required items from the text. It provides facilities for directing, finding, and altering a parse tree.
2. It automatically converts outputs to UTF-8 and receives records at Unicode.
3. Parsers like LXML and HTML are often used to experiment with various parsing strategies or execution performances for flexibility.
pip install beautifulsoup4 |
Since this module is not also shipped with core Python it is necessary to install it with pip separately.
Examining the target website
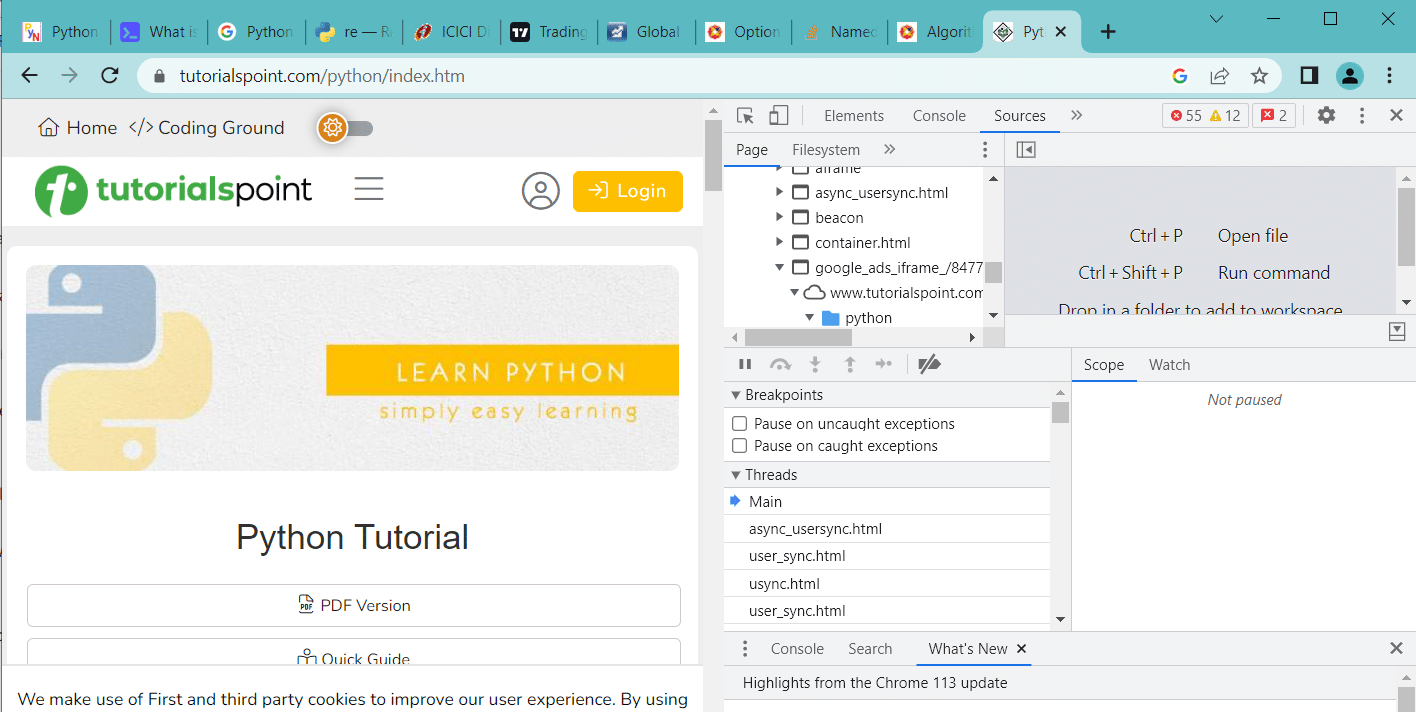
Inspecting the target website is required before developing a scripting program. One can do this by right-clicking on the target page and selecting Developer tools.
After clicking the Developer tools button of the open browser, one can inspect the internal codes of the open web page. We shall consider Chrome as the browser for this article.
The developer’s tools allow a view of the site’s document object model (DOM). From the display, one can examine the structure of the HTML coding of the page.
