





























































In this new series of articles, we take a deep dive into Web protocols and look at how these have evolved over time. This article is a must for anyone who wishes to understand the Internet and the way it works.
The Internet is one of the biggest technological marvels of modern times, enabling easy communication across the globe, opening up new ways of commerce and supporting a wide variety of other conveniences. While it is referred to in the singular, it is composed of a plethora of hardware and software solutions. Multiple governments, communities and corporations have, individually and collaboratively, made huge investments to build the infrastructure and applications of the Internet.
Overall, the network consists of the application (user-visible) and infrastructural layers. Given the scale of the Internet, both comprise a humongous number of software and hardware components. We look at a few examples of these in Table 1 to get a feel of the variety of components deployed.
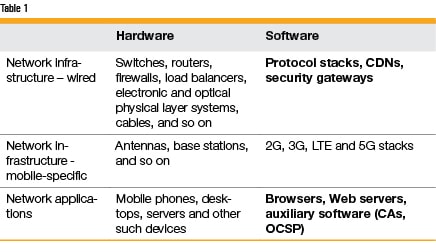 Among the entities in this table, our interest lies in the software components, and particularly on those highlighted in bold text. Most of the traffic driven by these elements belongs to a handful of protocols, dominant among which are DNS, HTTP, SSL/TLS, TCP and IP — these are literally the workhorses of the Internet. These protocols are layered as a stack, which is described in detail in the next section.
Among the entities in this table, our interest lies in the software components, and particularly on those highlighted in bold text. Most of the traffic driven by these elements belongs to a handful of protocols, dominant among which are DNS, HTTP, SSL/TLS, TCP and IP — these are literally the workhorses of the Internet. These protocols are layered as a stack, which is described in detail in the next section.
Our interest in this series of articles is to understand how each protocol evolved individually and as part of the stack, and the reasons that led to the evolution. The series is structured as follows.
In this first article in the series, we start with outlining the end-to-end flow of information for Web interactions. Then, we step back in time and mark the key milestones in the evolution of the protocol stack. We also dive into the early protocols including HTTP 1.1, DNS, SSL/TLS, and OCSP. This forms the basis for understanding the newer protocols.
In the second article in the series, we start with a recap of the reasons that led to the definition and development of the second generation of Web protocols. Then, we dig further into SPDY, HTTP 2 and TLS 1.2.
The Web is still growing and evolving. So, in the third and last article in the series, we turn our attention to the proposed or recently standardised newer protocols including DNS over HTTPS, TLS 1.3, QUIC, and HTTP 3.
Terminology: Protocol stack
The network infrastructure (proxies, CDNs, firewalls or load balancers) and network applications (browsers or Web servers) have one thing in common — the protocol stack. Since this stack is such a ubiquitous entity, we will spend some time trying to describe it with some precision.
The first step is to understand why a ‘protocol stack’ is needed. A ‘protocol’ is required when components developed independently — either by different teams, organisations, countries or a mix of these — need to interoperate and deliver the same experience as if they were developed together. In our context, the word ‘protocol’ is only applied to ‘network protocol’, and the components referred to are those that provide communication features. For example, a browser allows one to access an online encyclopaedia, a Web mail client allows one to communicate with other humans, and so on. In these cases, typically, the browser and the online encyclopaedia are not developed by the same organisation, as the expertise required to build these services is vastly different. However, users accessing the same encyclopaedia from different browsers must see the same content and get the same look-and-feel.
Moreover, users may access the encyclopaedia from different networks (work/home/coffee shop/car) or different devices (desktop/handheld). In all these cases, not only must the user be able to access the content seamlessly, but also have a consistent experience. ‘Protocols’ play a big part in making this happen.
The other word in the term ‘protocol stack’ is ‘stack’. The early designers of networking protocols foresaw the complexities of network communication and proposed a layered approach to tame this complexity. In this approach, each layer addresses a set of requirements for communication, and provides those as services to the next higher layer. In this manner, a ‘stack’ of layers provides the full set of functionalities. Now, juxtaposing these two words, gives a layered solution, where each layer implements one or more protocols.
