




























































Teradata is one of the most popular relational database management systems (RDBMS) appropriate for huge data warehousing applications. It is highly scalable and capable of handling large volumes of data. This article provides a basic understanding of Teradata architecture, and the types of spaces and tables it has.
As per official Teradata documentation: “Teradata database is a massively parallel analytics engine that can help businesses achieve breakthrough results across all industries. Whether companies need to improve profitability, mitigate risks, innovate products, enhance the customer experience, or achieve other objectives, analytics paves the way to success.”
Teradata architecture
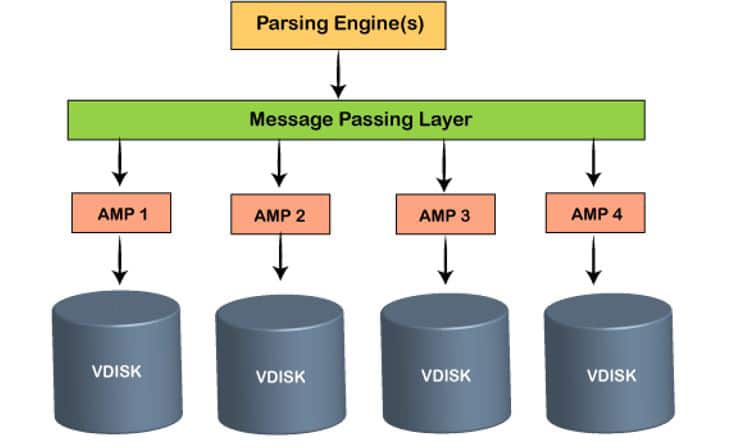
Node: This is an essential building block of the Teradata database system and is made up of hardware and software components. A server can also be considered as a node.
PE (parsing engine): This is a type of vproc (virtual processor) for session control, task dispatching and SQL parsing in the multi-tasking and possibly parallel-processing environment of the Teradata database. Vproc is a software process running in an SMP (symmetric multiprocessing) environment or a node. The vproc or the access module processor (AMP) are responsible for storing and retrieving data.
The different components of a parsing engine are listed below.
- Parser: This decomposes SQL queries into relational data management processing steps.
- Query optimizer: This determines the most efficient path to access data.
- Step generator: This produces processing steps and encapsulates them into packages.
- Dispatcher: This transmits the encapsulated steps from the parser to the relevant AMPs, and performs monitoring and error-handling functionalities during step processing.
- Session controller: This manipulates session-control activities (e.g., log on, log off and authentication) and restores a session only after client or server failures.
Message passing layer: This is also called BYNET (Banyan network), and is the networking layer in the Teradata system. It allows interaction between PE and AMP, and also between the nodes. It receives the execution plan from the PE and sends it to AMP. Similarly, it receives the outputs from the AMP and sends them to PE. In the Teradata system, there are always two BYNET systems. These are called BYNET 0 and BYNET 1. But this is generally referred to as a single BYNET system. If one BYNET fails, the second one takes its place. But when data is large, both BYNETs can be made functional, which enhances the communication between PE and AMPs.
Disk: This component organises and stores the data while performing data manipulation activities. Teradata database employs redundant array of independent disks (RAID) storage technology to provide data security at the disk level. When AMPs are associated with disks, it is called Vdisks (virtual disks).
| Note: Each AMP is allowed to read and write on its own disk only. That is why it is also called shared-nothing architecture. |
Teradata acts as a single data store that receives a large number of concurrent requests from various client applications. It is defined as an information repository supported by tools and utilities that make it, as part of Teradata Warehouse, a complete and active RDBMS.
Types of spaces in Teradata
Permanent space: This is the maximum amount of space allocated to the user/database to hold data rows. It is used for database objects (like permanent tables, indexes, etc) creation, and to hold their data. The total permanent space is divided among the total number of AMPs. Whenever the per AMP limit exceeds the allocated space of AMP, a ‘No more room in database’ error is generated. Permanent tables, journals, fallback tables, and secondary index sub-tables use permanent space. All databases have a predefined upper limit of permanent space. Teradata doesn’t physically preallocate permanent space for databases and users when they are defined during object definition time.