Parsing the HTML
After examining the scripting of the page, one can parse the raw HTML code into some useful information. For that, it’s necessary to create a BeautifulSoup object by specifying the required parser. As this module is built on top of the HTML parsing libraries like html5lib, lxml, and html.parser, etc, all these libraries can be called along with this module. With this module, it’s possible to parse a requested web page into its original HTML page. Here is an example:
import requestsfrom bs4 import BeautifulSoup# GET requestr = requests.get(‘https://flask-bulma-css.appseed.us/’)# check the status code for the response receivedprint(r.status_code)# Parsing the HTMLhtmlObj = BeautifulSoup(r.content, ‘html.parser’)print(htmlObj.prettify()) |
The output is:
200<!DOCTYPE html><html lang=”en”><head><!-- Required meta tags always come first --><meta charset=”utf-8”/><meta content=”width=device-width, initial-scale=1, shrink-to-fit=no” name=”viewport”/><meta content=”ie=edge” http-equiv=”x-ua-compatible”/><title>Flask Bulma CSS - BulmaPlay Open-Source App | AppSeed App Generator |
For further analysis, it’s possible to item-wise parse the HTML page into different parent and child classes.
import requestsfrom bs4 import BeautifulSoup# Making a GET requestr = requests.get(‘https://flask-bulma-css.appseed.us/’)# Parsing the HTMLhtmlobj = BeautifulSoup(r.content, ‘html.parser’)# Getting the title tagprint(htmlobj.title)# Getting the name of the tagprint(htmlobj.title.name)# Getting the name of parent tagprint(htmlobj.title.parent.name)# use the child attribute to get# The name of the child tagprint(htmlobj.title.children.__class__) |
The output is:
<title>Python Tutorial | Learn Python Programming</title>titlehead<class ‘list_iterator’> |
Finding HTML page elements
Now, we want to extract some valuable information from the HTML text. The retrieved content in the htmlobj object may contain some nested structures. From these nested structures, different HTML elements can be parsed to retrieve valuable information from the web page.
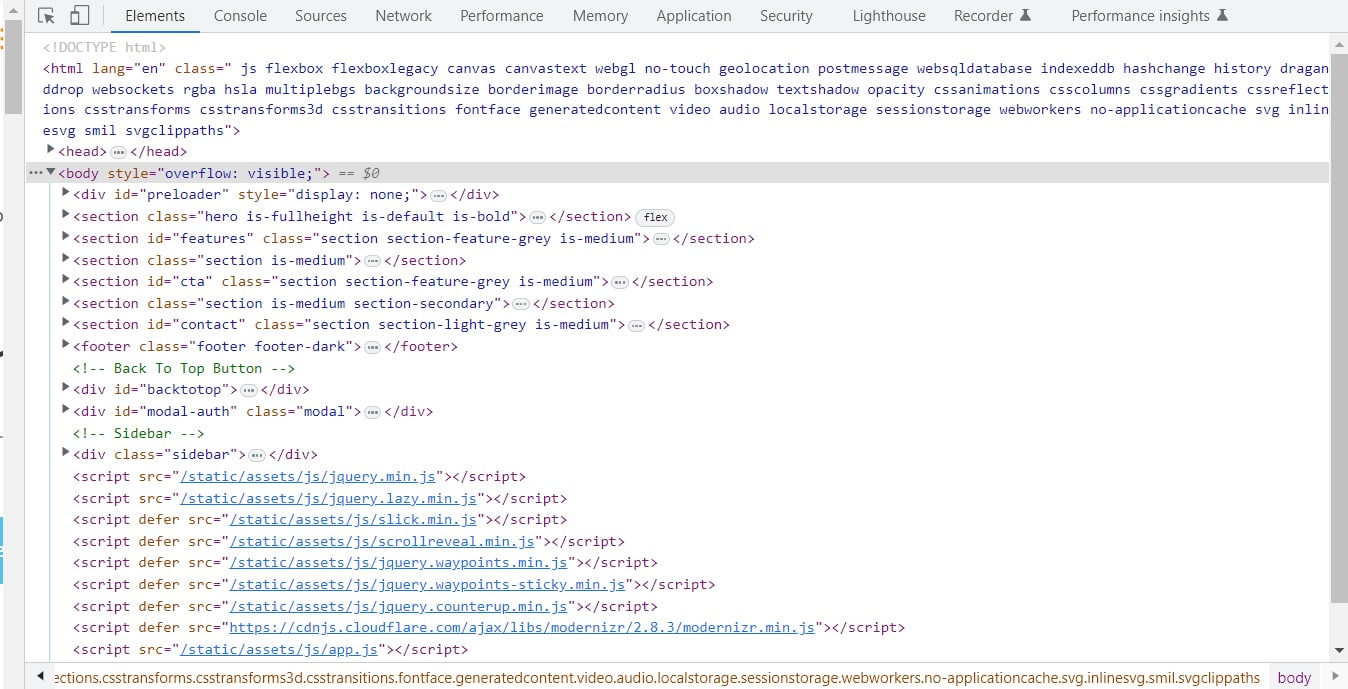
HTML element search by class
We can see in Figure 4 that there is a div tag with the class tag entry. The found class method can be used to locate the tags. This class searches for the specified tag with the specified property. In this instance, it will locate every div with the class entry content. Although we have all of the website’s information, you can see that all the elements other than the <a> have been eliminated.