The big picture
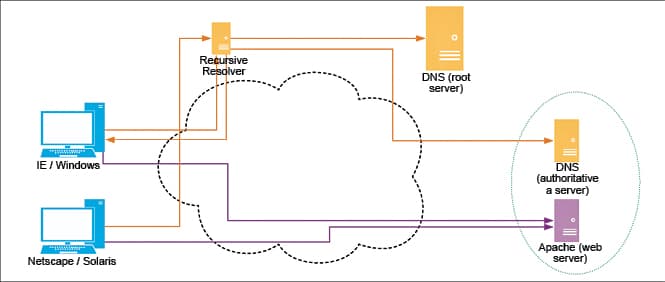
Now, we turn our attention to the end-to-end flow of information from the client to the server and back, as depicted in Figure 1. In this diagram, the browsers on the left are attempting to retrieve content from the Web server on the right. When the client system is started afresh, the browser may not even be aware of the network address of the Web server. So, it all starts with the browser converting the hostname to a network address, which is accomplished with the DNS protocol. Once this conversion is done, the actual process of Web access is delivered by three key protocols: IP, TCP and HTTP. IP, the lowest of these three layers, handles addressing and routing of packets from the source to the destination, while TCP adds reliability on top of the functionality provided by IP. Finally, the HTTP protocol is the one that allows a browser to request for the required content and receive the response sent by the Web server. All the different types of Web content like HTML, JavaScript, CSS and a variety of other content are all transported using HTTP.
Figure 1 shows the different steps in communication, and it is worth reviewing these closely.
1. A user enters a URL in the browser or clicks a link; say, the destination URL is http://www.example.com/test. In this case, the sub-string www.example.com is referred to as the hostname (or, more formally, as FQDN or Fully Qualified Domain Name). In either case, the browser needs to connect to the Web server for the given URL, obtain the content and render it.
2. To connect to the Web server, the browser requires a network address for the given hostname (in this case, www.example.com). This is achieved by performing a DNS lookup, which itself involves other sub-steps, which finally lead to locating a DNS server that returns the required network address. Such a server is called the authoritative server or nameserver for the FQDN.
3. Once the network address is obtained, the browser connects with the Web server and initiates an HTTP request for the URI /test. If the server returns data associated with the URI /test, the browser infers the content type and renders it accordingly.
Note the distinction between the complete URL, hostname and the URI. The end user is always interested in the complete URL but the communication system handles this in two parts: the hostname and the URI. It is worth reiterating that the hostname is looked up over DNS to obtain the IP of the Web server. Once a connection is made with this IP address, only the URI (i.e., the component after the hostname) is sent over this connection.
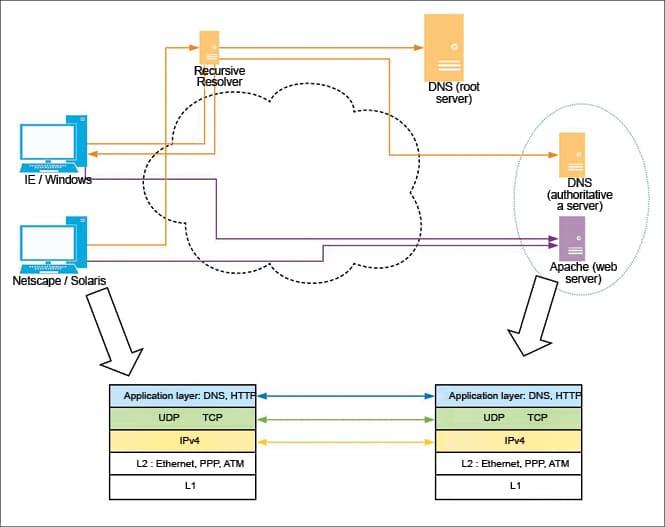
Both steps 2 and 3 above involve the ‘protocol stack’. This is shown in Figure 2, though for brevity, only the browser and Web server stacks are shown.
Figure 2 represents the core software protocols and layers of network communication. Also, the entities for browsers and Web servers are intentionally chosen to represent the early software. This leads us to the history of the protocol stack.
 History of the protocol stack
History of the protocol stack
The early days of the Web: The 1990s
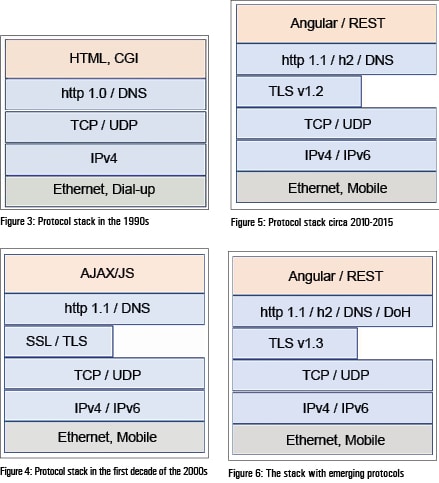
As indicated earlier, the early version of the Web consisted of the stack shown in Figure 3.
