





























































With billions of devices generating trillions of bytes of data, it is crucial for enterprises to be able to organise, store and work with all of it. In this context, databases play a crucial role. The important parameters for choosing the right database for IoT applications are scalability, availability, the ability to handle huge amounts of data, high processing speed and schema flexibility, integration with varied analytical tools, security, and costs.
The Internet of Things (IoT) refers to everyday objects that are readable, recognisable, locatable, addressable and/or controllable via the Internet, irrespective of the communication means — RFID, wireless LAN, wide area networks or any other.
With more physical objects and smart devices connected in the IoT landscape, the impact and value that IT brings to our daily lives becomes stronger. People can make better and more informed decisions when it comes to taking the best routes to work or choosing their favourite restaurants. New services can emerge to address societal challenges such as remote health monitoring for elderly patients.
For enterprises, IoT results in tangible business benefits because it leads to improved management and the tracking of assets and products, new business models, operational efficiencies, and cost savings due to the optimisation of equipment and resource usage.
According to Statista, the total installed base of IoT connected devices is projected to be 75.44 billion worldwide by 2025. With billions of devices generating trillions of bytes of data, it is crucial for enterprises to be able to organise, store and work with all the data that is generated.
In general, IoT applications leverage both types of databases, relational and non-relational. Non-relational databases are also called NoSQL. IoT requires the functions of both relational and NoSQL databases. The selection of the type of the database is done depending on the type of application. In most of the cases, a combination of both the databases is used.
Most IoT applications are heterogeneous and domain-centric. Choosing the most efficient database for an application can be challenging. The important parameters for choosing the right database for IoT application are scalability, availability, the ability to handle huge amounts of data, high processing speed and schema flexibility, integration with varied analytical tools, security and costs.
Gartner Inc. forecasts that by 2020, 20.8 billion connected devices will be in use. Ericsson has predicted that, by 2021, the number of mobile connections worldwide will reach 27.5 billion, including 15.7 billion IoT connections and 8.6 billion mobile phone connections.
Drivers for open source databases for IoT
Most IoT solutions are distributed across geographies. The solutions adopt fog computing at the edge and cloud computing at the enterprise levels. No single database product in the market can fulfil all the needs of the IoT database across the organisation. This calls for a collection of databases, potentially from a variety of vendors, used in one or more stages of the IoT implementation life cycle.
The key business drivers of open source database adoption are:
- The need for flexibility to process the data at the edge
- The need to synchronise the data between edge servers and the cloud
- Real-time data streaming and analytics
- Data filtering and aggregation
- The increasing cost of ownership in the database landscape
- Increased complexity when integrating and managing the databases for IoT solutions
- Multiple databases that duplicate functionalities, causing under-utilisation of the product
- Need for a wide range of skills to support the IoT landscape
Open source database selection for IoT implementation depends on the following requirements:
- The nature and type of data to be collected
- The business criticality of the data
- The importance of the chunk of data that will be collected
- High-availability and disaster recovery considerations for database processing
- How well the database addresses single point of failure
- Intensity of the data communication
- Integration with various other sources of data for analytics
Characteristics of open source databases
An IoT database should be fault-tolerant and highly available. It should have the following characteristics:
- There should be no vendor lock-in, to ensure seamless integration of enterprise wide tools, applications, products and systems developed/deployed by different organisations and vendors.
- An open source database increases productivity, speeds up time to market, reduces risks and improves quality.
- No vendor monopoly allows the use of free and open source databases. With data transferability and open data formats, there are greater opportunities to share data across interoperable platforms.
- The adoption of an open source database enhances the interoperability with other enterprise applications because of the reuse of recommended software stacks, libraries and components.
