

























































A cloud tool is a software program designed to make local and cloud based components work together. This article lists the top-of-the-line open source cloud tools in use today.
Enterprises are now using various IT resources to enhance their business. Profits increase when expenses decrease, and open source tools that are free to use and modify can help companies to reduce costs. Cloud vendors are also delivering numerous new tools to help enterprises get most value from cloud services. These tools enable organisations to use their budgets and manpower for more strategic business projects. Here is a list of the top open source tools in use today.
Grafana
Grafana allows you to query, visualise, and understand your metrics no matter where they are stored. You can create, explore and share dashboards with your team, and foster a data driven culture. Its best use cases are infra time series data, industrial sensors, weather and process control. Grafana is written in Go and Node.js. It comes with an inbuilt embedded database called sqlite3. We can use other data stores like MySQL, PostgreSQL, Graphite, Influx DB, Prometheus and Elasticsearch for storing data. It also supports other data stores by using additional plugins.
Grafana can be installed on Linux, Windows, Docker and Mac. It comes with built-in user controls and authentication mechanisms like LDAP, Google Auth and GitHub, which help control access to the dashboards. Top of above listed authentications, Grafana supports AD authentication as well. Grafana has an API interface that can be used to save a dashboard, create users and update data sources.
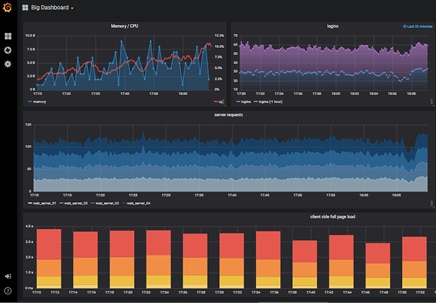
You can create dynamic and reusable dashboards with minimum effort and also have the option to create templates for re-use. Exploring and searching logs with preserved label filters makes your job easier for creating dashboards. You can even use ad-hoc queries to explore specific data and drill down to source. Grafana has an inbuilt alerting system with which you can define the alert rules for the specified metrics. It will continuously evaluate the same and send notifications to systems, in the form of an email, or via Slack, PagerDuty, VictorOps and OpsGenie.
When you compare Grafana with Kibana, the former is a better fit for time series data based on specific metrics (e.g., CPU/disk/IO utilisation). But Kibana is a better fit for analytics dashboards that use Elasticsearch capabilities. So we cannot use Grafana for data search and exploring.
Terraform
Terraform is a cloud immutable infrastructure tool from HashiCorp. It is used to build, change and version infrastructure efficiently. In short, Terraform is useful to deliver Infrastructure-as-a-Code (IAAC). It supports the infrastructure of most of the public cloud service providers as well as on-premise infrastructure.
Terraform is platform-agnostic and helps you to deploy coding principles like automated tests, source code control, etc. It has a massive community backing, and many organisations have started using it to manage their infrastructure.
You can do a dry run of Terraform, which simulates actual changes without committing, a feature that is very useful for developers. Terraform Resource Graph creates a graphical view of all the resources, including the dependency between each resource. Terraform leverages the respective cloud provider’s API to manage the infrastructure, which reduces the requirement for additional resources.
Terraform is a declarative language that describes the target level of the resource. Plugins are available for popular cloud vendors to manage the respective cloud resources. In addition, you can create your own plugins in many languages. Terraform mainly supports the Go language.
resource “aws_s3_bucket” “b” {
bucket = “s3-mywebsite.com”
acl = “public-read”
policy = “${file(“mypolicy.json”)}”
website {
index_document = “index.html”
error_document = “error.html”
routing_rules = <<EOF
[{
“Condition”: {
“KeyPrefixEquals”: “doc/”
},
“Redirect”: {
“ReplaceKeyPrefixWith”: “document/”
}
}]
EOF
}
}
git-secret
A usual developer practice is to encrypt the passwords/credentials used in the code and then save them in some secure place. We have multiple tools for this purpose, Vault being one of them. git-secret is a simple tool to store the secrets in the Git repo. git-secret uses gpg for encryption and decryption of secrets.
Use cases for keeping secrets are:
- To manage keys at a centralised location for encryption and decrypting
- Version control the secrets for better management
- Access control and leverage who can encrypt and decrypt the secret
- No secrets to be stored in plain text
- You can use git-secrets to store Oauth keys, DB passwords, application keys and other secret keys which are stored in plain text.
git-secret is a tool to store private data inside a Git repository. It encrypts the password using gpg and tracks files with the public keys of all the users who are already trusted. So users can decrypt the files using their respective personal secret keys only, and there will be no passwords that change here. When people leave the organisation or are replaced, just delete the public key, re-encrypt the files and they won’t be able to decrypt secrets anymore.
