





























































Much thought from the finest brains all over the world has gone into the making of Unicode. Its main purpose is to serve all mankind. If you are a developer, do not make the mistake of ignoring this encoding standard.
Some things that nobody teaches us are learnt the hard way. Did your computer course teach you to acquire resources as late as possible and release them early? Did any programming book tell you that software should not be developed using Visual Studio while it is running with administrator privileges? Every developer goes through the process of learning new and best-practices while unlearning old and die-hard ones. If you haven’t read the article titled, The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!) written in 2003 by Joel Spolsky (co-founder of StackOverFlow.com) , I suggest you read it before writing another line of code.
Unicode
Unicode is a unified text scheme for representing characters of over 150 languages, the list of which also includes Braille, sign language, Esperanto, musical notations, hieroglyphs, cuneiform, chemical symbols, emoticons and dingbats. Microsoft had a big font named Arial Unicode MS that was supposed to support all of Unicode. However, the tech giant gave that up, once Unicode continued to grow.
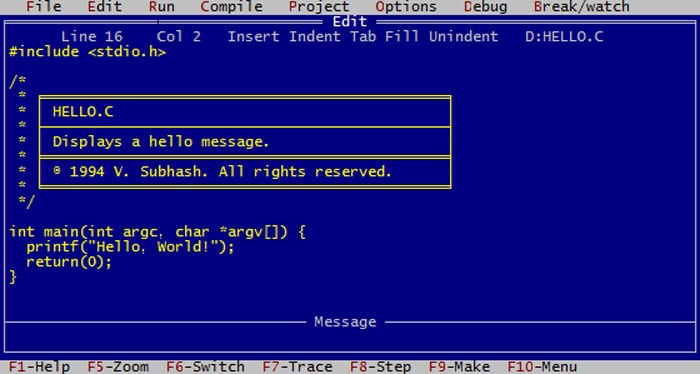
When learning programming for the first time with a language such as C, it is easy to assume that a character is the same as a byte or that a byte comprises only 8-bits. If your computer course rushed through such details, please run through and spend some time on the basics from a proper C language book. Spolsky’s article mentions how the creators of PHP initially wrote the Web scripting language without support for Unicode!
ASCII
Unicode represents a paradigm shift from the days when boxes were drawn in the headers of C code using characters in the extended ASCII set (128 extra codes added to the 128-code ASCII). It is better than traditional ASCII art even today.
In Unicode, the box-drawing characters (⊢ ⊣ ⊤ ⊥ ⊦ ⊧ ⊨ ⊩ ⊪ ⊫ ═ ║ ╒ ╓ ╔ ╕ ╖ ╗ ╘ ╙ ╚ ╛ ╜ ╝ ╞ ╟ ╠ ╡ ╢ ╣ ╤ ╥ ╦ ╧ ╨ ╩ ╪ ╫ ╬) were moved further up into the stratosphere.
In the early days of computing, I worked primarily on DOS. Windows was a GUI program that ran on it. On a DOS keyboard, you could type the copyright symbol (©) by holding down the Alt key and typing 0169 on the numeric keypad. On lab computers that did not have floppy drives, I created undeletable directories in the hard disk by suffixing the directory names with an undetectable space symbol (Alt+255). A more subversive trick was to use memory utilities and change the name of a directory to ‘CON’ in the file allocation table (FAT). Windows, too, would not allow you to touch a file or directory named CON because it was a reserved file descriptor for the console in DOS. For many years, Linux would let you create a directory named CON in a Windows partition if you wanted to. But that was fixed later.
HTML entity references
When I started learning HTML, I found that the copyright symbol could be written as ©. The registered symbol (®) could be written as ® and Trademark symbol (™) could be written as &trade. HTML has several such character entity references. However, any character can be written using its Unicode codepoint, which is known as a numeric entity reference. For the copyright symbol, this is ©. It can also be written as © with the x signifying that the codepoint is hexadecimal. Similarly, the numeric entity reference for the registered symbol is written as ® or as ®.