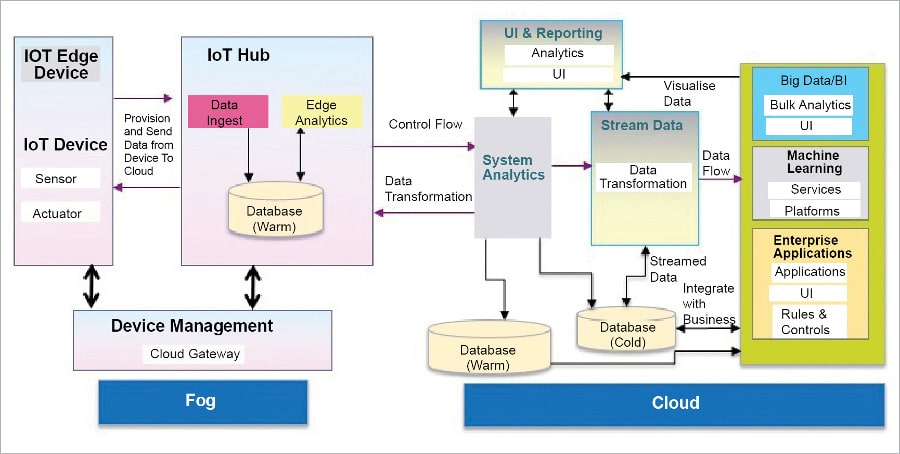
IoT architecture with databases
Thousands of sensors and actuators are connected with the edge server. The enterprise IoT solution collects data from all the devices continuously. Data ingestion helps to collect and store logs and messages from the devices.
The database needs to support high-speed write operations, and ensure that the data is captured and not lost under any circumstances. MQTT, Kafka and Rest Service components are used to ingest the data from the devices to the database. Edge analytics performs the translation, aggregation and filtering on the incoming data. This enables real-time decision making at the edge.
The database needs to support high-speed read and write operations with sub-millisecond latency. It helps in performing complex analytical computations on the data. The device manager communicates messages to the devices.
The database needs to access and deliver messages to the devices with minimum latency. The system analytics function collects the data from the edge server, and performs the data transformation and analytics operations. The database provides the commands to perform analytical computations on the data, and store the data for as long as required by the analytics engine.
IoT data streams convert the data to a common format and send it to enterprise systems. The database needs to perform the data transformation operations efficiently. The enterprise business intelligence (BI) function runs reports, queries and interfaces from historical data. The database needs to store data for a long period in a cost-effective manner. A warm database is a high-speed in-memory database that performs data read and write operations with the least latency. This database should be highly available and address disaster recovery requirements, providing real-time querying capabilities. A cold database is used to store the historical data of the IoT solutions. Typical databases could range from relational databases to a data lake.
Key open source databases for the IoT space
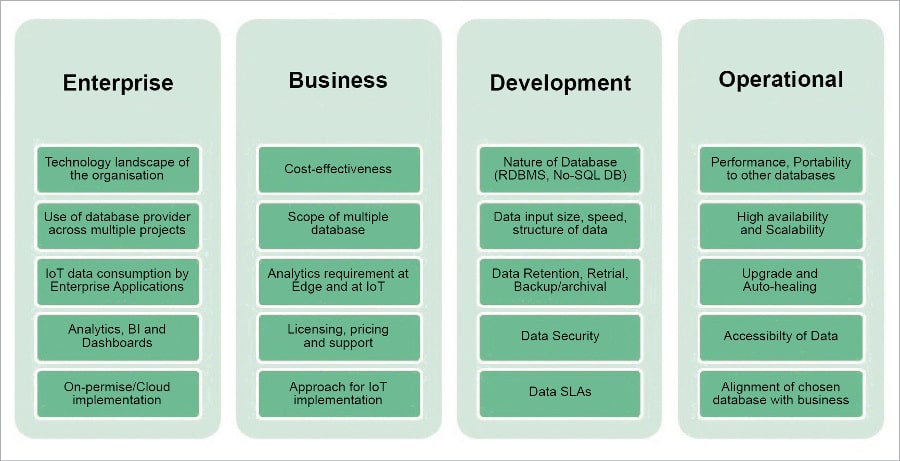
Every enterprise has a different business problem and IoT solutions can solve them in different ways, one of which is by growing a small setup to a large-scale implementation. The entire IoT implementation revolves around the idea of data collection/insertion through sensors and sending control back to devices. Selecting the right database for the various stages of IoT implementation in diverse use cases depends on multiple factors, as shown in Figure 2.
The following are some of the top open source databases available for IoT based applications.
