



























































Subatomic and supersonic! When I first saw those words in the May 2019 issue of Open Source For You, I thought that they had something to do with Avenger’s Endgame spoilers. But on reading the article, I found that the words were applied to something even more interesting — Quarkus. Read on to learn more about it.
About two months back, Red Hat released Quarkus to get the developer community to rethink how Java can be best used to address a number of use cases. These include new deployment environments and application architectures like Kubernetes, microservices and serverless and cloud-native app development. The aim was to deliver higher levels of productivity and efficiency than the standard Java monolithic applications. According to Red Hat’s release notes: “Quarkus is a Kubernetes native Java framework tailored for GraalVM and HotSpot, crafted from best-of-breed Java libraries and standards. The goal of Quarkus is to make Java a leading platform in Kubernetes and serverless environments while offering developers a unified reactive and imperative programming model to optimally address a wider range of distributed application architectures.”
After reading a bit about Quarkus on its home page, I wanted to understand more about how it could totally change the way we package and deploy microservices. I decided to do a few experiments, to check how the three parameters change when a Java microservice is deployed using traditional openJDK vs Quarkus and GraalVM using containers. The results were unbelievable. We will go into that shortly, but before that, let me tell you more about GraalVM.


GraalVM
GraalVM is a high performance virtual machine that can run programs in different languages. Currently, it supports Java and other JVM languages like Scala, Kotlin, JavaScript, Python, Ruby and some native languages as well. For JVM languages, in particular, GraalVM offers a much faster runtime environment. You can learn more about it from the website https://www.graalvm.org/, but one of the limitations of GraalVM is that dynamic class loading is not supported. This means that deploying JARs, WARs, etc, in a container at runtime is impossible. Quarkus bridges that gap by providing a set of toolkits and frameworks for writing Java applications. It’s light, cloud-friendly, designed for GraalVM, and helps to overcome the limitations of the latter, including the one mentioned above.
