





























































MyRocks is a unique database engine designed by Facebook to work with RocksDB so that MySQL can be used with the database. Even though InnoDB (another DB in use at Facebook) seems better than MyRocks in certain ways, in the case of the former, MySQL cannot be used with an embedded database. Therefore, MyRocks is considered better than InnoDB and it really rocks!
As data is the basic requirement of any software system, storing data in a safe and easily accessible manner is the biggest challenge. That’s where a database comes into play. It can organise, store and retrieve data from a computer storage system using software. Such software is known as a database management system (DBMS), and it helps users and applications to store or retrieve data from it. However, when the database is too large and on a cloud network or server, then it becomes tedious to store and retrieve data effectively. That’s why a database engine is needed with a DBMS to perform database operations with minimum latency.
Various DBMSs like MySQL, PostgreSQL, MSSQL, Oracle Database and Microsoft Access can be used with a database server. Such DBMSs were being used with database servers that had traditional magnetic hard drives. However, magnetic drives can cause a lot of latency compared to a solid state drive (SSD). As SSDs use Flash memory chips instead of a magnetic disk or any mechanical moving parts, the read/write speed of SSDs is faster than traditional magnetic drives. That’s why such SSDs can be used in a database server to store/retrieve data with minimum latency. So, for SSD technology with a database server, special database software is required, and that’s where RocksDB enters the picture!
With RocksDB, it’s possible to use SSDs in a database server. It’s an embedded database that can be used with SSDs and requires very little maintenance. It was created by Facebook in May 2012, using the C++ programming language, in order to overcome the disadvantages of InnoDB, which caused read/write/space amplification factors. However, Facebook wanted MySQL features with the database servers, using SSDs. As MySQL is great for backup and automation, Facebook wanted to use it along with RocksDB. That’s why Facebook developed the MyRocks database engine in 2015 and it was also written in C++. MyRocks integrates RocksDB and MySQL in a way that SQL can be used by Facebook applications with the RocksDB database server. MyRocks is an open source database engine that helps to store/retrieve data from an embedded database like RocksDB, using MySQL.
Requirements and limitations of MyRocks
- MyRocks requires C++ compilers and libraries for development.
- It works with RocksDB to implement the MySQL layer.
- It is based on Oracle MySQL 5.6.
- MyRocks is included from MariaDB 10.2.5 onwards.
- It requires MariaDB server on Linux and Windows.
- MyRocks builds are available on platforms that support sufficiently modern compilers like Ubuntu Trusty, Xenial (amd64 and ppc64el), Ubuntu Yakkety (amd64), Debian Jessie (stable –amd64, ppc64el), Debian Stretch, Sid (testing and unstable — amd64), CentOS/RHEL 7 (amd64), Centos/RHEL 7.3 (amd64), Fedora 24 and 25 (amd64), OpenSUSE 42 (amd64), and Windows 64 (Zip and MSI).
- MariaDB’s optimistic mode of parallel replication may not be supported.
- MyRocks is not available for 32-bit platforms.
- Galera Cluster is tightly integrated into the InnoDB storage engine (it also supports Percona’s XtraDB which is a modified version of InnoDB). Galera Cluster does not work with any other storage engine like MyRocks (or TokuDB, for example).
Functionality and architecture
Being a database engine, MyRocks is used by the DBMS to create, read, update and delete (CRUD) data from a database. Information in a database is stored as bits laid out as data structures in a storage system that can be efficiently read from and written to the properties of hardware. There are various types of data structures — linear, trees, hash-based and graphs. Most database engines use trees for storing and retrieving data. The most commonly used data structure for trees is the B tree. Database engines use this type of data structure for storing/retrieving data. Some even use the Indexed Sequential Access Method (ISAM) but the B tree is more popular.