import requestsfrom bs4 import BeautifulSoup# Making a GET requestr = requests.get(‘https://flask-bulma-css.appseed.us/’)# Parsing the HTMLhtmlobj = BeautifulSoup(r.content, ‘html.parser’)s = htmlobj.find(‘div’, class_=”sidebar”)content = s.find_all(“a”)print(content) |
The output is:
[<a class=”sidebar-close” href=”javascript:void(0);”><i data-feather=”x”></i></a>, <a href=”#”><span class=”fafa-info-circle”></span>About</a>,<a href=”https://github.com/app-generator/flask-bulma-css” target=”_blank”>Sources</a>, <a href=”https://blog.appseed.us/bulmaplay-built-with-flask-and-bulma-css/” target=”_blank”>Blog Article</a>, <a href=”#”><span class=”fa fa-cog”></span>Support</a>, <a href=”https://discord.gg/fZC6hup” target=”_blank”>Discord</a>, <a href=”https://appseed.us/support” target=”_blank”>AppSeed</a>] |
Identification of HTML elements
In the example above, we identified the components using the class name; now, let’s look at how to identify items using their IDs. Let’s begin this process by parsing the page’s cloned-navbar-menu content. Examine the website to determine the tag of the ‘cloned-navbar-menu’. Then, finally, search all the path tags under the tag <a>.
import requestsfrom bs4 import BeautifulSoup# Making a GET requestr = requests.get(‘https://flask-bulma-css.appseed.us/’)# Parsing the HTMLhtmlObj = BeautifulSoup(r.content, ‘html.parser’)# Finding by ids = htmlObj.find(‘div’, id=”cloned-navbar-menu”)# Getting the “cloned-navbar-menu”a = s.find(‘a’ , class_=”navbar-item is-hidden-mobile”)# All the paths under the above <a>content = a.find_all(‘path’)print(content)[<path class=”path1” d=”M 300 400 L 700 400 C 900 400 900 750 600 850 A 400 400 0 0 1 200 200 L 800 800”></path>, <path class=”path2” d=”M 300 500 L 700 500”></path>, <path class=”path3” d=”M 700 600 L 300 600 C 100600 100 200 400 150 A 400 380 0 1 1 200 800 L 800 200”></path>] |
Iterating over a list of multiple URLs
To scrape many sites, each of the URLs need to be scraped individually, and it is required to hand-code a script for each such web page.
Simply create a list of these URLs and loop over it. It is not required to create code for each page to extract the titles of those pages; instead, just iterate over the list’s components. You may achieve that by following the example code provided here.
import requestsfrom bs4 import BeautifulSoup as bsURL = [‘https://www.researchgate.net’, ‘https://www.linkedin.com’]for url in range(1,2):req = requests.get(URL[url])htmlObj = bs(req.text, ‘html.parser’)titles = htmlObj.find_all(‘titles’,attrs={‘class’,’head’})if titles:for i in range(1,7):if url+1 > 1:print(titles[i].text)else:print(titles[i].text) |
Storing web contents into a CSV file
After scraping the web pages, one can store the elements into a CSV file. Let’s consider the storing of a tag-value dictionary list in a CSV file. The dictionary elements will be written to a CSV file using the CSV module. Check out the example below for a better understanding.
Example: Saving data from Python’s BeautifulSoup to a CSV file:
import reimport requestsfrom bs4 import BeautifulSoup as bsimport csv# Making a GET requestr = requests.get(‘https://flask-bulma-css.appseed.us/’)# Parsing the HTMLhtmlObj = bs(r.content, ‘html.parser’)# Finding by ids = htmlObj.find(‘div’, id=”cloned-navbar-menu”)# Getting the leftbara = s.find(‘a’ , class_=”navbar-item is-hidden-mobile”)# All the li under the above ulcontent = a.find_all(‘path’)lst = []for i in range(3): dict = {} s = str(content[i]) dict[‘path_name’] = re.search(‘class=”path[1-3]”’, s) dict[‘path_value’] = re.search(‘d=.*>$’, s) lst.append(dict)filename = ‘page.csv’with open(filename, ‘w’, newline=’’) as f: w = csv.DictWriter(f,[‘path_name’,’path_value’]) w.writeheader() w.writerows(lst)f.close() |
The output CSV file is given below.
|
|
||
|
|
||
|
|
||
|
|
Web scraping with Python web scripting is a powerful tool for web data analysis. Here we have mentioned a few useful requests and BeautifulSoup library methods. Hope you will find the information useful and start your journey into this prevailing technology for data analytics of web information.