The initial implementation of the Web protocol stack was founded on four key protocols: DNS, IP, TCP and HTTP. While the other three protocols have remained largely like what they were then, HTTP has followed a slightly different path. The early Web used HTTP 1.0, which was defined in May 1996 but was revised as HTTP 1.1 in 1999. HTTP 1.0 had the disadvantage of permitting only a single request-response pair on a TCP connection, which was addressed in HTTP 1.1. This and other improvements made HTTP1.1 the Internet workhorse for a long period of time.
Web 2.0: The first decade of the 2000s
As the Internet grew, it became a platform suitable for commercial activities, primarily because it brought together many parties. Applying the Web for commerce naturally led to concerns of message integrity, confidentiality and authenticity. HTTP, being a simple text-based protocol, offered none of these. Thus was born Secure Socket Layer or SSL. This protocol also evolved quickly, and by the early 2000s, SSLv3 was good enough security for that time. This added a new layer to the Web stack, as shown in Figure 4. However, it was an ‘optional’ layer and protocols like DNS continued to be in clear text (just to reiterate, it was not so much about deployment but rather about definition — DNS over SSL was not defined till very recently).
If the early Web took off in a big way, Web 2.0 was much more amenable for developing a variety of Internet based applications, including maps, online shopping, social networking, and so on. This stack quickly became the pillar for most Internet communications.
Further advances
The initial protocol stack shown in Figure 2 was the framework for the Web 2.0 advances that happened in the first decade of the new millennium. Separately, the growth of the Internet drove other activities, which are summarised below.
1. The security of Web transactions continued to be a concern, and the community responded by developing three versions of TLS: 1.0, 1.1 and 1.2.
2. Concerns about the paucity of IPv4 addresses led to the initial deployments of IPv6, but the latter did not take off in a big way as organisations found ways to manage with the scarce IPv4 addresses, especially by using techniques like NAT.
3. 3G, and then LTE networks, were built and deployed, which started an entire new stream of Web clients.
4. Near the end of the first decade of 2000, social networking tools emerged, leading to users demanding an ‘always-on’ experience.
All these changes led to two major concerns or requirements:
- Reduced latency for every kind of device from anywhere in the world.
- Improved security and privacy for everyone.
Google, primarily because of its global reach and business, took the lead in attacking the first of the two problems. Acting from extensive data collected by the Chrome/Google server end-to-end systems, Google researchers proposed SPDY as an alternative to HTTP 1.1. The overall proposal was for optimisation, either by cutting bits in the headers (by making them binary and compressing them) or by cutting wait time by allowing concurrent request-responses on a single connection. Eventually, SPDY was taken to IETF (Internet Engineering Task Force), and was rechristened as HTTP 2.0 after minor modifications. This led to the morphing of the stack, as shown in Figure 5. This was a very important step as the key Web protocol, HTTP, was being overhauled roughly after a decade.
However, Google and others continued their data collection efforts to verify that HTTP 2.0 had indeed helped with the latency problem. The data indicated that HTTP 2.0 was still limited by TCP’s slow start and congestion control and, thereby, indicated further scope for optimising latency. Based on this, QUIC was proposed as a potential replacement for TCP, and this is still being discussed at IETF.
Concurrently, the security researchers improved TLS 1.2 to TLS 1.3, bringing in both performance and security gains. That brings us to the present, and Figure 6 represents the stack as of today.
Separately, it was recognised that DNS was one of the last protocols that sent unencrypted data over the network. While this is not the content required by the user, it nevertheless represented metadata that could still be of importance to attackers. To plug this, a secure version of DNS, named DNS-over-HTTPS was proposed and standardised by IETF.
Overview of the key protocols of the early era
To recap, the key Web protocols of the early era, i.e., during 1990s, are:
1. TCP/IP
2. HTTP
3. DNS
4. SSL
As our focus is not on core networking, we will only cover the HTTP, DNS and SSL protocols briefly. However, there is extensive literature on these protocols on the Web. As there is no great benefit in duplicating any of that, the objective here is to discuss the key attributes of the protocol that will help an interested reader, at least as a starting point, for further study.
DNS: DNS, the Domain Name System, is provided by the collective effort of the following entities:
1. DNS client
a. DNS resolver in OS, called the stub resolver.
2. DNS servers
a. Recursive resolvers – the entities that receive the DNS requests from stub resolvers.
b. Authoritative DNS servers – which host the various DNS attributes for host names.
The above entities ‘talk’ the DNS protocol, which is in binary. The client initiates a DNS request, which contains one or more questions. The key attributes of each question are Hostname (or fully qualified domain name) and DNS property type.
