





























































This article gives the reader an insight into the Hyperledger Sawtooth architecture. It is targeted at open source technology enthusiasts who have an interest in blockchain technologies and a working knowledge of the Hyperledger Sawtooth project.
One goal of a distributed ledger like Sawtooth — indeed, its defining goal—is to distribute a ledger among participating nodes. The ability to ensure a consistent copy of data amongst nodes in the Byzantine consensus is one of the core strengths of blockchain technology. Sawtooth represents the state for all transaction families in a single instance of a Merkle-Radix tree on each validator. The process of block validation on each validator ensures that the same transactions result in the same state transitions, and that the resulting data is the same for all participants in the network.
Global state
The state is split into name spaces, which offer the flexibility to transaction family authors to define, share and reuse global state data between transaction processors. Sawtooth uses an addressable Merkle-Radix tree to store data for transaction families. Let’s break that down — the tree is a Merkle tree because it is a copy-on-write data structure, which stores successive node hashes from leaf-to-root upon any changes to the tree.
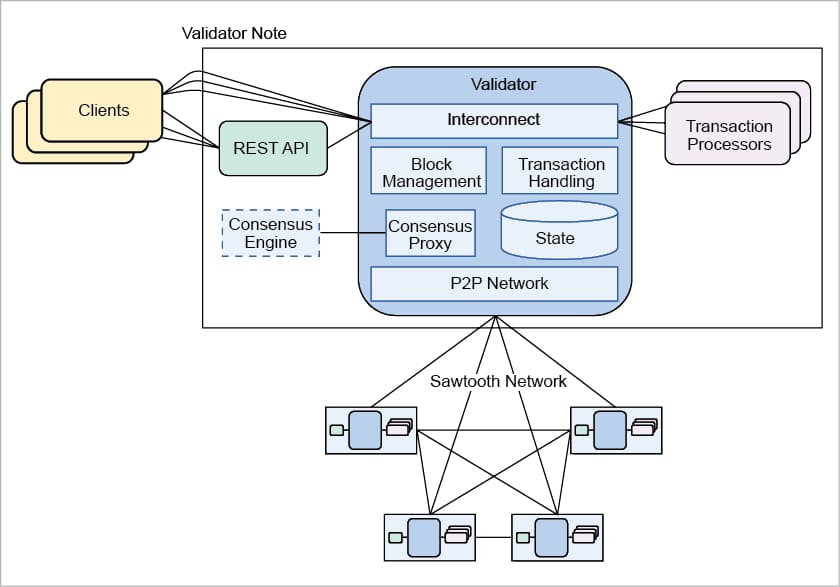
The tree is an addressable Radix tree, because addresses uniquely identify the paths to leaf nodes in the tree where information is stored. An address is a hex-encoded 70-character string representing 35 bytes. In the tree implementation, each byte is a Radix path segment, which identifies the next node in the path to the leaf containing the data associated with the address. The address format contains a 3-byte (6-hex character) name space prefix, which provides 224 (16,777,216) possible name spaces in a given instance of Sawtooth. The remaining 32 bytes (64 hex characters) are encoded based on the specifications of the designer of the name space, and may include schemes for sub-dividing further, distinguishing object types, and mapping domain-specific unique identifiers into portions of the address.
The journal
The journal is the group of validator components that work together to handle batches and proposed blocks. These components are responsible for completing published blocks, publishing batches into blocks to extend the chain, and validating proposed blocks to determine if they should be considered for the new chain head.
Blocks and batches arrive via interconnect, either through the gossip protocol or from client requests. The processing of these blocks and batches is handled in multiple pipelines.
The completer initially receives the blocks and batches. It guarantees that all dependencies for the blocks and batches have been satisfied. The completer is responsible for making sure that blocks and batches are complete before delivering them to the BlockPublisher or ChainController. It also checks for dependencies, ensures that the previous block exists, and makes sure that the batches exist in the BlockStore or BlockCache. All blocks and batches have a timeout for being completed. The completer sends an initial request for any missing dependencies or predecessors. If a response is not received in the specified time, the block or batch is dropped. For example, consider the case of a chain A->B->C. If Block C arrives but B is not in the BlockCache, the completer will request Block B. If the request for B times out, Block C is dropped.