MongoDB: This is a powerful and flexible open source database. It is a document-oriented and scalable NoSQL database. It supports features like indexes, range queries, sorting, aggregations and geospatial indexes. It also supports JSON to store and transmit information. MongoDB supports a rich query language for CRUD (create, read, update, delete) operations as well as data aggregation, text search and geospatial queries. As an example, Bosch has built its IoT suite on MongoDB.
InfluxDB: This is a time series database designed to handle high write and query loads. It provides an SQL-like query language called InfluxQL for interacting with data. InfluxDB has no external dependencies, and SQL-like queries are used for querying a data structure comprising measurements, series and points. Each point consists of varied key-value pairs called field set and timestamp. Values can be 64-bit integers, 64-bit floating points, strings and Booleans. Points are indexed by their time and tagset. InfluxDB stores data via HTTP, TCP and UDP. There is plugin support for other data ingestion protocols like Graphite, Collected, Open TSDB, etc.
BigchainDB: This is an embedded database for IoT devices. The assets created are stored as JSON documents in BigchainDB. It helps to convert physical objects into blockchain services by building blockchain-specific hardware that is compatible with any IoT device. It helps to define permissions for reading and writing rights into the IoT device. BigchainDB can be integrated with every IoT scenario where there is a requirement of immutability and tamper-proof storage of data assets, as well as the capability to search and query, along with high throughput.
MySQL: This is an open source relational database management system that brings data consistency, scalability, high performance, availability and flexibility to IoT solutions by efficiently collecting data from IoT devices. It helps in data transformation through annotation and aggregation, enabling data to be understood in a better way. Based on the IoT solution’s requirement, if the data format is fixed, then MySQL DB is the preferred choice.
GridDB: This is a container data model that extends the NoSQL key-value store. It represents data in the form of a collection referenced by keys. A transaction in GridDB guarantees ACID at the container level. It allows data to be present in two and three models. The two types of containers in GridDB are:
Collection container: This is a general purpose container.
TimeSeries container: This is data associated with a timestamp. It provides functions like data compression, data aggregation as well as high scalability, reliability and availability.
Redis: This is an in-memory open source database. It is a popular choice for IoT solutions as a hot database. It is widely used in IoT solutions for data ingest real-time analytics, messaging, caching and many other use cases. Today, it helps in edge computing involving deep learning, image recognition and other innovative computing requirements.
CrateDB: CrateDB is an open source distributed SQL database management system that fully integrates a searchable document-oriented data store. The CrateDB platform provides the distributed SQL query engine for faster joins, aggregations and ad-hoc queries. CrateDB is a highly scalable and available database. It supports various types of data.
Cassandra: This is a highly scalable and distributed open source database for managing voluminous amounts of structured data across many commodity servers. It provides availability, linear scale performance, simplicity and easy distribution of data across multiple database servers. It supports strong data consistency across distributed architectures.
Hadoop: This is an open source software platform for distributed storage and distributed processing of very large data sets on computer clusters built from commodity hardware. It helps in driving analytics from all IoT data. It easily ingests data from multiple data sources and supports both batch as well as real-time data ingest from sensors using tools such as Apache Kafka and Apache Flume. It handles multiple IoT data types, structures and schemas, supporting real-time processing and applications on streaming data. Hadoop is a flexible, scalable and secure database. A number of automotive manufacturers, utilities, industrial automation companies, insurers, healthcare organisations, telecom and technology leaders are adopting Hadoop.
Benefits of open source databases in IoT
Open source databases have the following advantages over proprietary databases:
- Easily upgradable to new technologies.
- Have the capability to connect with upcoming device protocols and backend applications.
- Open source database adoption implies lower overall software cost, ease of change in technology and open source APIs for integration.
- Open source databases provide the flexibility to change the architecture of those solutions that are microservices centred.
- Flexibility to change the cloud service provider.
In order to make the right choice, we must first analyse the business problem and then arrive at the solution. We can then break up the solution into services, and understand the database needs for these services. This will help an organisation to narrow down the database choices.
Most IoT solutions can depend on a hot database for real-time data collection, processing, messaging and analytics. And cold databases can be depended on to store historical data and gather business intelligence. This will make the architecture simple, lean and robust.