Installing git-secret is very easy; just get the gpg key ready for the repo and install the secret with that key. The key config variables are:
- $SECRETS_VERBOSE: Sets verbose flag for all git-secret commands
- $SECRETS_GPG_COMMAND: Sets gpg alternatives (defaults value is gpg)
- $SECRETS_EXTENSION: Sets the secret file extension (default extn is .secret )
- $SECRETS_DIR: Sets the location where the files are to be stored (default folder is .gitsecret)
Aardvark and Repokid
Aardvark and Repokid can ensure roles retain only the necessary privileges in large dynamic cloud deployments. These are open source cloud security tools from Netflix, to accommodate rapid innovation and distributed, high-velocity development. They help us to achieve the principle of least privilege access without impacting performance.
All public cloud providers have identity and access management (IAM) services that help to create granular policies for users; however, the custom granular policies add complexity, which can make it more difficult for developers to create a product. Lacking the necessary permission makes the application fail, and excess permissions introduce security breaches and compliance issues.
Aardvark uses Phantoms to log into the cloud provider’s console and retrieve Access Advisor data for all of the IAM roles in an account. It stores the latest Access Advisor data in a DynamoDB database and exposes a RESTful API. Aardvark supports threading to retrieve data for multiple accounts simultaneously, and refreshes data in less than 20 minutes.
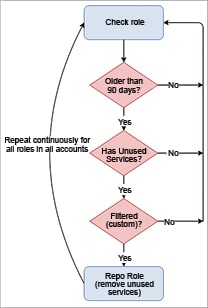
The DynamoDB table has data about policies, the count of permissions (total and unused), whether a role is eligible for repo or if it is filtered, and when it last removed the unused permissions (repo feature) of each role, as explained in Figure 2. Repokid uses the data stored in DynamoDB with the services not used by a role and removes permissions that were not used.
Once a role has been sufficiently profiled, Repokid’ s repose feature revises the inline policies attached to a role to exclude unused permissions. Repokid also maintains a cache of previous policy versions in case a role needs to be restored to a previous state. The repo feature can be applied to a single role but is more commonly used to target every eligible role in an account.
OpenShift
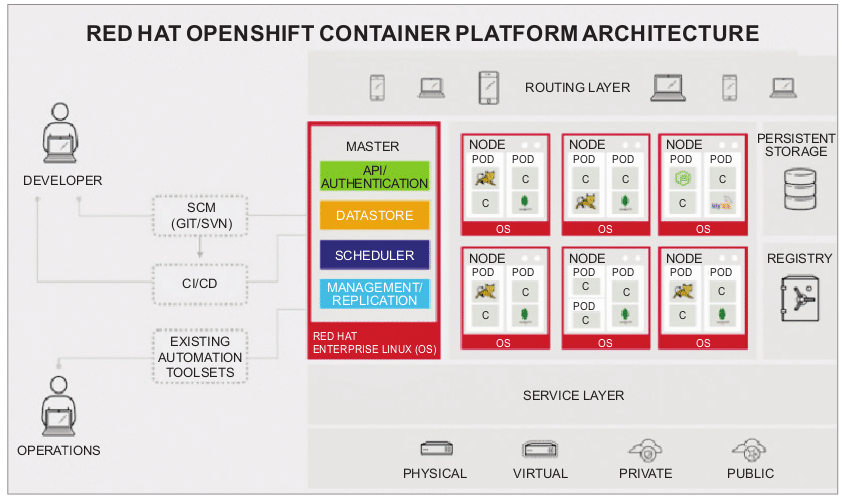
OpenShift is a service which is similar to Container-as-a-Service for on-premise and cloud platforms. It is built around Docker containers orchestrated and managed by Kubernetes on a foundation of Red Hat Enterprise Linux. The recent version of V3 comes with many new features. The OpenShift project is backed by Kubernetes, Docker, CoreOS, Framework, Cri-o, Prometheus, etc.
Grouping containers together vastly increases the number of applications that can be brought to OpenShift. This results in the benefit of having a single IP address and sharing a file system. Since OpenShift containers are immutable in nature, the application code, dependent libraries and secrets can be attached to the container at run time. This allows administrators and integrators to separate code and patch from configuration and data. The OpenShift container framework is shown in Figure 3.
OpenShift and Kubernetes are built as sets of microservices working together through common REST APIs to change the system. These very APIs are available to systems integrators and those same core components can be disabled to allow alternative implementations. OpenShift exposes fine-grained access control on the REST APIs which makes the service integrator’s job easy.