Spool space: This is the unused permanent space that is used by the system to keep the intermediate results of the SQL query. Once the query is complete, the spool space is released. The volatile tables use the spool space. Users without spool space can’t execute any query. Data is active up to the current session only. It is divided among the number of AMPs. Whenever the per AMP limit exceeds the allocated space, the user will get a spool space error.
Temporary space: This is the unused permanent space used by global temporary tables (GTT). It is divided by the number of AMPs. Data is active up to the current session only. It is reserved prior to spool space for any user defined operations. Temp space is allocated at the database level or user level, but not at the table level. This is the amount of space used for GTT, and these results remain available to the user until the session is terminated.
Tables created in temp space will survive a restart. A query example is given below:
CREATE DATABASE new_db FROM existing_dbAS PERMANENT = 2000000, SPOOL = 5000000, TEMP = 2000000; |
A new database must be created from an existing database.
Permanent space can be used for tables in the database. Spool space is allocated for the maximum amount of workspace available for requests. Temp space is allocated for temp tables in the database.
Types of tables in Teradata
Permanent tables: These remain in the system until they are dropped. The table definition is stored in the data dictionary. Data and structure can be shared across multiple sessions and users. Data is stored in the permanent space, and ‘collect statistics’ is supported. Indexes can be created. COMPRESS columns, as well as DEFAULT and TITLE clauses are supported. Partition primary index (PPI) is also supported. If the primary index clause is not defined in the ‘Create table’ statement, then Teradata will create the first column as primary by default.
Global temporary tables (GTT): This is a kind of temporary table. The table definition is stored in the data dictionary. It requires a minimum of 512 bytes from the permanent space to store table definitions in the data dictionary. The structure can be shared across multiple users but data will remain private to the session (and its user). Data is stored in the temporary space. Data will be purged for that session once the session ends. ‘Collect statistics’ is supported. Indexes can be created. COMPRESS columns, as well as DEFAULT and TITLE clauses are supported. PPI is also supported.
This table can be identified from the data dictionary table (dbc.tables) using the ‘CommitOpt’ column. If its value is ‘D’ (on commit Delete rows) or ‘P’ (on commit Preserve rows), then it’s a GTT. If the primary index clause is not specified while creating the table, then Teradata will create the first column as primary by default. One session can generate up to 2000 global temporary tables at a time.
Volatile tables: These are created in the spool space for temporary use, and their life span extends for the duration of the session only. The table definition is not stored in the data dictionary. Structure and data is private to the session and its user. Data is stored in the spool space. The table gets dropped once the session ends, i.e., when ‘login again…no volatile tables’ shows up. ‘Collect statistics’ is supported. Indexes cannot be created. The COMPRESS column is supported, but the DEFAULT and TITLE clauses are not supported. PPI is supported. If the primary index clause is not specified while creating the table, then Teradata will create the first column as primary by default.
ON COMIT DELETE ROWS (Default)ON COMIT PRESERVE ROWS (If we want to retain rows) |
Derived tables: This temporary table is derived from one or more other tables as the result of a sub-query. Derived tables are local to the query and exist only for the duration of the query. The table is automatically deleted once the query is done. Data is stored in the spool space. Table definition is not stored in the data dictionary. The first column in a derived table acts like a PI column for it.
Properties of Teradata tables
- Fallback: This protects data by storing a second copy of each row of a table on a different AMP in the same cluster. If an AMP fails, the system accesses the fallback rows to meet requests.
- Journals: BEFORE JOURNAL holds the image of impacted rows before any changes are made. AFTER JOURNAL holds the image of affected rows after changes are done. In DUAL BEFORE/AFTER JOURNAL, two images are taken and are stored in two separate AMPs.
- Checksum: This detects some forms of lost writes. A lost write is a write of a file system block that received successful status on completion, but the write either never actually occurred or was written to an incorrect location. As a result, subsequent reads of the same block return the old data. NONE, LOW, MEDIUM, and HIGH levels are available in the checksum.
Teradata is a powerful RDBMS and can help in transforming how businesses work. We have just discussed its basics in this article and a lot still needs to be unearthed. We hope you find this basic information useful to explore the features and capabilities of Teradata further.