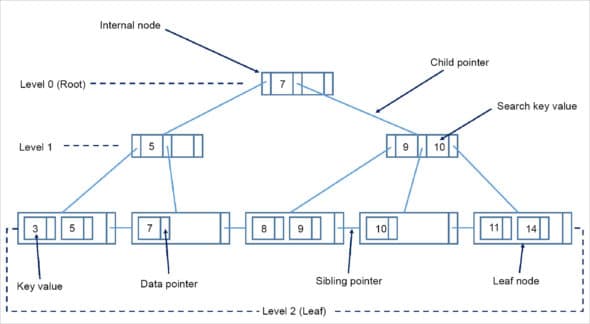
In a B tree storage system, keys and data are stored as nodes and it starts with a root node which is connected to other parent and child nodes. This process of data storage makes it easier for data insertion and deletion. However, the B+ tree is a newer extension of the B tree and it is more efficient for data insertion, deletion and search operations. It consists of a root, internal nodes and leaves. The root may be either a leaf or a node with two or more children. In a B tree, both the data and keys are stored in the internal and leaf nodes, but the B+ tree can store data only in the leaf nodes, while the keys are stored in the internal nodes. The leaf nodes of a B+ tree are linked together like a single linked list and this makes the search operation more efficient.
The B+ tree is used to store large amounts of data that cannot be stored in the main memory. As the size of the main memory is often limited, the internal nodes (keys to access records) of the B+ tree are stored in the main memory, whereas leaf nodes (containing data) are stored in the secondary memory. The internal nodes of a B+ tree are also called index nodes because they always point to the leaf nodes that contain the actual data. A B+ tree (except the root node) can have M/2 minimum internal and leaf nodes (where ‘M’ is the maximum number of nodes except the root node) and can have M – 1 leaf nodes.
B+ tree search algorithms are used to search data efficiently and can be used as follows:
- Call the binary search method on the nodes of the B+ tree.
- If the search parameters are matched then:
The accurate result is returned and displayed to the user.
Else, if the node being searched is the current and the exact key is not found:
Display the statement “Recordset cannot be found!
However, though such B+ tree algorithms may be efficient, the database can still perform poorly during random access. RocksDB can resolve this problem because it uses a data structure called Log Structured Merge Tree (LSMT). This has a hybrid kind of data structure and combines various components of data structures to store/retrieve data. It is generally assumed that sequential access is faster than random access, whether it’s magnetic storage or an SSD. As a B+ tree allows both random and sequential access, during the random access operations, the performance of the database can be affected, even when used with SSDs. That’s why LSMT is used by RocksDB to overcome this problem.
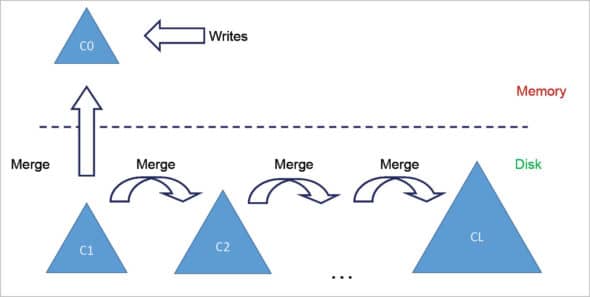
In LSMT, data is structured as logs at various levels and stored in the memory and disk. A minimum two-level LSMT uses two logs, one for the memory and another for the disk storage (Flash/ SSD). For example, C0 is the top-level log and stays in the memory.
Whereas C1 is a segment of C0 but is stored in the disk, and the elements are inserted in the C0 log. When the size of the log exceeds the memory, the log is merged with the C1 log on the disk. Similarly, more than two levels can have more merges and logs, like C2, C3, C4… CL logs (L = total number of levels). As the latency of the main memory is less than the disk, storing recently updated logs in the memory can improve the performance of the database. This method of storing data is relevant to sequential access and has better IO throughput.
Using RocksDB with LSMT improves the performance of the embedded database, but a good DBMS also helps automate and maintain the database efficiently. MySQL is one such DBMS that can perform various types of operations with the Structured Query Language (SQL), which programmers use to create, modify and extract data from the relational database and also control user access to the database. It is an open source relational database management system (RDBMS), which organises data into one or more data tables, in which the data types may be related to each other and these relations help structure the data.
SQL language uses keywords, identifiers, clauses, expressions, predicates, queries, statements and insignificant whitespace. Keywords are words that are defined in the SQL language. They are either reserved (e.g., SELECT, COUNT and YEAR), or non-reserved (e.g., ASC, DOMAIN and KEY). Identifiers are names of database objects, like tables, columns and schemas. An identifier may not be equal to a reserved keyword, unless it is a delimited identifier (identifiers enclosed in double quotation marks) and can contain characters normally not supported in SQL identifiers. An identifier can also be identical to a reserved word, e.g., ‘COUNT’.