In OpenShift v2, an application was a single unit—it consisted of one Web framework and no more than one of any given cartridge type. So an application could have one PHP and one MySQL service, for example, but it could not have one Ruby, one PHP, and two MySQL services. It also could not be a MySQL cartridge by itself. So v2 is helpless when sharing a MySQL instance across two applications.
In OpenShift v3, you can link any two arbitrary components together. If one component can export environment variables and the second component consumes values from those environment variables, you can link together any two components without having to change the images they are based on. So the best container-based implementation of your desired database and Web framework can be consumed directly rather than you having to fork them both and rework them to be compatible.
BOSH – from the Cloud Foundry
BOSH is a cloud-agnostic open source tool for release engineering, deployment and life cycle management of complex distributed systems. Most distributions and managed Cloud Foundry environments use BOSH to holistically manage the environment so that you can focus on coding and delivering business value. Due to the flexibility and power of BOSH, Google and Pivotal made it the heart of the Kubo project (Web-scale release engineering for Kubernetes).
BOSH works like a distributed system, where collections of individual software components, running on different virtual machines, work together as a larger system.
The main components of BOSH are listed below.
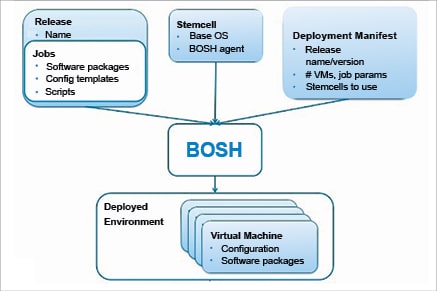
Stem cell: This is similar to a golden image of an OS used to create virtual machines. It isolates the base operating system from the other software packages bundled in a deployment.
Release: This is a layer put on top of a stem cell that describes what software should be deployed and how it should be configured. It contains configuration properties and templates, startup scripts, source code, binary artifacts, etc.
Deployment manifest: BOSH uses this YAML manifest file to deploy to the targeted infrastructure, monitor the health of the virtual machines or containers, and repair them when necessary.
Cloud Provider Interface: CPI is an API that BOSH uses to interact with infrastructure to create and manage stem cells, VMs and disks.
BOSH is being adopted in other environments to package and manage all kinds of software. BOSH’s strength is that it manages both Day One and Day Two operational tasks, such as getting software configured and upgrading it to new versions, testing the upgrade of an entire system from one version to another, resizing host machines, and handling security updates—without disrupting users—consistently and reliably.
Spinnaker
Spinnaker is an open source, multi-cloud continuous delivery platform for releasing software changes with high velocity and confidence. It combines a powerful and flexible pipeline management system with integrations from major cloud provider services like AWS EC2, Kubernetes, Google Compute Engine, Google Kubernetes Engine, Google App Engine, Microsoft Azure, OpenStack, Cloud Foundry, and Oracle Cloud Infrastructure.
It automates the releases by creating deployment pipelines, which run integration and system tests, spin up and down server groups, and monitor your rollouts. It triggers pipelines via Git events, Jenkins, Travis CI, Docker, CRON, or other Spinnaker pipelines.
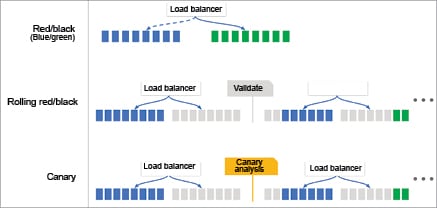
Spinnaker creates and deploys immutable images for faster rollouts, easier rollbacks and the elimination of hard-to-debug configuration drift issues. It leverages an immutable infrastructure in the cloud with built-in deployment strategies such as red/black and canary deployments.
Spinnaker’s application management feature helps you to manage the cloud resources. Spinnaker operates as a collection of services—sometimes referred to as applications or microservices. Applications, clusters and server groups are the key concepts Spinnaker uses to describe the services. Load balancers and firewalls describe how your services are exposed to users.
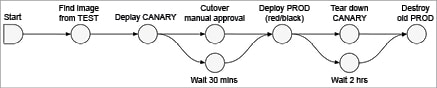
The Spinnaker pipeline is the key deployment management construct and it consists of a sequence of actions, known as stages. You can pass parameters from stage to stage along the pipeline (as shown in Figure 5). You can start a pipeline either manually or automatically trigger it by an event, such as the completion of a job, a new image appearing in your registry, a CRON schedule or a stage in another pipeline. You can configure the pipeline to give notifications by email, Slack, or SMS, to interested parties at various points during pipeline execution.
Spinnaker treats cloud-native deployment strategies as first-class constructs, handling the underlying orchestration such as verifying health checks, disabling old server groups and enabling new server groups. Spinnaker supports the red/black (a.k.a. blue/green) strategy, with rolling red/black and canary strategies in active development. Do refer to Figure 6 for the details