Now let’s get to the experiments and results. On its blogs, Red Hat has often mentioned that Quarkus applications compile with GraalVM with tremendous memory utilisation and significantly low startup time, compared to traditional OpenJDK compilations and deployment. But I wanted to try it once to see how significant the difference was.
I started by bootstrapping a project and instead of the plain ‘Hello, world’ I had the GET service return a simple JSON using the Quarkus Extensions. Well, it does not actually matter how complicated the service is, but it feels good to have a real-life example of the services we deploy on a daily basis, rather than a plain ‘Hello, world’. Anyway, once I did that, I wanted to compare the numbers for the three parameters, mentioned in Figure 1, where the same service is deployed once using Quarkus native GraalVM, and again in the traditional OpenJDK way using the JVM. When Quarkus bootstraps a project, it also creates a Dockerfile.native to deploy the service using GraalVM.
The code of Dockerfile.native is shown below:
FROM registry.fedoraproject.org/fedora-minimalWORKDIR /work/COPY target/*-runner /work/applicationRUN chmod 775 /workEXPOSE 8080CMD [“./application”, “-Dquarkus.http.host=0.0.0.0”] |
I also created a simple Dockerfile to deploy the service the traditional way, as shown below:
FROM openjdk:8-jre-slimRUN mkdir /appCOPY target/lib /app/libCOPY target/*-runner.jar /app/application.jarEXPOSE 8080CMD [“java”, “-jar”, “/app/application.jar”] |
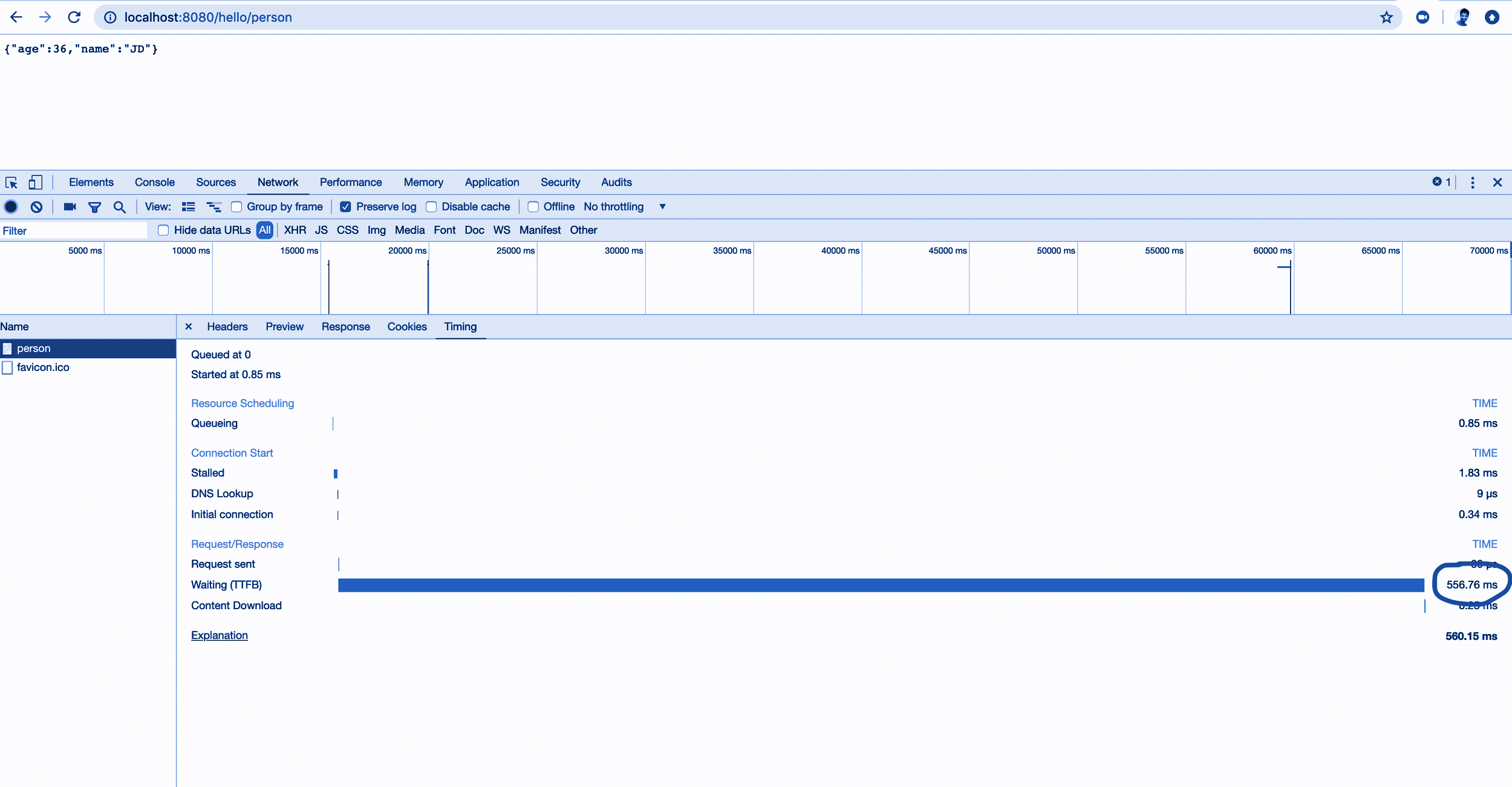
I first ran the traditional deployment and then ran Docker stats, which gave me the data about the CPU and memory utilisation, as shown in Figure 2.
As I hit the service http://localhost:8080/hello/person, I saw a peak in CPU usage of 1.82 per cent, which returned to 0.21 per cent after the request was served (Figure 3).
Then, using the Chrome developer tools, I collected the TTFB value as shown in Figure 4.
So the data collected for running the service deployed through the traditional JVM was as follows.
Memory usage: 64Mib
CPU usage: 0.21 per cent (on ideal state)
CPU usage: 1.82 per cent (on service hit)
TTFB: 557ms
Then I tried deploying the same service in native GraalVM, by running the Dockerfile.native created by bootstrapping Quarkus. Figure 5 shows the Docker stats as output.
On hitting the service http://localhost:8080/hello/person, the increase in CPU usage was 0.08 per cent, which was marginally less compared to the previous test. So was the TTFB collected by the Chrome dev tool (Figure 6).