Clauses are constituent components of statements and queries. Expressions can update values or change columns and rows of data in a table. Predicates are used for conditional statements to evaluate three-value logic (true/false/unknown) or Boolean truth values. Queries help retrieve the data based on specific criteria and it is an important element of SQL. Statements are used to do many database operations like transactions, database automation and diagnostics. Insignificant whitespace is generally ignored in SQL statements and queries, making it easier to format SQL code for readability.
SQL can be used to perform various logical operations on a database. For example:
CASE n WHEN 0 THEN ‘Zero’ WHEN 1 THEN ‘One’ ELSE ‘Out of range!’ END
The above SQL ‘CASE’ statement is useful for conditional database operations.
Queries are important operations of SQL for any database. For example:
SELECT Car.brand AS Brand, count(*) AS Company FROM Car JOIN Car_company ON Car.price = Car_company.price GROUP BY Brand;
The above statement uses the ‘SELECT’ clause to retrieve data about cars from an inventory database of sellers, based on the price and brand.
As SQL operations are important for database operations, MyRocks is used with RocksDB to support MySQL. MyRocks integrates RocksDB with MySQL and helps to run SQL commands. MyRocks is a database engine that stores data using RocksDB as Static Sorted Table (SST) files in the SSDs. Such files are segmented using the Log Structured Merge Tree (LSMT) concept and stored in the disk.
The pros and cons of MyRocks
| Pros | Cons |
| MyRocks integrates RocksDB with MySQL and makes it possible to use SQL for the embedded database. | MyRocks doesn’t make use of additional memory like InnoDB, and it doesn’t benefit from increasing the memory size. |
| MyRocks is 2x smaller than InnoDB (compressed) and 3.5x smaller than InnoDB (uncompressed). | The read amplification of MyRocks can be improved with additional memory but still remains greater than InnoDB. |
| MyRocks does not require a lot of memory and performs the IO operations constantly, while using most of the CPU resources. | MyRocks uses a lot of CPU no matter how much memory is allocated to it, and that’s why its performance is limited to the CPU. |
| MyRocks is a write-optimised engine and reduces the write amplification to a greater extent. |
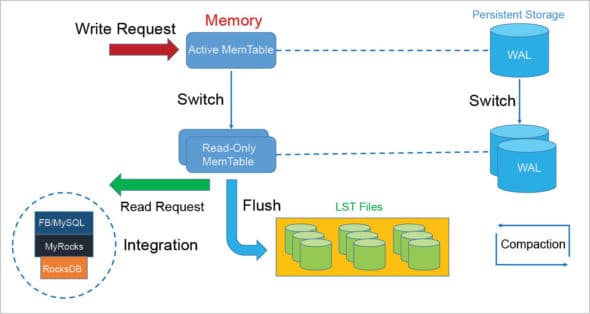
Any write request made to the memory is stored in the Active Memtable and another copy is created as a Read-Only Memtable (ROM). When the data exceeds the memory, it is flushed to the disk as SST files using the LSMT concept. Simultaneously, log files called Write Ahead Log (WAL) are created and stored separately on the disk. These log files are later used to restore any data in case of a system failure. During a read request, the ROM is used from the memory to retrieve data. MyRocks integrates RocksDB and MySQL to perform these operations flawlessly, using SQL.
Features
MyRocks makes it possible to run MySQL with RocksDB, and has the following features.
- Greater space efficiency: MyRocks has 2x better compression compared to compressed InnoDB and 3x – 4x better compression compared to uncompressed InnoDB. This makes it possible to use less space.
- Greater writing efficiency: MyRocks has a 10x less write amplification compared to InnoDB and gives better endurance of Flash storage, which improves the overall throughput.
- Faster replication: No random reads for updating secondary keys, except for unique indexes. The Read-Free Replication option restricts any random reads when updating primary keys and this makes faster replication.
- Faster data loading: MyRocks writes data directly onto the bottom-most level and avoids all compaction overheads when you enable faster data loading for a session.