Source code file encoding
If your OS is Windows, then it is likely that you save all your source code files in the default Windows encoding Latin-1 or Western European. These do not work well with non-English Unicode strings. (Ideally, you should be storing all UI strings in a resource file so that file encoding is never a problem.) However, for maximum resilience and portability, save all your source files in UTF-8 encoding. If your file turns into gibberish, you need to first select everything in the file to the system clipboard (Ctrl+A and Ctrl+C), then change the encoding, and finally do a paste (Ctrl+V). If your editor allows you to change the encoding in the ‘Save as’ dialog box, then paste the text after saving the file. With UTF-8 encoding, you will eliminate a whole heap of trouble.
HTML forms
If you have a Web script that outputs HTML to a browser, then let the browser know the encoding of the output stream. In PHP, the first line could be:
<?php header(‘Content-type: text/html; charset=utf-8’); ?>
This is not enough. In the HTML, declare the encoding as early as possible:
<!DOCTYPE html> <html> <head> <meta http-equiv=”Content-Type” content=”text/html; charset=UTF-8” /> <title>This page is Unicode-encoded</title> …
This is particularly important if you have HTML forms where you accept text data. If your HTML page is not Unicode-encoded or if the server-side script is not saved with Unicode encoding, then you may not always be able to correctly process non-English text input.
Fonts
Despite the above, if you still get the dreaded question marks or boxy characters, it means you do not have the font to render the non-English text. The Unicode project only specifies numbered codepoints for its characters. The actual visual representation of the characters is left to the font engine and fonts installed in the output device. For example, in the Malayalam letter ‘Shree’, there are four Unicode characters — ശ (0D36),◌് (0D4D), ര (OD30), and ീ (OD40). A font that supports Malayalam decides how to combine them as . You will not find the finally rendered ligature in Unicode. If you move the cursor across the letter, you will be able to split it into two ligatures and . Even these will not be found in Unicode. How they are formed is left to the font maker.
You will have to view a ligature in a hex editor to identify the individual codepoints. Then, you can search the codepoints in the Unicode list. That will tell you what language the character belongs to. You can then install a font that supports that language.
The full character list is published on the Unicode website at http://ftp.unicode.org/Public/UNIDATA/UnicodeData.txt. This file tips the scale at nearly 2MB. It is in the form of a comma-separated file (CSV). With some JavaScript (http://www.vsubhash.in/refs/unicode.html), you can render it as a table. (The following code will tax the JavaScript and HTML engines of a browser. Do not run it on a system that is light on resources.)
<!doctype html>
<html>
<head>
<meta http-equiv=”Content-Type” content=”text/html; charset=UTF-8” />
<link href=”universal.css” rel=”stylesheet”>
<script>
// Make a copy of the Unicode data text file in the
// directory of this HTML file.
var sUnicodeURL = “UnicodeData.txt”;
var sUnicode=””;
var oXhr = new XMLHttpRequest();
oXhr.addEventListener(“load”, function() {
sUnicode = oXhr.responseText;
processUnicode();
});
oXhr.open(“GET”, sUnicodeURL);
oXhr.send();
function processUnicode() {
var arLines = sUnicode.split(‘\n’);
var n = arLines.length-6;
console.log(“Lines = “ + n);
var oTable = document.getElementById(“tbl_unicode”);
var sTableHTML = “<tr><th style=\”width: 6em; \”>Codepoint</th><th style=\”width: 6em; \”>Hexadecimal</th><th>Description</th></tr>”;
for (var i = 0; i < n; i++) {
var arUnicodeData = arLines[i].split(‘;’);
var sDescription = “”;
var sCode = arUnicodeData[0];
if (arUnicodeData[1] == “<control>”) {
sDescription = “Control Character”;
} else {
sDescription = “”;
}
if (arUnicodeData[10]) {
sDescription = sDescription + arUnicodeData[1] + ‘ (‘ + arUnicodeData[10] + ‘)’;
} else {
sDescription = sDescription + arUnicodeData[1];
}
sTableHTML = sTableHTML + “<tr><th>” + sCode + “;</th><td>” + sCode + “</td><td>” + sDescription + “</td></tr>”;
}
oTable.innerHTML = sTableHTML;
}
</script>
</head>
<body>
<table id=”tbl_unicode”>
</table>
</body>
</html>
This table is much easier to browse than the Character Map application in Linux.