Various DNS property types are:
- A (request for IPv4 address of the accompanying hostname)
- AAAA (request for IPv6 address)
- MX (request for mail server addresses)
- TXT, and so on
The DNS servers parse the question(s) and either forward it (them) or respond. The DNS response contains answers that either contain an error code or the information sought by the client. It also contains metadata, like TTL or the time duration for which the response is valid.
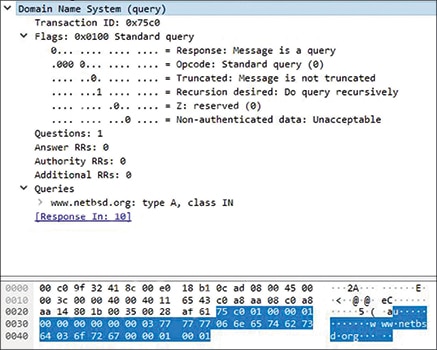
A sample DNS capture from Wireshark examples is given in Figure 7 to help the reader get a feel of the structure of DNS packets. This is an IPv4 address lookup for the hostname www.netbsd.org.
The response packet returns the IPv4 address for the requested domain and indicates the TTL for the same. The flags indicate the following:
1. This response was not obtained from the authoritative server. So, it must have been returned from the cache entry of some recursive resolver in the path.
2. The DNS response is not authenticated, which means the DNS server did not employ DNSSEC.
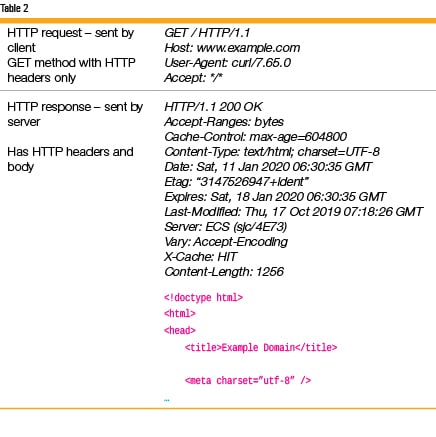
HTTP: The HTTP protocol shares some similarities with the DNS protocol, as it also follows the client-server paradigm. The HTTP client initiates a request which, unlike DNS, is in regular text. Each request has a method that indicates the type of service required by the client. The most popular is the GET method, which is a request for information. The server answers with a HTTP response that either provides the information or returns an error code. As HTTP is pure text, it is best to just look at the HTTP request-response pair to get a quick idea of the protocol (Table 2).
An HTTP message consists of a header and an optional body. In the example in Table 2, the GET request does not have a body, but the GET response has one.
SSL: As seen in the previous sections, the data transported on DNS and HTTP protocols is unencrypted. This implies that if the data can be captured by a third party, it is readily available for viewing and interpretation. Second, not only is the data available to the third party, it is possible for this party to even modify in-flight data for its own benefit. Thus, these protocols do not have the properties of:
1. Confidentiality, and hence are susceptible to data viewing by a passive third party.
2. Integrity, and hence are susceptible to data modification by an active third party.
 Note: Another property, called Authenticity, is also not provided by DNS and HTTP. SSL provides mechanisms for ensuring Authenticity also.
Note: Another property, called Authenticity, is also not provided by DNS and HTTP. SSL provides mechanisms for ensuring Authenticity also.
To address the above, Netscape defined the SSL protocol, which was further enhanced and standardised by IETF as TLS. The SSL protocol has two phases: the Handshake phase and the Record phase. During the Handshake, the client and server negotiate a session key, which is used to encrypt the actual data that is transferred during the Record phase of the protocol. Then, the data in the Record protocol is opaque to a passive third party. Also, SSL incorporates data signatures such that any modification to the data can be detected by the other party. Thus, when HTTP is transported over SSL (and the resultant protocol is the very popular HTTPS), it is reasonably safe from third party attackers.
A quick recap
We started with understanding the phrase protocol stack in the context of computer networking. Then, we saw that ‘HTTP/DNS, TCP/UDP IP’ was the protocol stack for the early Internet. Later, this stack evolved first to HTTP/1.1, and then added an end-to-end security protocol, SSL. In the last decade, the Internet stack evolved more rapidly with the definition of new versions of protocols at various layers in the stack, including:
- HTTP2, HTTP3 and DNS-over-HTTPS at the application layer
- TLS 1.3 at the security
- QUIC at the transport layer
Then, we took a quick look at the format of the DNS, HTTP and SSL protocols. In the next article in this series, we will discuss the HTTP2, TLS 1.3 and DNS-over-HTTPS protocols.














