

‘Linux Kernel Programming’ is targeted at people who are quite new to the world of Linux kernel development, and makes no assumptions regarding their knowledge of the kernel. The prerequisite to reading this book is only a working knowledge of programming on Linux with ‘C’, as that is the medium that is used throughout it (along with a few bash scripts).
this comprehensive guide to kernel internals, writing kernel modules, and kernel synchronisation was published by Packt in March 2021. All the material and code examples in the book are based on the 5.4 LTS Linux kernel. This kernel is slated to be maintained right through December 2025, thus keeping the book’s content very relevant for a long while! It can be a handy resource for people dealing with device drivers, embedded Linux, the Linux kernel or Linux programming.
The book is divided into three major sections. The extract that follows is taken from Chapter 12 of the book. Titled ‘Kernel Synchronization – Part 1’, this chapter falls under section 3 ‘Delving Deeper’.
Part 1: Kernel Synchronization Chapter 12: Concepts – the lock
We require synchronization because of the fact that, without any intervention, threads can concurrently execute critical sections where shared writeable data (shared state) is being worked upon. To defeat concurrency, we need to get rid of parallelism, and we need to serialize code that’s within the critical section – the place where the shared data is being worked upon (for reading and/or writing).
To force a code path to become serialized, a common technique is to use a lock. Essentially, a lock works by guaranteeing that precisely one thread of execution can “take” or own the lock at any given point in time. Thus, using a lock to protect a critical section in your code will give you what we’re after – running the critical section’s code exclusively (and perhaps atomically; more on this to come).
Figure 12.3 shows one way to fix the situation mentioned previously: using a lock to protect the critical section! How does the lock (and unlock) work, conceptually?
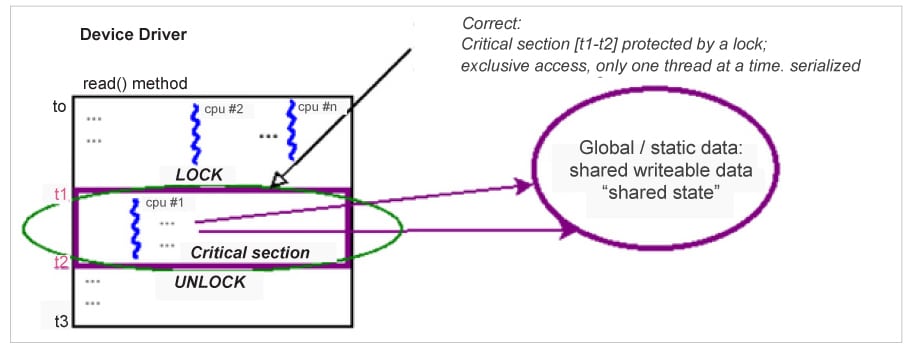
The basic premise of a lock is that whenever there is contention for it – that is, when multiple competing threads (say, n threads) attempt to acquire the lock (the LOCK operation) – exactly one thread will succeed. This is called the “winner” or the “owner” of the lock. It sees the lock API as a non-blocking call and thus continues to run happily – and exclusively – while executing the code of the critical section (the critical section is effectively the code between the lock and the unlock operations!). What happens to the n-1 “loser” threads? They (perhaps) see the lock API as a blocking call; they, to all practical effect, wait. Wait upon what? The unlock operation, of course, which is performed by the owner of the lock (the “winner” thread)! Once unlocked, the remaining n-1 threads now compete for the next “winner” slot; of course, exactly one of them will “win” and proceed forward; in the interim, the n-2 losers will now wait upon the (new) winner’s unlock; this repeats until all n threads (finally and sequentially) acquire the lock.
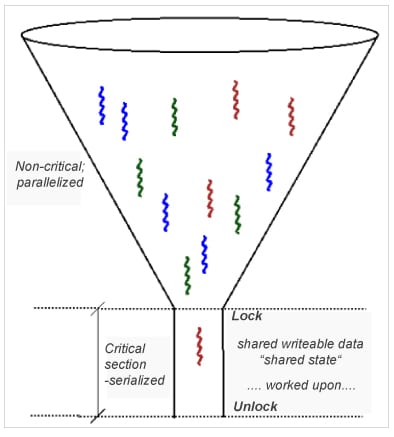
Now, locking works of course, but – and this should be quite intuitive – it results in (pretty steep!) overhead, as it defeats parallelism and serializes the execution flow! To help you visualize this situation, think of a funnel, with the narrow stem being the critical section where only one thread can fit at a time. All other threads get choked; locking creates bottlenecks.