With this table, I can easily write my name as V. Subhash in my email. This name stands out in any email inbox. However, the disadvantage is that no one will find it by searching for ‘V. Subhash’. (Disclosure: I learnt this from YouTube bootleggers, who use the technique to escape filters. Interestingly, You Tube search understands this technique.) With Unicode and without any images, my name can be written in different ways, as shown in Figure 4.
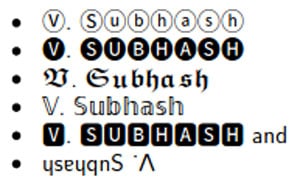
Of course, Windows is always late to the game and may not have full font support for such Unicode strings. Linux has no such problem.
Twitter has been blamed by many for ruining the Internet for them. (Twitter was one of the first to withdraw RSS feeds. Can you really blame it, though? Even Firefox has removed RSS support!) It was a surprise when Twitter created a free and open source emoticon-heavy font that anyone can download and use from https://github.com/twitter/twemoji.

Universal fonts style sheet
When you have a website, the text in the pages is displayed using the fonts on the end user’s device. The best approach is to use whatever fonts that are available. Ideally, merely mentioning serif, sans-serif and monospace in the CSS should be fine but browsers typically choose fonts from very ancient times for the default options. I suggest you use a universal font CSS (stylesheet) like this so that newer OS-optimised fonts are chosen instead.
body {
/* Order: Special,
* Android, iOS,
* Linux (Liberation, Free, DejaVu),
* Mac UI, Windows Vista UI, Windows XP UI,
* Mac Unicode fallback, Windows Unicode fallback,
* Adobe Standard Type 1, generic
*/
font-family: “CMU Sans Serif”,
“Roboto”, “San Francisco”, “Helvetica Neue”,
“Liberation Sans”, FreeSans, “DejaVu Sans”,
“Segoe UI”, Tahoma, “Lucida Sans Unicode”,
“Last Resort”, “Arial Unicode MS”,
Helvetica, sans-serif;
}
h1, h2, h3, h4, h5, h6 {
/* Order: Special,
* Android, iOS,
* Linux (Liberation, Free, DejaVu),
* Mac, Windows Vista Serif, Windows XP Serif,
* Windows Unicode fallback, Mac Unicode Fallback,
* Adobe Standard Type 1, generic;
*/
font-family: “CMU Serif”,
“Roboto Slab”,
“Liberation Serif”, “FreeSerif”, “DejaVu Serif”,
Times, Constantia, “Trebuchet MS”, “Times New Roman”,
“Lucida Sans Unicode”, “Arial Unicode MS”, “Last Resort”,
Roman, serif;
}
code {
/* Order: Special,
* Android, iOS,
* Linux (Liberation, Free, DejaVu),
* Mac, Vista, XP,
* Adobe Standard Type 1, generic
*/
font: normal 1em “Source Code Pro”,
“Roboto Mono”, Menlo,
“Liberation Mono”, FreeMono, “DejaVu Mono”,
Monaco, Consolas, “Lucida Console”, “Courier New”,
Courier, monospace;
}
The corporate control-freak approach is to use a proprietary font with a @font-face rule. (This approach forces the browser to redraw the text after the font file is downloaded.)
@font-face {
font-family: ‘CNN’;
font-style: normal;
font-weight: 400;
src: url(/fonts/cnn.ttf);
}
body { font-family: CNN, Helvetica, san-serif; }
The cheaper control-freak approach is to use an obscure font from the Google fonts CDN with a LINK HTML tag. (This CDN is actually very slow and forces the browser to redraw the text after a long delay. Until then, large sections of the page will appear blank. Do read my 2019 CodeProject article titled ‘How to Make Your Website Serve Pages Faster’ for more information.)
<head>
<link rel=”stylesheet” href=”https://fonts.googleapis.com/css?family=Gentium”>
<style>
body {
font-family: “Gentium”, Roman, serif;
}
</style>
</head>
The Linux Unicode way
In Windows, you can use Alt+number pad key combinations to type Unicode characters. In Linux, you need to first press Ctrl+Shift+U. The cursor will temporarily transform to an underlined u. Then, when you type the codepoint number and press the Enter key, the corresponding Unicode character will be inserted at the text cursor. To type the copyright symbol (©), you need to type Ctrl+Shift+U, a9, and then Enter. For the Indian rupee symbol (`), you need to type Ctrl+Shift+U, 20B9, and then Enter.