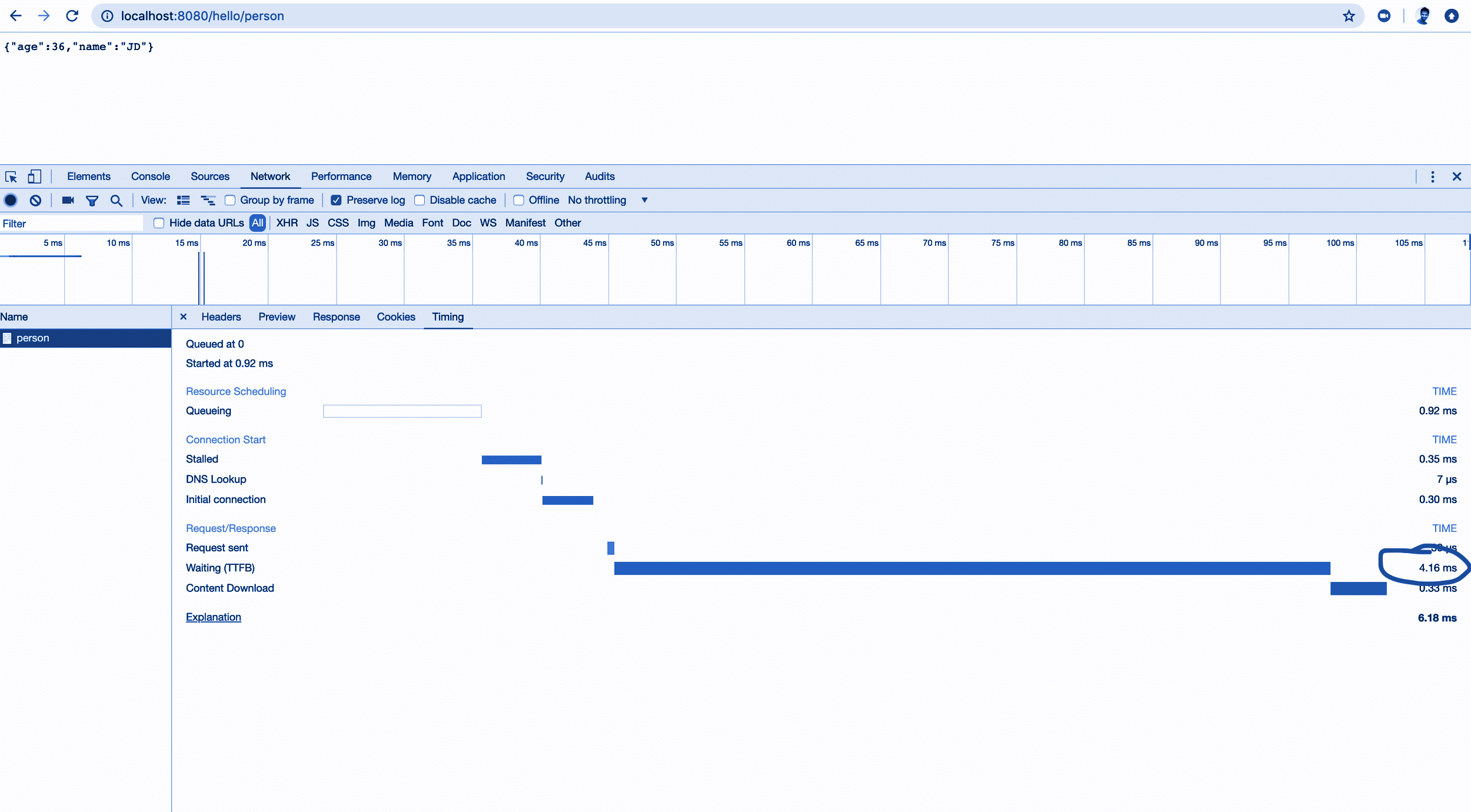

The TTFB was 4.16ms compared to 557ms, which was 98 per cent less than the last test.
The experiments I have shared are just a subset of the other scenarios I tested. But the last experiment is one of the most important, according to me, if we are going to try migrating our systems to Quarkus. It gave me a lot of confidence to migrate old applications running on traditional systems to Quarkus, and I am definitely going to give it a try. I also ran a load test to see how things hold under load. So far, I have only had great results with the metrics. Though there are a few different scenarios that I didn’t try, I believe that based on what was tested, the migration to Quarkus should definitely be tried, and great results can be accomplished by doing so.