Another oft-mentioned physical analog is a highway with several lanes merging into one very busy – and choked with traffic – lane (a poorly designed toll booth, perhaps). Again, parallelism – cars (threads) driving in parallel with other cars in different lanes (CPUs) – is lost, and serialized behavior is required – cars are forced to queue one behind the other.
Thus, it is imperative that we, as software architects, try and design our products/projects so that locking is minimally required. While completely eliminating global variables is not practically possible in most real-world projects, optimizing and minimizing their usage is required.
We shall cover more regarding this, including some very interesting lockless programming techniques, later. Another really key point is that a newbie programmer might naively assume that performing reads on a shared writeable data object is perfectly safe and thus requires no explicit protection (with the exception of an aligned primitive data type that is within the size of the processor’s bus); this is untrue. This situation can lead to what’s called dirty or torn reads, a situation where possibly stale data can be read as another writer thread is simultaneously writing while you are – incorrectly, without locking – reading the very same data item.
Since we’re on the topic of atomicity, as we just learned, on a typical modern microprocessor, the only things guaranteed to be atomic are a single machine language instruction or a read/write to an aligned primitive data type within the processor bus’s width. So, how can we mark a few lines of “C” code so that they’re truly atomic? In user space, this isn’t even possible (we can come close, but cannot guarantee atomicity).
How do you “come close” to atomicity in user space apps? You can always construct a user thread to employ a SCHED_FIFO policy and a real-time priority of 99. This way, when it wants to run, pretty much nothing besides hardware interrupts/exceptions can preempt it. (The old audio subsystem implementation heavily relied on this.)
In kernel space, we can write code that’s truly atomic. How, exactly? The short answer is that we can use spinlocks! We’ll learn about spinlocks in more detail shortly.
A summary of key points
Let’s summarize some key points regarding critical sections. It’s really important to go over these carefully, keep these handy, and ensure you use them in practice.
- A critical section is a code path that can execute in parallel and that works upon (reads and/or writes) shared writeable data (also known as “shared state”).
- Because it works on shared writable data, the critical section requires protection from the following:
- Parallelism (that is, it must run alone/serialized/in a mutually exclusive fashion)
When running in an atomic (interrupt) non-blocking context– atomically: indivisibly, to completion, without interruption. Once protected, you can safely access your shared state until you “unlock”.
- Every critical section in the code base must be identified and protected:
- Identifying critical sections is critical! Carefully review your code and make sure you don’t miss them.
- Protecting them can be achieved via various technologies; one very common technique is locking (there’s also lock- free programming, which we’ll look at in the next chapter)
- A common mistake is only protecting critical sections that write to global writeable data; you must also protect critical sections that read global writeable data; otherwise, you risk a torn or dirty read! To help make this key point clear, visualize an unsigned 64-bit data item being read and written on a 32-bit system; in such a case, the operation can’t be atomic (two load/store operations are required). Thus, what if, while you’re reading the value of the data item in one thread, it’s being simultaneously written to by another thread!? The writer thread takes a “lock” of some sort but because you thought reading is safe, the lock isn’t taken by the reader thread; due to an unfortunate timing coincidence, you can end up performing a partial/torn/dirty read! We will learn how to overcome these issues by using various techniques in the coming sections and the next chapter.
- Another deadly mistake is not using the same lock to protect a given data item.
- Failing to protect critical sections leads to a data race, a situation where the outcome – the actual value of the data being read/written – is “racy”, which means it varies, depending on runtime circumstances and timing. This is known as a bug. (A bug that, once in “the field”, is extremely difficult to see, reproduce, determine its root cause, and fix. We will cover some very powerful stuff to help you with this in the next chapter, in the Lock ebugging within the kernel section; be sure to read it!)
- Exceptions: You are safe (implicitly, without explicit protection) in the following situations:
- When you are working on local variables. They’re allocated on the private stack of the thread (or, in the interrupt context, on the local IRQ stack) and are thus, by definition, safe.
- When you are working on shared writeable data in code that cannot possibly run in another context; that is, it’s serialized by nature. In our context, the init and cleanup methods of an LKM qualify (they run exactly once, serially, on insmod and rmmod only).
- When you are working on shared data that is truly constant and read-only (don’t let C’s const keyword fool you, though!).
- Locking is inherently complex; you must carefully think, design, and implement this to avoid deadlocks. We’ll cover this in more detail in the Locking guidelines and deadlocks section.
Further on in the book, we shall show you how exactly you can check in which context your kernel code is currently running. Read on!
Note: The book’s source repositories are publicly available on GitHub, as indicated below.
|