Linux offers an additional way of typing some characters using a ‘Compose’ key. This is a modifier key that is designated as such in the keyboard settings. On my computer, I have set the useless Windows key as its Compose key (Preferences » Keyboard » Layouts » Options » Compose key position » Left Win). Now, to type the copyright symbol, I type Windows+O (simultaneously) and then c (subsequently).
The trouble with space
In my first year of self-publishing (2020-21), I created 21 books. I wrote, edited, illustrated, designed and formatted them myself — all thanks to open source software. For every book, I built a PDF file for the paperback (using a shell script) and an EPUB file for the ebook (manually). I wrote the manuscript in the text-only CommonMark format. (This is a new standardised dialect of the old MarkDown format.) I used the CommonMark executable to convert the text manuscript to HTML. Then, I styled the HTML with some CSS. This stylised HTML was fed to KhtmlToPDF to create the paperback PDF file. (I used Calibre to create the ebook copy from the same HTML.) However, the PDF output had a few problems.
The current KhtmlToPDF was resurrected by an Indian from an almost-abandoned open source project. KhtmlToPDF uses a headless Firefox browser of considerable vintage. It prints (not displays) the input HTML page. (KhtmlToPDF provides plenty of options for controlling the pagination and writing auto text such as page numbers, headers and footers, before exporting the print output to PDF using iText.) The printing talents of the Firefox browser are good but not perfect. Randomly, the space after an italicised word would disappear. If I manually added an extra space, it would be too much and the blank space would stand out. Initially, a fix seemed hopeless. But then, Unicode came to my rescue.
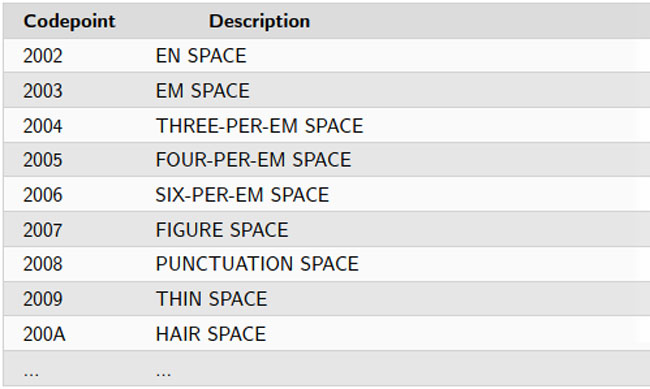
Unicode offers several types of space characters. There is space about the size of an ‘n’ — the en space, and also a space about the size of an ‘m’ — the em space, both of which may seem familiar if you know CSS. But, that is not all. I experimented with several other Unicode space characters and, eventually, I could hide KhtmlToPDF’s deficiencies.
In some places, the last letter in a line would be partially displayed. The fix for that was to use the non-breaking space character (Compose + Space + Space) after the word, and it would conveniently wrap to the next line. Sometimes, I did not want a line to break at a hyphen. Conveniently, Unicode has a non-breaking hyphen (Ctrl+Shift+u and 2011) as a fix.
That’s not all
You can already see that I am now addicted to the long hyphen (—) but you may not have noticed that instead of three dots (…), I have used an ellipsis (…). This is just one Unicode character, instead of three. I do not use apostrophes for my quotations. There are dedicated Unicode characters for it. I type them with the Compose key. I type ‘Hi’ instead of ‘Hi’. I write “Hello, World”, instead of ”Hello, World”. But, not when I write code. When other writers write source code in Microsoft Word, the annoying software autocorrects all apostrophes and double quotation marks into Unicode quotation marks. Such a code listing will not compile in an IDE. It becomes a nightmare for the person who does the page setting. My manuscripts (including the code listings) are entirely in text (as CommonMark). What is written in text, stays in text. So whether it is exported to HTML, Word or PDF, the code will always compile.