The BlockPublisher is responsible for creating candidate blocks to extend the current chain. It does all the housekeeping work for creating a block, but takes direction from the consensus algorithm for when to create a block and when to publish a block-based response to the following events:
- Start block
- Receive batch
- Summarise block (stop and make the block available)
- Finalise block (publish the block)

The ChainController is responsible for maintaining the blockchain for the validator. This responsibility involves validating proposed blocks, evaluating valid blocks to determine if they should be considered for the new chain head, and generating new blocks to extend the chain. It determines which chain the validator is currently on and coordinates any change-of-chain activities that need to happen.The consensus interface is responsible for determining who can publish a block, whether a published block is valid according to the consensus rules, and which block should become the chain head in the case of a fork. Sawtooth also supports dynamic consensus. The initial consensus algorithm for the blockchain is set in the genesis block, but can be changed during a blockchain’s lifetime with the settings transaction processor.
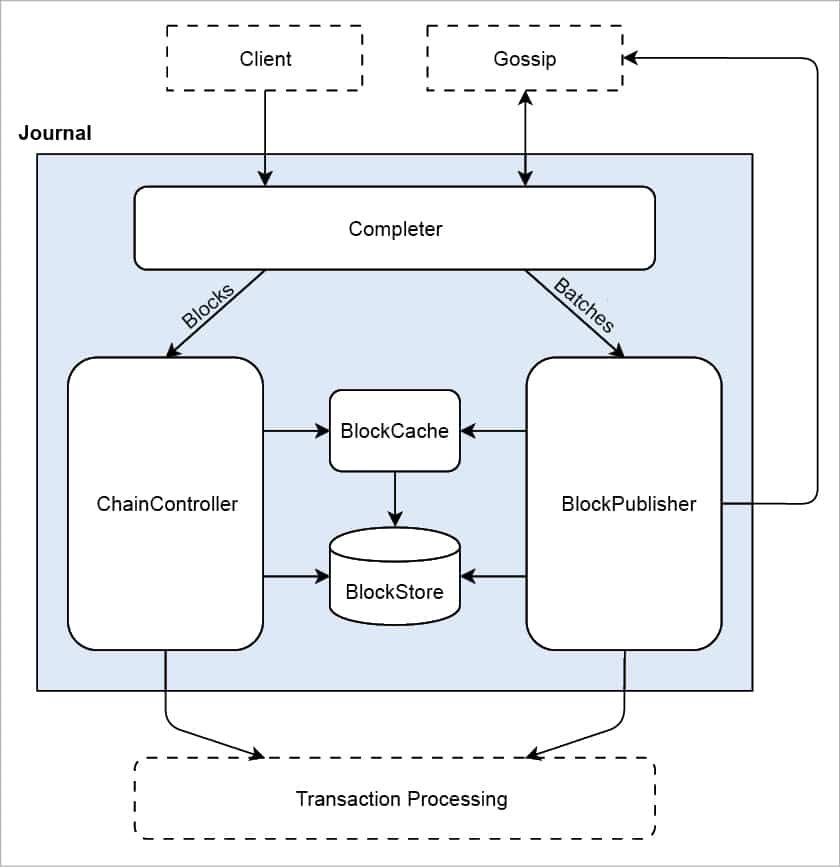
The BlockCache is an in-memory construct that is rebuilt when the system is started. It holds the working set of blocks for the validator. It tracks the processing state of each block as valid, invalid, or unknown.The BlockStore is a persistent on-disk store of all blocks in the current chain, i.e., the list of blocks from the current chain head back to the genesis block. When the validator is started, the contents of the BlockStore are trusted to be the current ‘state of the blockchain’ and the blocks are considered formally complete. It also internally maps transaction-to-block and batch-to-block. These mappings can be rebuilt if they are missing or corrupt. They are stored in a format that is cached to disk, so are not held in memory at all times. Blocks stored can be accessed by the block ID. Blocks can also be accessed via batch ID, transaction ID or the block number.














